The moment that I decided it was time to move on from PLOS is crystal clear in my mind. I was standing in a room at the South of Perth Yacht Club, giving a short talk on my view of the political economics of journals and scholarly publishing. I’d been puzzling for a while about a series of things. Why wasn’t the competitive market we predicted in APCs emerging? What was it that made change in the research communities so hard? How do we move from talking about public access to enabling public use? And how do we decide where to invest limited resources? What is thing we call culture and why is changing it hard? The people working on a program they called Cultural Science seemed to have some interesting approaches to this, so when they asked me to the workshop I gladly came.
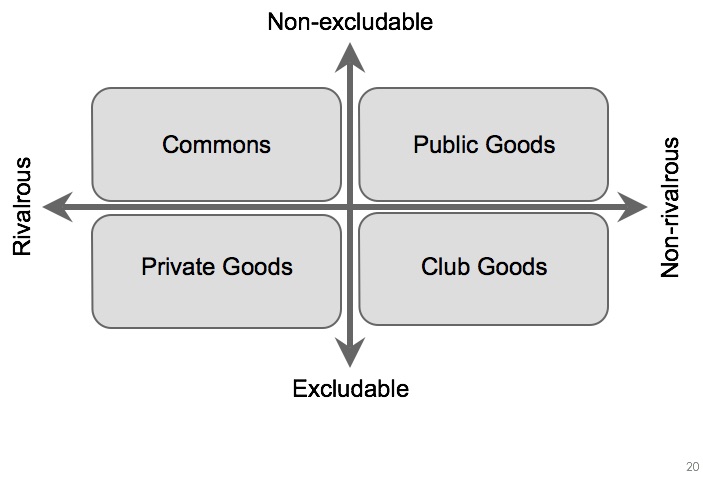
It was a small group, so I was speculating. What if instead of treating knowledge as a public good we acknowledged that it is born exclusive? Knowledge can’t exist with just one person knowing, it must be held by a group. But it starts exclusive – held by the group – and when we choose to communicate it, publish it, open it up, translate or explain it we invest in making it less exclusive. I pointed to the exclusive – non-rivalrous quadrant of the classic goods diagram, labelled “toll goods” and said that the shift from a subscription journal (toll good) to Open Access was just one example of this kind of investment, that all of this “public-making” takes us towards the public good quadrant but that we never quite reach it. I might even have said we could do with a better name for that bottom right quadrant. Jason Potts, who was the other panelist in the session spoke up to say “…it has another name you know…they’re called ‘club goods'”.
That was the moment – we’d been talking about communities, cultures, economics, “public-making” but it was the word ‘club’ and its associated concepts, both pejorative and positive that crystalised everything. We were talking about the clubbishness of making knowledge – the term “Knowledge Clubs” emerged quickly – but also the benefits that such a club might gain in choosing to invest in wider sharing. John Hartley and Jason had laid much of the groundwork in connecting groups, culture, economics and communication in their book. What we might now have was a frame in which to interrogate why these clubs (research groups, disciplines, universities, but also journals) do what they do.
Pretty much everything since then flowed from that point. I’ve been frustrated for a long time with traditional economic analyses of scholarly publishing. They don’t seem to explain what actually happens, and fail to capture critical aspects of what is going on. The lens of club economics seems like it might help to capture more of the reality of what is going on. Jason has subsequently worked through this concept, laying out the issues and a new working paper is the result. This is at the idea stage, there is much detail to be worked out, but what the club formulation does is place group dynamics at the centre of the frame. Treating articles as simple supply and demand objects (which they’re not) at equilibrium (which they’re generally not) within the background of some sort of market (which the research community isn’t) leaves the important pieces, the messy human interactions, prestige and reputation out of the equation. I’m not going to claim we have the answer to solving that, but we do at least have a new way of looking at the questions.
When I saw the anonymous piece “Openness is Inclusivity†it both struck a chord and made me uncomfortable. Striking a chord because I’m increasingly concerned about the institutionalization and centralization of Open Science activities. Uncomfortable because it comes across as an attack, and an anonymous one at that, on one organization.
The Centre for Open Science has done a lot of good work, had a lot of success and brought in a lot of money to run a large operation. I think I have generally argued in favour of smaller groups over large ones because I believe that’s a better approach over all. But it’s more than fair to ask when a big group is conventionally successful, is any disquiet just really based on jealousy of that success? In any case if there’s a real issue here its not about CoS, but about the way we are building our institutions as Open Science becomes mainstream.
