Friendfeed (Photo credit: Wikipedia) Public Domain
Following on from (but unrelated to) my post last week about feed tools we have two posts, one from Deepak Singh, and one from Neil Saunders, both talking about ‘friend feeds’ or ‘lifestreams’. The idea here is of aggregating all the content you are generating (or is being generated about you?) into one place. There are a couple of these about but the main ones seem to be Friendfeed and Profiliac. See Deepaks’s post (or indeed his Friendfeed) for details of the conversations that can come out of these type of things.
Half the links in that quote are dead. I wrote the post above seven years ago today, and it very much marked a beginning. Friendfeed went on to become the coffee house for a broad community of people interested in Open Science and became the place where, for me at least, many of the key discussions took place. Friendfeed was one of a number of examples of “life feed” services. The original intent was as an aggregation point for your online activity but the feed itself rapidly became the focus. Facebook in particular owes a debt to the user experience of Friendfeed. Facebook bought Friendfeed for the team in 2009 and rapidly started incorporating its ideas.
Yesterday Facebook announced they were going to shutter the service that they have to be fair kept going for many years now with no revenue source and no doubt declining user numbers. Of course those communities that remained are precisely the ones that most loved what the service offered. The truly shocking thing is that although nothing has been done to the interface or services that Friendfeed offers for five years it still remains a best in class experience. Louis Gray had some thoughts on what was different about Friendfeed. It remains, in my view, the best technical solution and user experience for enabling the kind of sharing that researchers actually want to do. I remember reading about Robert Scoble disliked the way that Friendfeed worked, and thinking “all those things are a plus for researchers…”. Twitter is ok, Facebook really not up to the job, Figshare doesn’t have the social features and all the other “facebooks for science” simply don’t have critical mass. Of course, neither did Friendfeed once everyone left either…but while there was a big community there we had a glimpse of what might be possible.
It’s also a reminder, as discussed in the Principles for Scholarly Infrastructures that Geoff Bilder, Jennifer Lin and myself released a week or so back, that relying on the largesse of third parties is not a reliable foundation to build on. If we want to take care of our assets as a community, we need to take responsibility for them as well. In my view there is some important history buried in the records of Friendfeed and I’m going to make some effort to build an archive. This script appears to do a good job of grabbing public feeds. It doesn’t pull discussions (ie the comments on other people’s posts) unless you have the “remote key” for that account. If anyone wants to send me their remote key (log in to friendfeed and navigate to http://friendfeed.com/remotekey) I’ll take a shot at grabbing their discussions as well. Otherwise I’ll just try and prioritize the most important accounts from my perspective to archive.
Is it recent history or is it ancient? We lost Jean-Claude Bradley last year, one of the original thinkers, and perhaps more importantly do-ers, of many strands in Open Research. Much of his thinking from 2008-2011 was on Friendfeed. For me, it was the space in which the foundations for a lot of my current thinking was laid. And where I met many of the people who helped me lay those foundations. And a lot of my insights into how technology does and does not help communities were formed by watching how much better Friendfeed was than many other services. Frankly a lot of the half-baked crap out there today could learn a lot by looking at how this nearly decade-old website works. And still works for those communities that have stayed in strength.
But that is the second lesson. It is the combination of functionality and the community that makes the experience so rich. My community, the Open Science group, left en masse after Facebook acquired Friendfeed. That community no longer trusted that the service would stay around (c.f. again those principles on trust). The librarian community stayed and had an additional five years of rich interactions. It’s hardly new to say that you need both community and technology working together to build a successful social media experience. But it still makes me sad to see it play out like this. And sad that the technology that demonstrably had the best user experience for research and scholarship in small(ish) communities never achieved the critical mass that it needed to succeed.
Cite as “Bilder G, Lin J, Neylon C (2015) Principles for Open Scholarly Infrastructure-v1, retrieved [date], http://dx.doi.org/10.6084/m9.figshare.1314859“
UPDATE: This is the original blogpost from 2015 that introduced the Principles. You also have the option to cite or reference the Principles themselves as: Bilder G, Lin J, Neylon C (2020), The Principles of Open Scholarly Infrastructure, retrieved [date], https://doi.org/10.24343/C34W2H
infrastructure/ˈɪnfɹəˌstɹʌkt͡ʃɚ/ (noun) – the basic physical and organizational structures and facilities (e.g. buildings, roads, power supplies) needed for the operation of a society or enterprise. – New Oxford American Dictionary
Everything we have gained by opening content and data will be under threat if we allow the enclosure of scholarly infrastructures. We propose a set of principles by which Open Infrastructures to support the research community could be run and sustained. – Geoffrey Bilder, Jennifer Lin, Cameron Neylon
Over the past decade, we have made real progress to further ensure the availability of data that supports research claims. This work is far from complete. We believe that data about the research process itself deserves exactly the same level of respect and care. The scholarly community does not own or control most of this information. For example, we could have built or taken on the infrastructure to collect bibliographic data and citations but that task was left to private enterprise. Similarly, today the metadata generated in scholarly online discussions are increasingly held by private enterprises. They do not answer to any community board. They have no obligations to continue to provide services at their current rates, particularly when that rate is zero.
We do not contest the strengths of private enterprise: innovation and customer focus. There is a lot of exciting innovation in this space, much it coming from private, for profit interests, or public-private partnerships. Even publicly funded projects are under substantial pressures to show revenue opportunities. We believe we risk repeating the mistakes of the past, where a lack of community engagement lead to a lack of community control, and the locking up of community resources. In particular our view is that the underlying data that is generated by the actions of the research community should be a community resource – supporting informed decision making for the community as well as providing as base for private enterprise to provide value added services.
What should a shared infrastructure look like? Infrastructure at its best is invisible. We tend to only notice it when it fails. If successful, it is stable and sustainable. Above all, it is trusted and relied on by the broad community it serves. Trust must run strongly across each of the following areas: running the infrastructure (governance), funding it (sustainability), and preserving community ownership of it (insurance). In this spirit, we have drafted a set of design principles we think could support the creation of successful shared infrastructures.
Governance
If an infrastructure is successful and becomes critical to the community, we need to ensure it is not co-opted by particular interest groups. Similarly, we need to ensure that any organisation does not confuse serving itself with serving its stakeholders. How do we ensure that the system is run “humbly”, that it recognises it doesn’t have a right to exist beyond the support it provides for the community and that it plans accordingly? How do we ensure that the system remains responsive to the changing needs of the community?
Coverage across the research enterprise – it is increasingly clear that research transcends disciplines, geography, institutions and stakeholders. The infrastructure that supports it needs to do the same.
Stakeholder Governed – a board-governed organisation drawn from the stakeholder community builds more confidence that the organisation will take decisions driven by community consensus and consideration of different interests.
Non-discriminatory membership – we see the best option as an ‘opt-in’ approach with a principle of non-discrimination where any stakeholder group may express an interest and should be welcome. The process of representation in day to day governance must also be inclusive with governance that reflects the demographics of the membership.
Transparent operations – achieving trust in the selection of representatives to governance groups will be best achieved through transparent processes and operations in general (within the constraints of privacy laws).
Cannot lobby – the community, not infrastructure organizations, should collectively drive regulatory change. An infrastructure organisation’s role is to provide a base for others to work on and should depend on its community to support the creation of a legislative environment that affects it.
Living will – a powerful way to create trust is to publicly describe a plan addressing the condition under which an organisation would be wound down, how this would happen, and how any ongoing assets could be archived and preserved when passed to a successor organisation. Any such organisation would need to honour this same set of principles.
Formal incentives to fulfil mission & wind-down – infrastructures exist for a specific purpose and that purpose can be radically simplified or even rendered unnecessary by technological or social change. If it is possible the organisation (and staff) should have direct incentives to deliver on the mission and wind down.