I think it’s always better to dig down into principles. And that’s why I got involved in writing this response. As a way of asking what we want the system to look like. The focus on the question of diversity is a principle we can base an argument on. Those principles can help us think about design patterns and approaches that will build the system we want.
And I can go back to being comfortable being jealous of the success of CoS. Because really who wouldn’t be? And if I disagree with specific things that they do, I’ve got a grounding sense of how to tell what are real issues and what is just envy.
Once again, reproducibility is in the news. Most recently we hear that irreproducibility is irreproducible and thus everything is actually fine. The most recent round was kicked off by a criticism of the Reproducibility Project followed by claim and counter claim on whether one analysis makes more sense than the other. I’m not going to comment on that but I want to tease apart what the disagreement is about, because it shows that the problem with reproducibility goes much deeper than whether or not a particular experiment replicates.
At the centre of the disagreement are two separate issues. The most easy to understand is the claim that the Reproducibility Project did not faithfully replicate the original studies. Of course this raises the question of what “replicate” means. Is a replication seeking to precise re-run the same test or to test the claim more generally? Being fuzzy about which is meant lies at the bottom of many disagreements about whether as experiment is “replicated”.
The second issue is the one that has generated the most interesting commentary, but which is the hardest for a non-expert to tease apart. At its core is a disagreement over how “replication” should be statistically defined. That is, what is the mathematical analysis to be applied to an original test, and its repeat, to provide a Yes/No answer to the question “did it replicate”. These issues were actually raised from the beginning. It is far from obvious what the right analysis would be, or indeed whether the idea of “a right answer” actually makes sense. That’s because, again, there are serious differences of definition in what is meant by replication, and these questions cut to the core of how we use statistics and mathematics to analyse the world in which our experiments are run.
Problems of language I: Levels of replication and re-test
When there is a discussion of terminology it often focusses around this issue. When we speak of “replicating” an experiment do we mean carrying it out exactly the same, at its most extreme simply re-running a computational process in “exactly the same” environment, in the laboratory perhaps using the same strains, primers, chemicals or analytical techniques? Or do we mean doing “the same” experiment but without quite the same level of detail, testing the precise claim but not the precise methodology, perhaps using a different measurement technique, differing antibodies, or an alternative statistical test or computational algorithm. Or perhaps we mean testing the general claim, not that this test in this mouse strain delivers this result, but that chemical X is a regulator of gene YÂ in general.
Often we make a distinction between “replicating” and “reproducing” a result which corresponds to the distinction between the first and second level. We might need a third term, perhaps “generalising” to describe the third. But the ground between these levels is a quagmire and depending on your concerns you might categorise the same re-test as a replication or a reproduction. Indeed this is part of the disagreement in the current case. Is it reasonable to call a re-test of flag priming in a different culture? One group might say that are testing the general claim made for flag priming but is it the same test if the group is different, even if the test is identical? What is test protocol and what is subject. Would that mean we need to run social psychology replications on the same subjects?
Problems of language II: Reproducible experiments should not (always) reproduce
The question of what a direct replication in social pyschology would require is problematic. It cuts to the heart of the claims that social pyschology makes, that it detects behaviours and modes of thinking that are general. But how general and across what boundaries? Those questions are ones that social pyschologists probably have intuitive answers for (as do stem cell biologists, chemists and economists when faced with similar issues) but not ones that are easy, or perhaps even possible, to explain across disciplinary boundaries.
Layered on top of this are differences of opinion, suspicions about probity and different experiences within each of these three categories. Do some experiments require a “craft” or “green fingers” to get right? How close should a result be to be regarded as “the same”? What does a well designed experiment look like? What is the role of “elegance”? Disagreements about what matters, and ultimately rather different ideas about what the interaction between “reality” and “experiment” looks like also contribute. In the context of strong pseudo- and anti-science agendas having the complex discussion about how we judge which contradictory results to take seriously seems to be challenging. These problems are hard because tackling them requires dealing with the social aspects of science in a way that many scientists are uncomfortable with.