Sustainability
Financial sustainability is a key element of creating trust. ‘Trust’ often elides multiple elements: intentions, resources and checks and balances. An organisation that is both well meaning and has the right expertise will still not be trusted if it does not have sustainable resources to execute its mission. How do we ensure that an organisation has the resources to meet its obligations?
Time-limited funds are used only for time-limited activities – day to day operations should be supported by day to day sustainable revenue sources. Grant dependency for funding operations makes them fragile and more easily distracted from building core infrastructure.
Goal to generate surplus – organisations which define sustainability based merely on recovering costs are brittle and stagnant. It is not enough to merely survive it has to be able to adapt and change. To weather economic, social and technological volatility, they need financial resources beyond immediate operating costs.
Goal to create contingency fund to support operations for 12 months – a high priority should be generating a contingency fund that can support a complete, orderly wind down (12 months in most cases). This fund should be separate from those allocated to covering operating risk and investment in development.
Mission-consistent revenue generation – potential revenue sources should be considered for consistency with the organisational mission and not run counter to the aims of the organisation. For instance…
Revenue based on services, not data – data related to the running of the research enterprise should be a community property. Appropriate revenue sources might include value-added services, consulting, API Service Level Agreements or membership fees.
Insurance
Even with the best possible governance structures, critical infrastructure can still be co-opted by a subset of stakeholders or simply drift away from the needs of the community. Long term trust requires the community to believe it retains control.
Here we can learn from Open Source practices. To ensure that the community can take control if necessary, the infrastructure must be ‘forkable’. The community could replicate the entire system if the organisation loses the support of stakeholders, despite all established checks and balances. Each crucial part then must be legally and technically capable of replication, including software systems and data.
Forking carries a high cost, and in practice this would always remain challenging. But the ability of the community to recreate the infrastructure will create confidence in the system. The possibility of forking prompts all players to work well together, spurring a virtuous cycle. Acts that reduce the feasibility of forking then are strong signals that concerns should be raised.
The following principles should ensure that, as a whole, the organisation in extremis is forkable:
Open source – All software required to run the infrastructure should be available under an open source license. This does not include other software that may be involved with running the organisation.
Open data (within constraints of privacy laws) – For an infrastructure to be forked it will be necessary to replicate all relevant data. The CC0 waiver is best practice in making data legally available. Privacy and data protection laws will limit the extent to which this is possible.
Available data (within constraints of privacy laws) – It is not enough that the data be made ‘open’ if there is not a practical way to actually obtain it. Underlying data should be made easily available via periodic data dumps.
Patent non-assertion – The organisation should commit to a patent non-assertion covenant. The organisation may obtain patents to protect its own operations, but not use them to prevent the community from replicating the infrastructure.
Implementation
Principles are all very well but it all boils down to how they are implemented. What would an organisation actually look like if run on these principles? Currently, the most obvious business model is a board-governed, not-for-profit membership organisation, but other models should be explored. The process by which a governing group is established and refreshed would need careful consideration and community engagement. As would appropriate revenue models and options for implementing a living will.
Many of the consequences of these principles are obvious. One which is less obvious is that the need for forkability implies centralization of control. We often reflexively argue for federation in situations like this because a single centralised point of failure is dangerous. But in our experience federation begets centralisation. The web is federated, yet a small number of companies (e.g., Google, Facebook, Amazon) control discoverability; the published literature is federated yet two organisations control the citation graph (Thomson Reuters and Elsevier via Scopus). In these cases, federation did not prevent centralisation and control. And historically, this has occurred outside of stewardship to the community. For example, Google Scholar is a widely used infrastructure service with no responsibility to the community. Its revenue model and sustainability are opaque.
Centralization can be hugely advantageous though – a single point of failure can also mean there is a single point for repair. If we tackle the question of trust head on instead of using federation as a way to avoid the question of who can be trusted, we should not need to federate for merely political reasons. We will be able to build accountable and trusted organisations that manage this centralization responsibly.
Is there any existing infrastructure organisation that satisfies our principles? ORCID probably comes the closest, which is not a surprise as our conversation and these principles had their genesis in the community concerns and discussions that led to its creation. The ORCID principles represented the first attempt to address the issue of community trust which have developed in our conversations since to include additional issues. Other instructive examples that provide direction include Wikimedia Foundation and CERN.
Ultimately the question we are trying to resolve is how do we build organizations that communities trust and rely on to deliver critical infrastructures. Too often in the past we have used technical approaches, such as federation, to combat the fear that a system can be co-opted or controlled by unaccountable parties. Instead we need to consider how the community can create accountable and trustworthy organisations. Trust is built on three pillars: good governance (and therefore good intentions), capacity and resources (sustainability), and believable insurance mechanisms for when something goes wrong. These principles are an attempt to set out how these three pillars can be consistently addressed.
The challenge of course lies in implementation. We have not addressed the question of how the community can determine when a service has become important enough to be regarded as infrastructure nor how to transition such a service to community governance. If we can answer that question the community must take the responsibility to make that decision. We therefore solicit your critique and comments on this draft list of principles. We hope to provoke discussion across the scholarly ecosystem from researchers to publishers, funders, research institutions and technology providers and will follow up with a further series of posts where we explore these principles in more detail.
The authors are writing in a personal capacity. None of the above should be taken as the view or position of any of our respective employers or other organisations.
The play Arcadia by Tom Stoppard‘s links entropy and chaos theory, the history of english landscape gardens, romantic literature and idiocies of academia. I’ve always thought of it as Stoppard’s most successful “clever” play, the one that best combines the disparate material he is bringing together into a coherent whole. Rosencrantz and Guildernstern are Dead feels more straightforward, more accessible, although I don’t doubt that many will feel that’s because I’m missing its depths.
In the Theatre Royal Brighton/English Touring Theatre production that just closed at the Theatre Royal in Bath the part of Thomasina was played by Dakota Blue Richards, Septimus by Wilf Scolding, Bernard by Robert Cavanah, Hannah by Flora Montgomery and Valentine by Ed McArthur. To be up front I found the production disappointing, probably not helped by our seats up in the gods. Richards and Scolding were excellent as tutor and tutee, each learning from the other but I found Cavanah and Montgomery’s competitive academics to both be thin, even shrill. The caricature in the parts of Bernard and Hannah are easy, making their motivations human – while also ensuring that their verbal sparring is intelligible – a greater challenge where I felt that they fell short.
And it was in that execution of dialogue that the production seemed to fall flat. Arcadia depends on dialogue and ideas that run through two time periods, on believing that we understand the jokes shared between characters, but above all on the audience connecting the threads so that all the pieces fall into place. Despite a constant stream of references that will only make sense to those familar with thermodynamics, or landscape history or romantic poetry the play itself is self contained. All the clues that are needed to knit the many threads together can be found in the script. But the delivery is critical. The timing crucial. Every word needs to be pointed and natural and timed perfectly or the connections are lost. The responsibility lies with the audience to hold those threads and weave them together, but they depend on a faultless ensemble to make this work.
But is it fair to expect an audience to hold in their heads a comment from Act 1 that is only answered in passing an hour or more later in Act 2? How much can the playwright expect the audience to hold? Certainly the audience in Bath seemed to struggle. An audience member who knows enough about thermodynamics and romantic poets and English landscape gardening has an advantage over one who does not. Simply that there is less that needs to be held onto to follow the threads. Experts have a distinct advantage in parsing the play.
It was Michael Nielsen who most clearly articulated the idea that the most valuable resource we have in the research enterprise (or in many places) is the attention of experts.  And those who have internalized an understanding of an area to the extent that problem solving is intuitive are the most valuable. But we at the same time value the serendipitous, the sense of being open to the surprising insight. Valentine, the PhD scholar working on understanding population dynamics of grouse in the modern half of the story is unable to see that Thomasina had recognized the path to modern thermodynamics years earlier than thought. His character is painted as limited in that respect until he can see it. The modern academics are similar painted as only open to the surprises they are seeking. Thomasina’s tutor, Septimus is perhaps of a similar age to Valentine but by contrast is painted as open to idea that his 16 year old charge is capable of such insight.
If fortune favours a prepared mind, then that mind is expensive and time consuming to prepare. So we protect them, and lock them up inside institutions so as to ensure only the relevant demands are made on their time. But if the provocations, the serendipities, come from outside established grounds then, to invert the question I posed of the playwright, what can we reasonably expect of the expert in dedicating time to being open? Or is there a level beyond mastery in Dreyfus’ hierarchy of skill acquisition, where the expert cannot just examine their own practice, but simultaneously be open to outside influence. Does it need to be “or” or can it be “and”? Can we not just ride a bike without thinking about it, but ride a bike while thinking about how we do it.
What we may reasonably expect of the playwright in guiding us, what they may reasonably expect of their audience; what we may reasonably expect of the expert and what they may expect of us as we approach them, are connected by a sense of the contract we implicitly form, the audience with the playwright, publics with the expert. Different pieces of theatre require differing levels of commitment from the audience, with expectations set by forms, venues, even ticket prices. It is plausible to argue that commodification of theatre into mass market entertainment necessarily lowers that level of commitment as it must work for a larger audience. It might conversely be argued that the commitment required to understanding American Football or rugby (or cricket!) is as great as that required to engage with Stoppard or Mozart.
In the realm of the academic expert these questions cut to the heart of what the research establishment is for. And are we delivering on that. Stoppard answers this question with three self-obsessed roles; one hardened by the toxic combination of imposter syndrome and arrogance that many in academia will recognise; one partway through that process, perhaps redeemable, perhaps not likely where she sees herself heading, but nonetheless ready to both rise to the bait and to patronise the third; the academic in formation. Yet it is Valentine, the PhD student who when asked “And then what” gives the answer that speaks most directly to academic sensibilities, “I publish”. There is no explicit stage direction but, given this is said to Hannah, the middle of our three academics the line clearly needs to be delivered with the sense of “well d’uh…”.
Yet Stoppard makes his academics figures of fun with their obsessions with prestige rather than engagement, how is this to be reconciled with his own demands on the audience? In truth the there is a deeper message. The puzzle for the modern protagonists can only be solved by bringing their differing expertises together. Bernard uncovers the trail and knows the problem is of interest, but it is Hannah’s expertise on the garden and its plant that reveals that Bernard is only partly right. It is Valentine who has the evidence that Byron visited Sidley House, but Hannah who pushes him to understand the depth of Thomasina’s work. Hannah in turn needs Valentine to uncover the identity of the hermit and what he was doing.
On the earlier timeline it is Thomasina who has the insight, but even her genius is limited. She laments her inability to fully work out the implications saying “I cannot. I do not know the mathematics”. It is made clear to us that her tutor does “Let [the Germans] have the waltz they cannot have the calculus.” making his working through of Thomasina’s ideas plausible. Stoppard throughout presents with exactly the serendipitous connections (and misconnections) that require an open mind to see, identify and integrate into an expert model. It is the arrogance and lack of confidence of the modern characters that prevents them working together to solve the puzzle much quicker (albeit with less drama). By contrast greater openness of the Cambridge educated Septimus to the possibility that Thomasina’s insight is greater than his provides many of the most sympathetic moments in the play.
Of course Stoppard is cheating. He has a static construct in which to lay his threads, ready to catch the prepared mind of the audience. The answer is known and the final curtain set. At the same time he plots jokes and asides throughout. His real genius is in setting these up so that as long as you know something of gardens, or thermodynamics, or academic life, or Byron, or chaos theory, or shooting, or the English aristocracy. You don’t need to know all of these, but knowing one will enrich the experience. Of course the challenge for the players is to be aware of all of these threads as well as those that make up the surface narrative. In Bath, my implicit stage direction above was missing.
In the end Stoppard does make serious demands, and repays repeated engagement with the text. But those demands are not of expertise. If the answer he poses to my question is that experts will gain more by working together and being open to each other’s expertise, what he demands of the audience is simply to be open and attentive. In the end perhaps that is the answer to the question of the reasonable expectations of expertise in the academy. Not to be prescriptive about when and how an expert focuses, or opens up, or whether they need to achieve a level of mastery that allows them to do both, but simply to be attentive. To continuously absorb, remember, compare and contrast. To value mastery as a tool, but not as the answer in its own right.
That is the mistake that the modern characters make in the play. In the best productions you understand both how Bernard, Hannah and Valentine have arrived where they are, but also that they don’t very much like what they see in the mirror. That they, like many academics, are constantly seeking an escape from the pursuit of prestige and publication that they have locked themselves into. That they have been trapped into a cycle where they are required to demonstrate mastery but not necessarily apply it, and certainly not build on it. The aim for all three is publication, not understanding.
Breaking out of these cycles is hard. But in the end if Stoppard is calling us to pay attention, to be engaged enough to not just see the threads, but to hold them and weave them together, that might be enough to make a start.
Mathematics in a PhD thesis. (Photo credit: Wikipedia)
There’s an argument I often hear that brings me up short. Not so much short because I don’t have an answer but because I haven’t managed to wrap my head around where it comes from. It generally comes in one of two forms, either “You can’t possibly understand our world because you’re not an X†(where X is either “humanistâ€, “creative†or “social scientistâ€) or its close variant “You can’t possibly understand…because you’re a scientistâ€.
There are a couple of reasons why this is odd to me. The first is a surface one. I’ve spent more time reading Foucault and Ostrom recently than Fire or Tsien. Of the projects I’ve been involved with recently more of them could be described as humanities (digital or otherwise) or economics than science. There has been more Marxist historical theory and discourse analysis than laboratory experiments in my life over the past few years.
But that, as I say, is a surface issue. I can’t claim to be an expert in the process or methodology of any of these disciplines. The deeper issue is with the assumption that I am “a scientistâ€. Because by any measure that my old colleagues would apply I don’t qualify as one of those either. Indeed by their standards I’ve completely flunked out. So if I were to define myself by what others allow me to be, I am not allowed to be anything at all. I apparently don’t exist.
This is a problem familiar to researchers carving out new disciplines or new approaches. The power politics of disciplines are exclusionary by design. The right to be listened to is supposed to be earn by demonstrating expertise through specific apprenticeship pieces – the PhD thesis most obviously – but as a researcher advances there are also the journeyman works; in the humanities the first monograph, in the sciences a sufficient body of research articles, first as lead researcher, then as principal investigator. Those pieces only count if they appear in the right places, approved by the right authorities.
I’ve deliberately used the pejorative term “exclusion†here but the motivations need not be malicious. Exclusion is a mechanism for protecting the time of experts – ensuring that their attention is focussed on worthwhile and relevant material. When (if) it is functioning well, the system allows meritocratic inclusion in the club to be earned through demonstrating expertise. If instead of “exclusion†we use the less judgemental word “filtering†then we can ask the right questions – is the filter working properly? What is the rate of false positives and of false negatives? Can that be improved? And what would that cost, in time if not in money?
It is the question of false negatives in our filters that should give us pause. The problem is that the politics of our filters are inextricably bound up with the politics of our communities. We define our communities via shared practice and values, and disciplinary communities are no different. We exclude those who don’t share our practices and values. And this occurs in a fractal manner – the humanities can be defined by their differences to the sciences, the historians by the way they differ to economists, the historiographers by differences to the theorists, the Marxists to the Feminists and so on and so forth. Our disciplinary identities are tightly bound up in the way we exclude those we perceive as different. And our modes and media of communication tend to highlight those differences so we know who to (bother to) read.