Related to this is the point raised above, that its not clear what we mean by replication. Given that this often relates to claims that are supported by p-values, we should first note that these are often mis-used, or at very least misrepresented. Certainly we need to get away from “p = 0.05 means its 95% reliable”. The current controversy rests in part on the question of the distinction between the replication experiment providing a result in the 95% confidence interval of the initially reported effect size, or that initially reported effect size lying in the 95% confidence interval of the replication. Both arguments can lead to some fairly peculiar results. An early criticism of the initial Reproducibility Project paper suggested a Bayesian approach to testing reproducibility but that had its own problems.
At the core of this is a fundamental problem in science. Even if a claim is “true” we don’t expect to get the same results from the same experiment. Random factors, uncontrolled factors all can play a role. This is why we do experiments and repeat them and do statistical analysis. It’s a way of trying to ensure we don’t fool ourselves. But it increasingly seems that we’re facing a rather toxic mixture of the statistical methods not being up to the job, and the fact that many of us are not up to the job of using them properly. That fact that the vast majority of us researchers using those statistical tools aren’t qualified to figure out which is probably instructive.
Either way it shouldn’t be surprising that if there isn’t a clear definition of what it means for a repeated test “to replicate” a previous one that the way we talk about these processes can get confusing.
Problems in philosophy and language: Turtles all the way down
When people talk about the “reproducibility” of a claim they’re actually talking about at least four different kinds of things. The first is whether it is expected that additional tests will confirm a claim. That is, is the claim “true” in some sense. The second is whether a specific re-run of a specific trial will (or did) give “the same” result. The third is whether the design or a trial (or its analysis) is such that repeated trials would be expected to give the same result (whatever that is). That is, is the experiment properly designed so as to give “reliable” results. Finally we have the question of whether the description of an experiment is sufficiently good to allow it to be re-run.
That the relationship between “truth” and empirical approaches that use repeated testing to generating evidence to support claims is a challenging problem is hardly a new issue in the philosophy of science. The question of whether the universe is reliable is a question asked in a social context by humans, and the tests we run to try and understand that universe are designed by humans with an existing context. But equally those tests play out in an arena that appears to have some consistencies. Technologies, for good or ill, tend to work when built and tested, not when purely designed in the abstract. Maths seems useful. It really is turtles all the way down.
However, even without tackling the philosophical issues there are some avenues for solving problems of the language we use. “Reproducible” is often used as interchangeable with “true” or even “honest”. Sometimes it refers to the description of the experiment, sometimes to the ability of re-tests to get the same result. “Confidence” is often referred to as absolute, not relative, and discussed without clarity as to whether it refers to the claim itself or the predicted result of a repeated test. And all of these are conflated across the various levels of replication, reproduction and generalisation discussed above.
Problems of description vs problems of results
Discussion of whether an article is “replicable” can mean two quite different things. Is the description of the test sufficient to enable it be re-run (or more precisely, does it meet some normative standard of community expectation of sufficient description)? This is a totally different question to the one of what is expected (or happens) when such a test is actually re-run. Both in turn are quite different, although there is a relation, to the question of whether the test is well designed, either to generate consistently the same result, or to provide information on the claim.
Part of the solution may lie in a separation of concerns. We need much greater clarity in the distinction between “described well enough to re-do” and “seems to be consistent in repeated tests”. We need to maintain those distinctions for each of the different levels above: replication, reproduction and generalisation. All of these in turn are separate to the question of whether a claim is true, or the universe (or our senses) reliable, or the social context and power relations that guided the process of claim making and experiment. It is at the intersections between these different issues that things get interesting: does the design of an experiment may answer a general question, or is it much more specific? Is the failure to get the same result, or our expectation of how often we “should” get the same result a question of experimental design, what is true, or the way our experience guides us to miss, or focus on specific issues? In our search for reliable, and clearly communicated, results have we actually tested a different question to the one that really matters?
A big part of the problem is that by using sloppy language we make it unclear what we are talking about. If we’re going to make progress there will need to be a more precise, and more consistent way of talking about exactly what problem is under investigation at any point in time.
This is a working through of some conversations with a range of people, most notably Jennifer Lin. It is certainly not original – and doesn’t contain many answers – but is an effort to start organising thoughts around how to talk about the problems around reproducibility, which is after all the interesting problem. Any missing links and credits entirely my own fault and happy to make corrections.