And yet…
I think the differences are basically bogus. There are differences in scholarly practice, differences in the models used, indeed differences in what we mean when we use the word “modelâ€. These in turn are reflected in the different frameworks and assumptions that those models and practices are built from. But all of these support the same basic human activity of sense-making, of organising our understanding of the world around us. There are human, social and political reasons for us to organise and self-identify around the different tactical approaches to doing this but the underlying purpose and motivation of the activities are very similar. The social systems that create motivation to engage in these activities, through assignment of prestige and power, emphasise those differences even though the human processes through which they are assigned are remarkably similar.
The communication of scholarship is often used as the fulcrum of arguments for defining disciplinary difference. The way in which the business models for monographs necessarily differ from those for journals and the tradition of long form vs short form writing (a subject worth of some revisionist historical study of its own) is conflated with a perception that the actual motivations and structure of communication differs between disciplines.
It has become reflexive in debates on Open Access in the humanities to assert that the mode of communication in humanities is qualitatively different from that in the sciences. Debates around licensing revolve around the importance of the language itself to humanists, contrasting this with the imagined objectivity or data dependence of scientific communication. Claims are made that in the humanities the writing is the scholarship. Of course, these claims commit exactly the same sin that I am accused of above, but more ironically they represent a failure to apply rigorous standards of humanist (or at least historico-literary) analysis to scientific and humanist discourse.
The communication can never be more than a representation of the scholarship. Whether in Buckheit and Donoho’s critique that the article is “merely advertising of the scholarshipâ€, in Pettifer et al’s argument from surrealist painting that differing article formats are the representations of the work, that “ceci n’est pas un hamburgerâ€, or in O’Leary’s manifesto that “context trumps content†we understand two things. First that communication can only ever be a representation of an internal mind state in the process of sense-making. Second that, because communication involves an attempt to externalise that internal mind state, it is subject to interpretation – that the context of the receiver is matters. The author is always held hostage by the reader.
The structure of scholarly communication
We have sought in the past to make that context as predictable as possible by creating disciplinary boundaries that exclude those that don’t share our expectations. But despite this balkanisation of context the structure of scholarly communications remains remarkably consistent across disciplines. Anita de Waard has described bioscience articles as “stories that persuade with data†and she draws on the strong structural alignment between those research articles and fairy tales when she does so. If the structures are consistent from children’s stories to crystallography, are they really so different between history and chemistry?
In fact all scholarly literature appears to fit a similar mould; stories that persuade by placing evidence in a context. The rhetorical structure of both books and articles is built on introductions that provide context, a journey through which evidence is presented and the conclusion in which the argument is brought together. We don’t adopt this structure because it is the only one possible (it isn’t) or because it is “obvious†in some way (it’s not from a de novo structural perspective) but because as humans we communicate through stories.
The way we create context, the standards of what is acceptable evidence and the ways in which that evidence is marshalled, analysed and integrated differ according to disciplinary practice. But at core we all seek to persuade. The grammars may differ – in extremis ranging from a grammar of data presentation to the grammar of English language – but rhetoric has an important role to play throughout. Assuming that science communication is somehow “objective†and independent of the structure and persuasiveness of the argumentation is as naive as suggesting that humanities discourse is “just someone waffling onâ€.
The challenges, and the opportunities, of shaking those arguments up – of seeing them in new contexts and new juxtapositions – are precisely the same in my view. Breaking the existing grammars down to see how new creoles or pidgins might form necessarily involves breaking down the monolithic integrity of the original argument. But I would argue that integrity is broken down anyway. The moment that the words, or the data, are put down the context has changed and the author is at the mercy of the reader. There are risks here – risks of mistaking context and of misrepresentation but to me these are the risks inherent in communication itself.
Positive filtering rather than negative
In the end this is a question of risk assessment. There is always risk in communication and choosing to communicate more openly arguably involves greater risk. As humans we have a tendency to overplay risks and underplay the potential opportunities in any assessment and as scholars we are no different. In the end the only way of ensuring absolute control over the risk of misinterpretation and misrepresentation is to not communicate at all. Scholarship has the risks of communication at its heart. Indeed a scientist might suggest that conceptual mutation and evolution is a positive opportunity for scholarship. Is peer review not a form of selection under variation – the usefulness, persuasiveness or power of the idea or claim after it is mutated through the perceptions and context of the reviewer?
The selection for dissemination of our traditional models of peer review are a particular type of filter. They act on the output side and they are negative in the sense that they exclude works from dissemination. But the filters that we apply, the choices we make in our mode and medium of communication, act in both directions. If we choose to only interact with peer reviewed literature we are applying a different kind of filter, still negative, still exclusive. Similarly if we choose to only react with certain journals, or the outputs of our own discipline, or the outputs of those people who belong to our discipline, then we are applying negative filters of subtly different types.
Negative or exclusive filters are important when selecting physical or rivalrous goods. Only so many articles can fit in the pages allowed, only so many books can fit on the truck. In the digital world many of these restrictions disappear. The restriction that remains is the limitation of the researcher’s time or attention. It is not that we do not need filters, but that the online world gives us an opportunity to build differing filters, positive filters, filters that enrich, instead of filters that exclude. For me this is a great opportunity for scholarship because it is the surprises, the new insights, and the new connections that arise when we lift our eyes beyond our narrow disciplinary scope that create value.
Who am I really?
Some might argue that idea that conceptual mutation can be a positive for scholarship could only have come from someone with a background in science. Perhaps even only from someone with an interest in evolution. But is not critical theory essentially based on the same perspective? That only through seeking to understand an author’s context through the choice of language, can you fully understand their true meaning – and that the meaning may be adjacent or even opposed to what the author might claim. Indeed the “science wars†are rooted in the relativist and contextual claims of humanists and social scientists tackling the discourse of the natural sciences. Are based in a decontextualisation of scientific discourse that is arguably the same in form to that feared by some humanists.
I have recently come to realise that, for whatever reason, I have a greater sympathy for positive filters than our traditional negative filters. My best work, whether in my formal research career in the sciences or my more fuzzy “scholarship†as an advocate has been in the interstices. I constantly seek differing perspectives, new places to stand to view problems. Perhaps my single most important piece of research work arose when our team took a wholly naive, but as it turned out very helpful, new approach to tackling issues in DNA sequencing. I used to describe my research as lying in “the black hole between physics, chemistry and biologyâ€. And now I read Ostrom and Foucault and Boyd and Fitzpatrick in an attempt to understand how we might build new communities to support scholarly discourse.
Adopting, even co-opting, different perspectives to look at a problem is what I do. A cynic might say that’s because its easy. Co-opting a new set of tools to look at an problem means not needing to dig too deep because it is easy to look at the newly revealed surface. It’s not an unreasonable criticism. But as I’ve become interested in tackling larger and more challenging problems it has also become obvious that new perspectives are needed.
This kind of approach needs positive, enriching filters, not negative ones, because by excluding certain streams you eliminate the unfamiliar perspectives. This is why being rejected because I am “a scientist†generally stops me cold. It is a rejection of perspective, a rejection in my world view of an opportunity. It is bound up in a self identify of difference that uses difference as a way to filter and exclude – something that for me is in opposition to the scholarship that is of most interest.
The right to speak is not the right to be listened to. The filters matter and the time of the expert is valuable. Part of expertise is exactly the skill in making the choice of how to filter. Nor am I so naive that I do not seek out the media and spaces where particular communities are more likely to be listening, even perhaps in the future seek the traditional kinds of validation and certification that encourage those communities to take an interest in what I have to say.
Yet at the same time I feel that we lose opportunities. Michael Crow, President of Arizona State University asked a question at the Berlin9 Conference in Bethesda that has stayed with me ever since. He asked what it would mean if a university was defined not by how exclusive it was, but by how inclusive it was. Almost all scholarly practice is defined by exclusivity and prestige, by engaging only with those certified and approved. It is defined by the disciplinary boundaries that we erect to contain and exclude those who use different tools and methods. And yet all scholarship is simply a human activity of sense making, discovery and communication.
I am whoever I want to be. You don’t get to define my value. The real question is whether the filters you apply are good enough to tell when I have something to say that is useful for you to hear. What opportunities arise if we can focus not on the differences between disciplines but on the common practice? What if in that focus we could identify where the opportunities for cross-fertilisation lie? What would a scholarship based on inclusion look like?
For my holiday project I’m reading through my old blog posts and trying to track the conversations that they were part of. What is shocking, but not surprising with a little thought, is how many of my current ideas seem to spring into being almost whole in single posts. And just how old some of those posts are. At the some time there is plenty of misunderstanding and rank naivety in there as well.
The period from 2007-10 was clearly productive and febrile. The links out from my posts point to a distributed conversation that is to be honest still a lot more sophisticated than much current online discussion on scholarly communications. Yet at the same time that fabric is wearing thin. Broken links abound, both internal from when I moved my own hosting and external. Neil Saunders’ posts are all still accessible, but Deepak Singh’s seem to require a trip to the Internet Archive. The biggest single loss, though occurs through the adoption of Friendfeed in mid-2008 by our small community. Some links to discussions resolve, some discussions of discussions survive as posts but whole chunks of the record of those conversations – about researcher IDs, peer review, and incentives and credit appear to have disappeared.
As I dig deeper through those conversations it looks like much of it can be extracted from the Internet Archive, but it takes time. Time is a theme that runs through posts starting in 2009 as the “real time web” started becoming a mainstream thing, resurfaced in 2011 and continues to bother. Time also surfaces as a cycle. Comments on peer review from 2011 still seem apposite and themes of feeds, aggregations and social data continue to emerge over time. On the other hand, while much of my recounting of conversations about Researcher IDs in 2009 will look familiar to those who struggled with getting ORCID up and running, a lot of the technology ideas were…well probably best left in same place as my enthusiasm for Google Wave. And my concerns about the involvement of Crossref in Researcher IDs is ironic given I now sit on their board as second representing PLOS.
The theme that travels throughout the whole seven-ish years is that of incentives. Technical incentives, the idea that recording research should be a byproduct of what the researcher is doing anyway and ease of use (often as rants about institutional repositories) appear often. But the core is the question of incentives for researchers to adopt open practice, issues of “credit” and how it might be given as well as the challenges that involves, but also of exchange systems that might turn “credit” into something real and meaningful. Whether that was to be real money wasn’t clear at the time. The concerns with real money come later as this open letter to David Willets suggests a year before the Finch review. Posts from 2010 on frequently mention the UK’s research funding crisis and in retrospect that crisis is the crucible that formed my views on impact and re-use as well as how new metrics might support incentives that encourage re-use.
The themes are the same, the needs have not changes so much and many of the possibilities remain unproven and unrealised. At the same time the technology has marched on, making much of what was hard easy, or even trivial. What remains true is that the real value was created in conversations, arguments and disagreements, reconciliations and consensus. The value remains where it has always been – in a well crafted network of constructive critics and in a commitment to engage in the construction and care of those networks.
Many efforts at building data infrastructures for the “average researcher” have been funded, designed and in some cases even built. Most of them have limited success. Part of the problem has always been building systems that solve problems that the “average researcher” doesn’t know that they have. Issues of curation and metadata are so far beyond the day to day issues that an experimental researcher is focussed on as to be incomprehensible. We clearly need better tools, but they need to be built to deal with the problems that researchers face. This post is my current thinking on a proposal to create a solution that directly faces the researcher, but offers the opportunity to address the broader needs of the community. What is more it is designed to allow that average researcher to gradually realise the potential of better practice and to create interfaces that will allow technical systems to build out better systems.
Solve the immediate problem – better backups
The average experimental lab consists of lab benches where “wet work” is done and instruments that are run off computers. Sometimes the instruments are in different rooms, sometimes they are shared. Sometimes they are connected to networks and backed up, often they are not. There is a general pattern of work – samples are created through some form of physical manipulation and then placed into instruments which generate digital data. That data is generally stored on a local hard disk. This is by no means comprehensive but it captures a large proportion of a lot of the work.
The problem a data manager or curator sees here is one of cataloguing the data created, creating a schema that represents where it came from and what it is. We build ontologies and data models and repositories to support them to solve the problem of how all these digital objects relate to each other.
The problem a researcher sees is that the data isn’t backed up. More than that, its hard to back up because institutional systems and charges make it hard to use the central provision (“it doesn’t fit our unique workflows/datatypes”) and block what appears to be the easiest solution (“why won’t central IT just let me buy a bunch of hard drives and keep them in my office?”). An additional problem is data transfer – the researcher wants the data in the right place, a problem generally solved with a USB drive. Networks are often flakey, or not under the control of the researcher so they use what is to hand to transfer data from instrument to their working computer.
The challenge therefore is to build systems under group/researcher control that the needs for backup and easy file transfer. At the same time they should at least start to solve the metadata capture problem and satisfy the requirements of institutional IT providers.
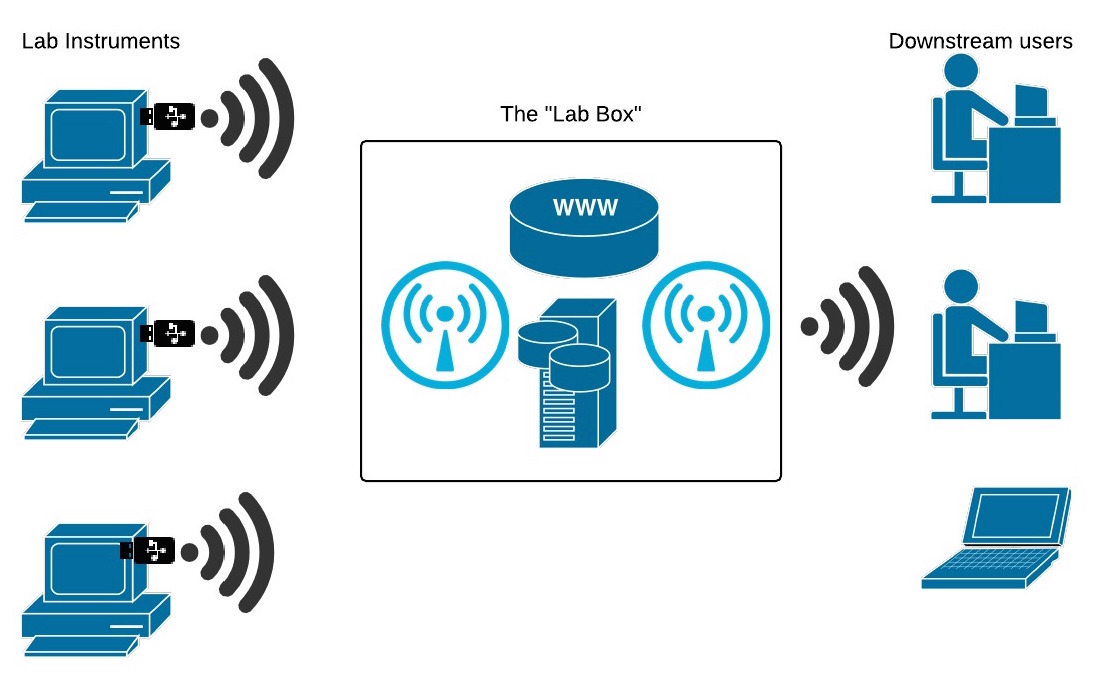
The Lab Box
The PI wants to know that data is being collected, backed up and is findable. They generally want this to be local. Just as researchers still like PDFs because they can keep them locally, researchers are happiest if data is on a drive they can physically locate and control. The PI does not trust their research group to manage these backups – but central provision doesn’t serve their needs. The ideal is a local system under their control that automates data backups from the relevant control computers.