European flag outside the Commission (Photo credit: Wikipedia)
The following is my application to join the European Commission Open Science Policy Platform. The OSPP will provide expert advice to the European Commission on implementing the broader Open Science Agenda. As you will see some of us have a concern that the focus of the call is on organisations, rather than communities. This is a departure from much of the focus that the Commission itself has adopted on the potential benefits and opportunities of Open Science. A few of us are therefore applying as representatives of the community of interested and experienced people in the Open Science space.
I am therefore seeking endorsement, in the form of a comment on this post or email directly to me if you prefer, as someone who could represent this broader community of people, not necessarily tied to one type of organisation or stakeholder. This being an open form you are also of course free to not endorse me as well :-)
I am writing to apply for membership of the Open Science Policy Platform as a representative of the common interest community of Open Science developers and practitioners. This community is not restricted to specific organisations or roles but includes interested people and organisations from across the spectrum of stakeholders including researchers, technologists, publishers, policy makers, funders and all those interested in the change undergoing research.
I have a concern that the developing policy frameworks and institutionalisation of Open Science are leaving behind precisely the community focus that is at the heart of Open Science. As the Commission has noted, one of the key underlying changes leading to more open practice in research is that many more people are becoming engaged in research and scholarship in some form. At the same time the interactions between this growing diversity of actors increasingly form an interconnected network. It is not only that this network reaches beyond organisational and sector boundaries that is important. We need to recognise that it is precisely that blurring of boundaries that underpins the benefits of Open Science.
I recognise that for practical policy making it is essential to engage with key stakeholders with the power to make change. In addition I would encourage the Commission to look beyond the traditional sites of decision making power within existing institutions to the communities and networks which are where the real cultural changes are occurring. In the end, institutional changes will only ever be necessary, and not sufficient, to support the true cultural change which will yield the benefits of Open Science.
I am confident I can represent some aspects of this community particularly in the areas of:
New models for research communications
Incentives and rewards that will lead to cultural change
The relationship between those incentives and research assessment.
To provide evidence of my relevance to represent this common interest I have posted this application publicly and asked for endorsement by community members.
I have a decade of relevant experience in Open Science. I have long been an advocate of radical transparency in research communication including being of the early practitioners of Open Notebook Science. I have been involved in a wide range of technical developments over the past decade in data management, scholarly communications and research assessment and tracking. I have been engaged in advising on policy development for Open Access, Open Data and open practice more generally for a wide range of institutions, funders and governments. I am also one of the authors of three key documents, the altmetrics manifesto, the Panton Principles, and the Principles for Open Scholarly Infrastructures.
As an advocate for Open Access and Open Data I have been involved in developing the arguments for policy and practice change in the UK, US and Europe. As Advocacy Director at PLOS (2012-2015) I was closely involved in developments on Open Access in particular. My team lead the coalition that supported the Californian Open Access bill and I testified before the UK House of Commons BIS committee. Submissions to the Commons Enquiry, the HEFCE Metrics Tide report, and the EU Expert Group on Copyright Reform all had an influence on the final text.
In 2015 I returned to academia, now in the humanities. In this capacity I am part of a small group looking critically at Open Science. I am an advisor for Open and Collaborative Science in Development Network, a research project looking at the application of Open Science practice in development contexts, as well as leading a pilot project for the International Development Research Centre on implementing Data Sharing practice amongst grantees. My research is focussing on how policy, culture and practice interact and how an understanding of this interaction can help us design institutions for an Open Science world.
I therefore believe I am well placed to represent a researcher, developer, and practitioner perspective on the OSPP as well as to bring a critical view to how the details of implementation can help to bring about what it is that we really want to achieve in the long term, a cultural change that embraces the opportunity of the web for science.
It has been painful to watch the tensions at the Wikimedia Foundation explode over the last few months and with the stepping down of the Executive Director there seems a mood of conciliation and a desire for WMF to learn from the process. I know next to nothing of the details or the story, so while it is the spur for this post I don’t want to offer any opinions on WMF itself. But the story fits the outline of a pattern I’ve seen in a lot of organisations in the Open Community.
Organisations in “the open space” are often community driven. Groups come together to solve a problem, and in a few cases they succeed. Most fail, and most fail pretty early. Those that survive the initial phase often experience massive growth, sometimes beyond the wildest dreams of those who started them. This brings some challenges.