The obvious solution is a substantial hard drive with some form of simple server that “magically” sucks data up from the relevant computers. In the best case scenario appropriate drives on the instrument computers are accessible on a local network. In practice life is rarely this simple and individually creating appropriate folder permissions to allow backups is enough of a problem that it rarely gets done. One alternate solution is to use the USB drive approach – add an appropriate USB fob to the instrument computer that grabs relevant data and transmits it to the server, probably over a dedicated WiFi network. There are a bunch of security issues on how best to design this but one option is a combined drive/Wifi fob where data can be stored and then transmitted to the server.
Once on the server the data can be accessed and if necessary access controls applied. The server system need not be complex but it probably does at least need to be on the local network. This would require some support from institutional IT. Alternately a separate WiFi network could be run, isolating the system entirely from both the web and the local network.
The data directory of instrument computers if replicated to a server via a private WiFi network. The server then provides access to those files through a web interface.
Collecting Metadata
The beauty of capturing data files at the source is that a lot of metadata can be captured automatically. The core metadata of relevance is “What”, “Who”, and “When”. What kind of data has been collected, who was the researcher who collected it and when was it collected. For the primary researcher use cases (finding data after the student has left, recovering lost data, finding your own data six months later) this metadata is sufficient. The What is easily dealt with as is the When. We can collect the original source location of the data (and that tells us what instrument it came from) and the original file creation date. While these are not up to standards of data curators who might want a structured description of what the data is it is enough for the user, it provides enough context for a user to apply their local knowledge of how source and filetype relate to data type.
“Who” is a little harder, but it can be solved with some local knowledge. Every instrument control computer I have ever seen has a folder, usually on the desktop helpfully called “data”. Inside that folder are a set of folders with lab members names on them. This convention is universal enough that with a little nudging it can be relied on to deliver reasonable metadata. If the system allows user registration and automatically creates the relevant folders then saving files to the right folder, and thus providing that critical metadata will be quite reliable.
The desired behaviour can be encouraged even further if files dropped into the correct folder are automatically replicated to a “home computer” thus removing the need for transfer via  USB stick. Again a “convention over configuration” approach can be taken in which the directory structure found on the instrument computers is simply inverted. A data folder is created in which a folder is provided for each instrument. As an additional bonus other folders could be added which would then be treated as if they were an instrument and therefore replicated back to the main server.
How good is this?
If such a system can be made reliable (and that’s not easy - finding a secure way to ensure data gets transferred to the server and managing the dropbox style functionality suggested above is not trivial) then it can solve for a remarkable number of the use cases faced by the small scale laboratory on a regular basis. It doesn’t work for massive files or for instruments that write to a database. That said in research labs, researchers are often “saving as” some form of CSV, text or Excel file type even when the instrument does have a database. It isn’t trivial to integrate into existing shared data systems for instance for departmental instruments. Although adaptors could be easily built they would likely need to be bespoke developments working with local systems. Again though frequently what happens in practice is the users make a local copy of the data in their own directory system.
The major limitations are that there is no real information on what the files really are, just an unstructured record of the instrument that they came from. This is actually sufficient for most local use cases (the users know what the instruments are and the file types that they generate) but isn’t sufficient to support downstream re-use or processing. However, as we’ve argued in some previous papers, this can be seen as a feature not a bug. Many systems attempt to enforce a structured view of what a piece of data is early in creation process. This works in some contexts but often fails in the small lab setting. The lack of structure, while preserving enough contextual information to be locally useful, can be seen as a strength – any data type can be collected and stored without it needing to be available in some sort of schema. That doesn’t mean we can’t offer some of that structure, if and when there is functionality that gives an immediate benefit back to the user, but where there isn’t an immediate benefit we don’t need to force the user to do anything extra.
Offering a route towards more
At this point the seasoned data management people are almost certainly seething if not shouting at their computers. This system does not actually solve many of the core issues we have in data management. That said, it does solve the problem that the community of adopters actually recognises. But it also has the potential to guide them to better practice. One of the points that was made in the LabTrove paper that described work from the Frey group that I was involved in was how setting up a virtuous cycle has the potential to encourage good metadata practice. If good metadata drives functionality that is available to the user then the user will put that metadata in. But more than that, if the schema is flexible enough they will also actively engage in improving it if that improves the functionality.
The system I’ve described has two weaknesses – limited structured metadata on what the digital objects themselves actually are and as a result very limited possibilities for capturing the relationships between them. Because we’ve focussed on “merely” backing up our provenance information beyond that intrinsic to the objects themselves is limited. It is reasonably easy to offer the opportunity to collect more structured information on the objects themselves – when configuring an instrument offer a selection of known types. If a known type of instrument is selected then this can be flagged to the system which will then know to post-process the data file to extract more metadata, perhaps just enriching the record but perhaps also converting it to some form of standard file type. In turn automating this process means that the provenance of the transformation is easily captured. In standard form the system might offer in situ visualisation or other services direct to the users providing an immediate benefit. Such a library of transformations and instrument types could be offered as a community resource, ideally allowing users to contribute to build the library up.
Another way to introduce this “single step workflow” concept to the user is suggested above. Let us say that by creating an “analysis” folder on their local system this gets replicated to the backup server. The next logical step is to create a few different folders, that receive the results of different types of analysis. These then get indexed by the server as separate types but without further metadata. So they might separate mass spectrometry analyses from UV-Vis but not have the facility to search either of these for peaks in specific ranges. If a “peak processing” module is available that provides a search interface or visualisation then the user has an interest in registering those folders as holding data that should be submitted to the module. In doing this they are saying a number of things about the data files themselves – firstly that they should have peaks but also possibly getting them converted to a standard format, perhaps saying what the x and y coordinates of the data are, perhaps providing a link to calibration files.
The transformed files themselves can be captured by the same data model as the main database, but because they are automatically generated the full provenance can be captured. As these full provenance files populate the database and become easier to find and use the user in turn will look at those raw files and ask what can be done to make them more accessible and findable. It will encourage them to think more carefully about the metadata collection for their local analyses. Overall it provides a path that at each step offers a clear return for capturing a little more metadata in a little more structured form. It provides the opportunity to take the user by the hand, solve their immediate problem and carry them further along that path.
Building the full provenance graph
Once single step transformations are available then chaining them together to create workflows is an obvious next step. The temptation at this point is to try to build a complete system in which the researcher can work but in my view this is doomed to failure. One of the reasons workflow systems tend to fail is that they are complex and fragile. They work well where the effort involved in a large scale data analysis justifies their testing and development but aren’t very helpful for ad hoc analyses. What is more workflow systems generally require that all of the relevant information and transformation be available. This is rarely the case in an experimental lab where some crucial element of the process is likely to be offline or physical.
Therefore in building up workflow capabilities within this system it is crucial to build in a way that creates value when only a partial workflow is possible. Again this is surprisingly common – but relatively unexplored. Collecting a set of data together, applying a single transformation, checking for known types of data artefacts. All of these can be useful without needing an end to end analysis pipeline. In many cases implied objects can be created and tracked without bothering the user until they interested. For instance most instruments require samples. The existence of a dataset implies a sample. Therefore the system can create a record of a sample – perhaps of a type appropriate to the instrument, although that’s not necessary. If a given user does runs on three instruments, each with five samples over the course of a day its a reasonable guess that those are the same five samples. The system could then offer to link those records together so a record is made that those datasets are related.