Sustainability is a big one: too many of these organisations lurch from grant to grant, depending on the largesse of philanthropists or government funders. Most of these eventually fail or stagnate. Some negotiate this transition by turning private and obtaining VC or Angel funds. Eventually most of these are sold off to incumbent players, and gradually lose the central thread of openness and just becoming part of the service background in their space. Nothing wrong with that but they’re no longer really part of the open community at the end of this process.
But some organisations succeed and find a model: donations, memberships, advertising, fee for service have all been successful in different spaces. These can grow to be sizeable companies, ones that need professional staff and business discipline to manage complex operations, significant infrastructures, and substantial financial flows and reporting. No multi-million dollar a year organisation is going to run for very long on volunteer labour, at least not where those volunteers need to work for a living.
Passion can also be a problem, as well as being a driver. Without that passion and without that community nothing gets done. Indeed without the passion many not-for-profit organisations wouldn’t be able to attract staff at the rates that they can reasonably pay. The community is a core asset.
But too often there is a disjunct between the discipline and expertise that comes with a leadership team with experience of running multi-million dollar organisations and that passionate community that sees itself as the guardian of the organisation’s value. Passion and belief in a mission, can lead to the creation of a close core community of true believers who don’t ask the tough questions; about how it will be done, what will be prioritised, and when. Tough minded management doing what needs to be done to streamline operation can fail to understand, or ignore what it is that the sustaining community cares about.
Too often it seems like organisations face a choice between hiring someone with management experience at the right scale and someone who really understands the core values of the community. I’ve seen very few examples of organisations that truly marry oustanding business management skills with the expertise and passion of the core community, whether those are staff or volunteers.
One of the reasons for this is leadership. It’s really hard to name people who truly grew up within our community and understand it a deep personal level, and who have also run organisations turning over $100M or $50M or even $10M. And who aren’t Mark Surman. I fear this is a structural failure, that it arises from the funding systems that exist in our space. That the very way we structure our organisations, the ways that they grow, and the way that management is structured in response to that, means that we systematically fail to nurture and grow the people who fit both of these criteria, to train them to be ready for the roles of COO and CEO, DO and ED. Domain expertise and passion comes from inside, business experience from outside. The career paths get cut off.
I don’t know the solution. Better growth and financing models an “MBA for Open Organisations” perhaps. Would incubators that provide the right kind of support and expertise be a better use of money than the ubiquitous “planning grant”. Personal prizes that provide a way of rewarding the sweat equity that founders put in, while helping them move from a role that is directing to inspiring when the time comes.
There is nothing easy about balancing the passion of a successful and motivated community with the discipline required to manage a large organisation. Traditionally we assume that community leaders and management directors are different people, different kinds of people. But does it have to be that way?
I promised some thinking out loud and likely naive and uninformed opinion in my plans for the new year. Here’s a start on that with apologies to Science and Technology Studies and Cultural Studies people who’ve probably thought all of this through. Yes, I am trying to get people to do my due diligence literature review for me.
Cultures of Pseudomonas syringae  (Photo credit: Wikipedia)
It’s a common strand when we talk about improving data sharing or data management, or access to research, or public engagement…or… “Cultural Change, its hard”. The capitals are deliberate. Cultural Change is seen as a thing, perhaps a process that we need to wait for, because we have internalised the Planck narrative that “science progresses one funeral at a time”1. Yet we are also still waiting for the Google generation with their “culture of sharing” to change the world for us.
Some of us get bored waiting and look for hammers. We decide that policies, particularly funder policies, but also journal or institutional policies requiring data sharing, are the best way to drive changes in practice. And these work, to some extent, in some places, but then we (and I use the “we” seriously) are disappointed when changes in practice turn out to be the absolute minimum that has to be done; that the cultural change that we assumed would follow does not, even in some cases is hampered by an association of the policy with all those other administrative requirements that we (again, I use the word advisedly) researchers complain are burying us, preventing us from getting on with what we are supposed to be doing.
We (that word again) point at the successes. Look at the public genome project and the enormous return on investment! Look at particle physics! Mathematics and the ArXiv. The UK ESRC and the UK Data Archive, the ICPSR! Why is it that the other disciplines can’t be like them? It must be a difference in culture. In history. In context. And we make up stories about why bioinformatics is different to chemistry, why history isn’t more like economics. But the benefits are clear. Data sharing increases impact, promotes engagement, improves reproducibility, leads to more citations, enhances career prospects and improves skin tone. Some of these even have evidence to back them up. Good data management and sharing practice has real benefits that have been shown in specific contexts and specific places. So its good that we can blame issues in other places, and other contexts, on “differences of culture”. That makes the problem something that is separate from what we believe to be objectively best practice that will drive real measurable outcomes.
Then there are the cultural clashes. When the New England Journal of Medicine talked about the risk of communities of “research parasites” arising to steal people’s research productivity the social media storm was immense. Again, observers trying not to take sides might point to the gulf in cultures between the two camps. One side committed to the idea that data availability and critique is the bedrock of science, although not often thinking deeply about what is available to who, or for what or when. Just lots, for everyone, sooner! On the other a concern for the structure of the existing community, of the quality of engagement, albeit perhaps too concerned with the stability of one specific group of stakeholders. Should the research productivity of a tenured professor be valued above the productivity of those critiquing whether the drugs actually work?
In each of these cases we blame “culture” for things being hard to change. And in doing so we externalise it, make it something that we don’t really engage with. It probably doesn’t help that the study of culture, and the way it is approached is alien to most with a sciences background. But even those disciplines we might to tackle these issues seem reticent to engage. Science and Technology studies appears to be focussed on questions of why we might want change, who is it for, what does the technology want? But seems to see cultures as a fixed background, focussing rather on power relations around research. Weirdly (and I can’t claim to have got far into this so I may be wrong) Cultural Studies doesn’t seem to deal with culture per se so much as seek to generalise stories that arise from the study of individuals and individual cases. Ethnography looks at individuals, sociology focusses on interactions, as does actor-network theory, rarely treating cultures or communities as more than categories to put things into or backgrounds to the real action.
It seems to me that if we’re serious about wanting to change cultures and not merely to wait for Cultural Change (with its distancing capitals) to magically happen then we need to take culture – and cultures – seriously. How do they interact and how do they change? What are the ways in which we might use all of the levers at our disposal: policy yes, but also evidence and analysis, new (and old) technology, and the shaping of the stories we tell ourselves and each other about why we do what we do. How can we use this to build positive change and coherent practice, while not damaging the differences in culture, and the consequent differences in approach, that enrich scholarship and its interaction withe communities it is carried out within?
The question of who “we” is in any given context, what cultures are we a part of, what communities is a challenging one. But I increasingly think if we don’t have frameworks for understanding the differing cultures amongst research disciplines and researchers and other stakeholders, how they interact, compete, clash and change, then we will only make limited progress. Working with an understanding of our own cultures is the lever we haven’t pulled, in large part because thinking about culture, let alone examining our own is so alien. We need to take culture seriously.
Cite as “Bilder G, Lin J, Neylon C (2016) Where are the pipes? Building Foundational Infrastructures for Future Services, retrieved [date], https://cameronneylon.net/blog/where-are-the-pipes-building-foundational-infrastructures-for-future-services/ ‎” You probably don’t think too much about where all the services to your residence run. They go missing from view until something goes wrong. But how do we maintain them unless they are identified? An entire utilities industry, which must search for utility infrastructure, hangs in the balance on this knowledge. There’s even an annual competition, a rodeo no less, to crown the best infrastructure locators in the land, rewarding those who excel at re-discovering where lost pipes and conduits run.
It’s all too easy to forget where the infrastructure lies when it’s running well. And then all too expensive if you have to call in someone to find it again. Given that preservation and record keeping lies at the heart of research communications, we’d like to think we could do a better job. Good community governance makes it clear who is responsible for remembering where the pipes run as well as keeping them “up to codeâ€. Turns out that keeping the lights on and the taps running involves the greater We (i.e., all of us).
Almost a year ago, we proposed a set of principles for open scholarly infrastructure based on discussions over the past decade or so. Our intention was to generate conversation amongst funders, infrastructure players, tool builders, all those who identify as actors in the scholarly ecosystem. We also sought test cases for these principles, real world examples that might serve as reference models and/or refine the set of principles.
One common question emerged from the ensuing discussions in person and online, and we realized we ducked a fundamental question: “what exactly is infrastructure“? In our conversations with scholars and others in the research ecosystem, people frequently speak of “infrastructures†to reference services or tools that support research and scholarly communications. The term is gaining currency as more scholars and developers are turning their attention to a) the need for improved research tools and platforms that can be openly shared and adopted and b) that sense that some solutions are interoperable and more efficiently implemented across communities (for example, see this post from Bill Mills).