From here its not a big mental leap to recording the creation of those samples in another digital object, perhaps dropping it into a directory labelled “samples”. The user might then choose to link that record with the sample records. As the links propagate from record of generation, to sample record, to raw data to analysis, parts of the provenance graphs are recorded. The beauty of the approach is that if there is a gap in the graph it doesn’t reduce the base functionality the user enjoys, but if they make the effort to link it up then they can suddenly release all the additional functionality that is possible. This is essentially the data model that we proposed in the LabTrove paper but without the need to record the connections up front.
Challenges and complications
None of the pieces of this system are terribly difficult to build. There’s an interesting hardware project – how best to build the box itself and interact with the instrument controller computers. All while keeping the price of the system as low as possible. There’s a software build to manage the server system and this has many interesting user experience issues to be worked through. The two clearly need to work well together and at the same time support an ecosystem of plugins that are ideally contributed by user communities.
The challenge lies in building something where all these pieces work well together and reliably. Actually delivering a system that works requires rapid iteration on all the components while working with (probably impatient and busy) researchers who want to see immediate benefits. The opportunity if it can be got right is immense. While I’m often sceptical of the big infrastructure systems in this space that are being proposed and built, they do serve specific communities well. The bit that is lacking is often the interface onto the day to day workings of an experimental laboratory. Something like this system could be the glue-ware that brings those much more powerful systems into play for the average researcher.
Some notes on provenance
These are not particularly new ideas, just an attempt to rewrite something that’s been a recurring itch for me for many years. Little of this is original and builds on thoughts and work of a very large range of people including the Frey group current and past, members of the National Crystallography Service, Dan Hagon, Jennifer Lin, Jonathan Dugan, Jeff Hammerbacher, Ian Foster (and others at Chicago and the Argonne Computation Institute), Julia Lane, Greg Wilson, Neil Jacobs, Geoff Bilder, Kaitlin Thaney, John Wilbanks, Ross Mounce, Peter Murray-Rust, Simon Hodson, Rachel Bruce, Anita de Waard, Phil Bourne, Maryann Martone, Tim Clark, Titus Brown, Fernando Perez, Frank Gibson, Michael Nielsen and many others I have probably forgotten. If you want to dig into previous versions of this that I (was involved with) writing then there are pieces in Nature (paywalled unfortunately), Automated Experimentation, the PLOS ONE paper mentioned above as well as someprevious blog posts.Â
I am currently on holiday. You can tell this because I’m writing, reading and otherwise doing things that I regard as fun. In particular I’ve been catching up on some reading. I’ve been meaning to read Danah Boyd‘s It’s Complicated for some time (and you can see some of my first impressions in the previous post) but I had held off because I wanted to buy a copy.
That may seem a strange statement. Danah makes a copy of the book available on her website as a PDF (under a CC BY-NC license) so I could (and in the end did) just grab a copy from there. But when it comes to books like this I prefer to pay for a copy, particularly where the author gains a proportion of their livelihood from publishing. Now I could buy a hardback or paperback edition but we have enough physical books. I can buy a Kindle edition from Amazon.co.uk but I object violently to paying a price similar to the paperback for something I can only read within Amazon software or hardware, and where Amazon can remove my access at any time.
In the end I gave up – I downloaded the PDF and read that. As I read it I found a quote that interested me. The quote was from Michel Foucault’s Discipline and Punish, a study of the development of the modern prison system – the quote if anyone is interested was about people’s response to being observed and was interesting in the context of research assessment.
Once I’d embarrassed myself by asking a colleague who knows about this stuff whether Foucault was someone you read, or just skimmed the summary version, I set out again to find myself a copy. Foucault died in 1984 so I’m less concerned about paying for a copy but would have been happy to buy a reasonably priced and well formatted ebook. But again the only source was Amazon. In this case its worse than for Boyd’s book. You can only buy the eBook from the US Amazon store, which requires a US credit card. Even if I was happy with the Amazon DRM and someone was willing to buy the copy for me I would be technically violating territorial rights in obtaining that copy.
It was ironic that all this happened the same week that the European Commission released its report on submissions to the Public Consultation on EU Copyright Rules. The report quickly develops a pattern. Representatives on public groups, users and research users describe a problem with the current way that copyright works. Publishers and media organisations say there is no problem. This goes on and on for virtually every question asked:
In the print sector, book publishers generally consider that territoriality is not a factor in their business, as authors normally provide a worldwide exclusive licence to the publishers for a certain language. Book publishers state that only in the very nascent eBooks markets some licences are being territorially restricted.
As a customer I have to say its a factor for me. I can’t get the content in the form I want. I can’t get it with the rights I want, which means I can’t get the functionality I want. And I often can’t get it in the place I want. Maybe my problem isn’t important enough or there aren’t enough people like me for publishers to care. But with traditional scholarly monograph publishing apparently in a death spiral it seems ironic that these markets aren’t being actively sought out. When books only sell a few hundred copies every additional sale should matter. When books like Elinor Ostrom’s Governing the Commons aren’t easily available then significant revenue opportunities are being lost.
Increasingly it is exactly the relevant specialist works in social sciences and humanities that I’m interested in getting my hands on. I don’t have access to an academic library, the nearest I might get access to is a University focussed on science and technology and in any case the chance of any specific scholarly monograph being in a given academic library is actually quite low. Inter-library loans are brilliant but I can’t wait a week to check something.
I spent nearly half a day trying to find a copy of Foucault’s book that was in the form I wanted with the rights I wanted. I’ve spent hours trying to find a copy of Ostrom’s as well. In both cases it is trivial to find a copy online – took me around 30 seconds. In both cases its relatively easy to find a second hand print copy. I guess for traditional publishers its easy to dismiss me as part of a small market, one that’s hard to reach and not worth the effort. After all, what would I know, I’m just the customer.
I have a distinct tendency to see everything through the lens of what it means for research communities. I have just finally read Danah Boyd’s It’s Complicated a book that focuses on how and why U.S. teenagers interact with and through social media. The book is well worth reading for the study itself, but I would argue it is more worth reading for the way it challenges many of the assumptions we make about how social interactions online and how they are mediated by technology.
The main thrust of Boyd’s argument is that the teenagers she studied are engaged in a process of figuring out what their place is amongst various publics and communities. Alongside this she diagnoses a long standing trend of reducing the availability of the unstructured social interactions through which teens explore and find their place.
A consistent theme is that teens go online not to escape the real world, or because of some attraction to the technology but because it is the place where they can interact with their communities, test boundaries and act out in spaces where they feel in control of the process. She makes the point that through these interactions teens are learning how to be public and also how to be in public.
So the interactions and the needs they surface are not new, but the fact that they occur in online spaces where those interactions are more persistent, visible, spreadable and searchable changes the way in which adults view and interact with them. The activities going on are the same as in the past: negotiating social status, sharing resources, seeking to understand what sharing grants status, pushing the boundaries, claiming precedence and seeking control of their situation.
Boyd is talking about U.S. teenagers but I was consistently struck by the parallels with the research community and its online and offline behavior. The wide prevalence of imposter syndrome amongst researchers is becoming better known – showing how strongly the navigation and understanding of your place in the research community effects even senior researchers. Prestige in the research community arises from two places, existing connections (where you came from, who you know) and the sharing of resources (primarily research papers). Negotiating status, whether offline or on, remains at the core of researcher behavior throughout careers. In a very real sense we never grow up.
People generally believe that social media tools are designed to connect people in new ways. In practice, Boyd points out, mainstream tools effectively strengthen existing connections. My view has been that “Facebooks for Science†fail because researchers have no desire to be social as researchers in the same way the do as people – but that they socialize through research objects. What Boyd’s book leads me to wonder is whether in fact the issue is more that the existing tools do little to help researchers negotiate the “networked publics†of research.
Teens are learning and navigating forms of power, prestige and control that are highly visible. The often do this through sharing objects that are easily intepretable, text and images (although see the chapter on privacy for how this can be manipulated). The research community buries those issues because we would like to think we are a transparent meritocracy.