It is exciting for us that the principles might have a broader application and we are more than happy to talk with groups and organisations that are interested in how the principles might apply in these setting. However our interest was always in going deeper. The kinds of “infrastructures†– we would probably say “services†– that Bill is talking about rely on deeper layers. Our follow-up blog post was aimed at addressing the question, but it ended with a koan:
“It isn’t what is immediately visible on the surface that makes a leopard a leopard, otherwise the black leopard wouldn’t be, it is what is buried beneath.â€
Does making the invisible visible require an infrared camera trap or infrastructure rodeo competitions? Thankfully, no. But we do continue to see the need to shine a light on those deeper underlying layers to reveal the leopard’s spots. This is the place where we feel the most attention is needed, precisely because these layers are invisible and largely ignored. We have started to use the term “foundational infrastructure” to distinguish these deeper layers, that for us need to be supported by organisations with strong principles.
The important layers applicable to foundational infrastructure seem to be:
Storage: places to put stuff that is generated by research, including possibly physical stuff
Identifiers: means of uniquely identifying each of the – sufficiently important – objects the research process created
Metadata: information about each of these objects
Assertions: relationships between the objects, structured as assertions that link identifiers
This is just a beginning list and some might object to the inclusion of one or more on the list. Certainly many will object to some that are missing and certainly none would fully qualify as compliant with the principles. Some have a disciplinary focus, some are at least perceived to be controlled by or serving specific stakeholder interests rather than the community as a whole. That “perceived to be” can be as important as real issues of control. If an infrastructure is truly foundational it needs to be trusted by the whole community. That trust is the foundation in a very real sense, the core on which the SIMA infrastructures should sit.
We originally avoided a list of names as we didn’t want to give the impression of criticising specific organisations against a set of principles we still think of as being at a draft stage. Now we name these examples because we’d like to elevate the conversation on the importance of these foundational infrastructures and the organisations that support them. Some examples may never fit the community principles. Some might with changes in governance or focus. The latter are of particular interest: what would those changes look like and how can we identify those infrastructures which are truly foundational? Institutional support for these organisations in the long run is a critical community discussion.
At the moment, numerous cross-stakeholder initiatives for new services are being developed, and in many cases being hampered by the lack of shared, reliable, and trusted foundations of SIMA infrastructures. Where these infrastructures do exist, initiatives take hold and thrive. Where they are patchy, we struggle. At the same time these issues are starting to be recognised more widely, for instance in the technology world where Nadia Eghbal recently left a venture capital firm to investigate important projects invisible to VCs. She identified Open Source Infrastructure, as a class of foundational projects “which tech simply cannot do without” but which are generally without any paths to funding.
Identifying foundational infrastructure – an institutional construct – is neither an art nor a science. There’s no point in drawing lines in the sand for its own sake. This question is more a means to a greater end if we take a holistic point of view: how do we create a healthy, robust ecosystem of players that support and enable scholarly communications? We know all of these layers are necessary, each with different roles they play and serving distinct communities. They each have different paths for setting up and sustainability. It is precisely the fact that these common needs are boring that means they starts to disappear from view, in some cases before they even get built. Understanding the distinctions between these two layers will help us better support both of them.
The other option is to forget where the pipes are, and to have to call in someone to find them again.
Over, and over, and over again…
Credits:
cowboy hat by Lloyd Humphreys from the Noun Project, used here under a CC-BY license
tower by retinaicon from the Noun Project, used here under a CC-BY license
The authors are writing in a personal capacity. None of the above should be taken as the view or position of any of our respective employers or other organisations.
I’m not much for end of year or beginning of year posts but I have found that putting down plans is a good way of holding myself to account (and that a few people out there might help with that job…you know who you are). I also think my use of this space may change a little over the coming year, so for those of you still using RSS (yes! we do still exist!) this may have an impact on including me or not in your selection for 2016.
As it stands at the moment I’ve got two major projects for the year ahead. The first, which is the best defined, is supporting a pilot program on Research Data Sharing for the International Development Research Centre a Canadian funder of development research. This is really interesting because we’ll be testing the challenges of data sharing in real projects that interface with local issues in many corners of the world. We’re expecting a range of outputs from the project and I’m hoping the majority of those will be published or made public in some form. And some of these I’ll be sharing in progress here as we go. More details on that later.