Where systems have attempted to surface prestige or reputation in a research context through point systems they have never really succeeded. Partly this is because those points are not fungible – they don’t apply in the “real†world (StackExchange wins in part precisely because those points did cross over rapidly into real world prestige). Is it perhaps precisely our pretence that this sense-making and assignment of power and prestige is supposed to be hidden that makes it difficult to build social technologies for research that actually work?
An Aside: I got a PDF copy of the book from Danah Boyd’s website because a) I don’t need a paper copy and b) I didn’t want to buy the ebook from Amazon. What I’d really like to do is buy a copy from an independent bookstore and have it sent somewhere where it will be read, a public or school library perhaps. Is there an easy way to do that?
It takes me a while to process things. It often then takes me longer to feel able to write about them. Two weeks ago we lost one of the true giants of Open Science. Othershavewrittenabout Jean-Claude’s work and his contributions – and I don’t feel able to add much to those reflections at the moment. I will also be participating in a conference panel in August at which Jean-Claude was going to speak and which will now be dedicated to his memory – I may have something more coherent to say by then.
In the end I believe that Jean-Claude would want to be remembered by the work that he left online for anyone to see, work with, and contribute to. He was fearless and uncompromising in working, exploring, and thinking online, always seeking new ways to more effectively expose the process of the research he was doing. He could also be a pain to work with. There was never any question that if you chose to work with him then you worked to his standards – perhaps rather he would choose to work with you only if you worked to his standards. By maintaining the principle of immediate and complete release of the research process, he taught many of us that there was little to fear and much to gain from this radical openness. Today I often struggle to sympathise with other people’s fears of what might happen if they open up, precisely because Jean-Claude forced me to confront those fears early on and showed me how ill founded many of them are.
In his constant quest to get more of the research process online as fast as possible Jean-Claude would grab whatever tools were to hand. Wiki platforms, YouTube, Blogger, SecondLife, Preprint servers, GoogleDocs and innumerable other tools were grasped and forced into service, linked together to create a web, a network of information and resources. Sometimes these worked and sometimes they didn’t. Often Jean-Claude was ahead of his time, pushing tools in their infancy to the limits and seeing the potential that in many cases is only beginning to be delivered now.
Ironically by appropriating whatever technology was to hand he spread the trace of his work across a wide range of services, many of them proprietary, simply because they were the best tools available at the time. If the best way to remember his work is through preserving that web of resources then we now face a serious challenge. How far does that trace spread? Do we have the rights to copy and preserve it? If so what parts? How much of the history do we lose by merely taking a copy? Jean-Claude understood this risk and engaged early on with the library at Drexel to archive core elements of his program – once again pushing the infrastructure of institutional repositories beyond what they had been intended to do. But his network spread far further than what has currently been preserved.
I want to note that in the hours after we heard the news I didn’t realise the importance of preserving Jean-Claude’s work. I think its important to recognise that it was information management professionals who immediately realised both the importance of preservation and the risks to the record and set in motion the processes necessary to start that work. I remain, like most researchers I suspect, sloppy and lazy about proper preservation and we need the support of professionals who understand the issues and technical challenges, but also are engaged with preservation of works and media outside the scholarly mainstream if science that is truly on the web is to have a lasting impact. The role of a research institution, if it is to have one in the future, is in part to provide that support, literally to insitutionalise the preservation of digital scholarship.
The loss of Jean-Claude leaves a gaping hole. In life his determination to provide direction, to show what could be done if you chose, was a hard act to follow. His rigid (and I will admit to finding it sometimes too rigid) adherence to principles provided that direction – always demanding that we take each extra step. The need for preserving his work is showing us what we should have been doing all along. It should probably not be surprising that even in death he is still providing direction, and also not surprising that we will continue to struggle to realise his vision of what research could be.
Over the past few weeks there has been a sudden increase in the amount of financial data on scholarly communications in the public domain. This was triggered in large part by the Wellcome Trust releasing data on the prices paid for Article Processing Charges by the institutions it funds. The release of this pretty messy dataset was followed by a substantial effort to clean that data up. This crowd-sourced data curation process has been described by Michelle Brook. Here I want to reflect on the tools that were available to us and how they made some aspects of this collective data curation easy, but also made some other aspects quite hard.
The data started its life as a csv file on Figshare. This is a very frequent starting point. I pulled that dataset and did some cleanup using OpenRefine, a tool I highly recommend as a starting point for any moderate to large dataset, particularly one that has been put together manually. I could use OpenRefine to quickly identify and correct variant publisher and journal name spellings, clean up some of the entries, and also find issues that looked like mistakes. It’s a great tool for doing that initial cleanup, but its a tool for a single user, so once I’d done that work I pushed my cleaned up csv file to github so that others could work with it.
After pushing to github a number of people did exactly what I’d intended and forked the dataset. That is, they took a copy and added it to their own repository. In the case of code people will fork a repository, add to or improve the code, and then make a pull request that gives the original repository owner that there is new code that they might want to merge into their version of the codebase. The success of github has been built on making this process easy, even fun. For data the merge process can get a bit messy but the potential was there for others to do some work and for us to be able to combine it back together.
But github is really only used by people comfortable with command line tools – my thinking was that people would use computational tools to enhance the data. But Theo Andrews had the idea to bring in many more people to manually look at and add to the data. Here an online spreadsheet such as those provided by GoogleDocs that many people can work with is a powerful tool and it was through that adoption of the GDoc that somewhere over 50 people were able to add to the spreadsheet and annotate it to create a high value dataset that allowed the Wellcome Trust to do a much deeper analysis than had previously been the case. The dataset had been forked again, now to a new platform, and this tool enabled what you might call a “social merge” collecting the individual efforts of many people through an easy to use tool.
The interesting thing was that exactly the facilities that made the GDoc attractive for manual crowdsourcing efforts made it very difficult for those of us working with automated tools to contribute effectively. We could take the data and manipulate it, forking again, but if we then pushed that re-worked data back we ran the risk of overwriting what anyone else had done in the meantime. That live online multi-person interaction that works well for people, was actually a problem for computational processing. The interface that makes working with the data easy for people actually created a barrier to automation and a barrier to merging back what others of us were trying to do. [As an aside, yes we could in principle work through the GDocs API but that’s just not the way most of us work doing this kind of data processing].
Crowdsourcing of data collection and curation tends to follow one of two paths. Collection of data is usually done into some form of structured data store, supported by a form that helps the contributor provide the right kind of structure. Tools like EpiCollect provide a means of rapidly building these kinds of projects. At the other end large scale data curation efforts, such as GalaxyZoo, tend to create purpose built interfaces to guide the users through the curation process, again creating structured data. Where there has been less tool building and less big successes are the space in the middle, where messy or incomplete data has been collected and a community wants to enhance it and clean it up. OpenRefine is a great tool, but isn’t collaborative. GDocs is a great collaborative platform but creates barriers to using automated cleanup tools. Github and code repositories are great for supporting the fork, work, and merge back patterns but don’t support direct human interaction with the data.
These issues are part of a broader pattern of issues with the Open Access, Data, and Educational Resources more generally. With the right formats, licensing and distribution mechanisms we’ve become very very good at supporting the fork part of the cycle. People can easily take that content and re-purpose it for their own local needs. What we’re not so good at is providing the mechanisms, both social and technical, to make it easy to contribute those variations, enhancements and new ideas back to the original resources. This is both a harder technical problem and challenging from a social perspective. Giving stuff away, letting people use it is easy because it requires little additional work. Working with people to accept their contributions back in takes time and effort, both often in short supply.
The challenge may be even greater because the means for making one type of contribution easier may make others harder. That certainly felt like the case here. But if we are to reap the benefits of open approaches then we need to do more than just throw things over the fence. We need to find the ways to gather back and integrate all the value that downstream users can add.



 in a PhD thes...")