The second major project is to bed down the academic work I’m planning with colleagues from Curtin University and other places. If you’re a regular reader here you will have seen elements of this already. The series I’m (intermittently) working on on the Political Economics of Scholarly Publishing is one piece of this as are the ideas swirling around in the talk I gave at City University for OA Week last year. The work our group from the Triangle SCI Workshop last year is doing is coming along nicely and should generate some interesting outputs soon and I’m hopeful of kicking off some more projects around the convergence of research communities, scholarly societies, and publishing venues (the artist formerly know as “the journal”).
There’s exciting stuff ranging from high theory (are the critical tradition in humanities and scientific empiricism actually the same thing from two different perspectives? what is reproducibility really?) to economics and politics (if we think of communities and journals as clubs what does that tell us about viable models of financing and governance? what should a C21 research institution look like?) to the application of data analytics to the growing information streams in scholarly communications (how can we actually use this data to support good decisions and figure out how to communicate more effectively? what infrastructures do we need and how do we make that work?).
In all of this I want to try and apply the theory we develop about communities and their viability, and networks and information, to the actual process of doing the work. What would a distributed research group/think tank/consultancy look like? How could a diffuse but dynamic network of people work effectively together on problems that are simultaneously scholarly research and practical implementation issues? And of course the perennial question for any academic; how do you actually fund that?
I’m more and more convinced that the answer to that lies in finding the right combination of baseline activities – keeping things turning over, writing regularly, keeping the lights on – with focussed periods of concentrated activity, probably in person with the right team for the job, in which the real intellectual work gets done and the progress gets made.
So what does that mean in terms of what will appear here? My current focus is to pull together a piece that draws a line under all the things I’ve been doing over the past ten years. Not so as to stop them, but so as to understand where they are. Even what they are to some extent. More on that at a later date. I want to try and add one post at least every two weeks the Political Economics series. I know various people are watching that; feel free to hold me to that promise if I start to slip!
I’m also going to go back a bit more to the original purpose of this blog (haven’t called it that in a while!). Thinking out loud was a big part of my original intent and as I grapple – naively – with new areas and ideas I’m going to try and post what seems interesting to me more as it comes. I expect to be told that a lot of this isn’t new, but one thing I’ve learnt is that the best way to be told where to look is to say something that is wrong (or at least insufficiently informed).
Alongside that, expect more of the usual as well. The talk texts, the complaints, and the commentaries. And, I hope, the responses and ideas that make this worthwhile from my perspective.
Spectral human karyotype (Photo credit: Wikipedia)
I’ve been engaged in different ways with some people in the rare genetic disease community for a few years. In most cases the initial issue that brought us together was access to literature and in some cases that lead towards Open Science issues more generally. Many people in the Open Access space have been motivated by personal stories and losses, and quite a few of those relate to rare genetic diseases.
I’ve heard, and relayed to others how access has been a problem, how the structure and shape of the literature isn’t helpful to patients and communities. At an intellectual level the asymmetry of information for these conditions is easy to grasp. Researchers and physicians are dealing with many different patients with many different conditions, the condition in question is probably only a small part of what they think about. But for the patients and their families the specific condition is what they live. Many of these people actually become far more expert on the condition and the day to day issues that one particular patient experiences, but that expertise is rarely captured in the case studies and metastudies and reviews. The problem can be easily understood. But for me it’s never been personal.
That changed on Christmas Eve, when a family member got a diagnosis of a rare chromosomal mosaic condition. So for the first time I was following the information discovery pathway that I’ve seen many others work their way through. Starting with Google I moved to Wikipedia, and then onto the (almost invariably US-based) community networks for this condition. From the community site and its well curated set of research articles (pretty much entirely publisher PDFs on the community website) I started working through the literature. At first I hit the access barrier. For what it’s worth I found an embargoed copy of one of the articles in a UK Institutional Repository with a “request a copy” button. Copy requested. No response two weeks later. I keep forgetting that I now actually have a university affiliation and Curtin University has remarkably good journal holdings, but its a good reminder of how normal folk live.
Of course once I hit the literature I have an advantage, having a background in biomedicine. From the 30-odd case studies I got across to the OMIM Database (see also the Wikipedia Entry for OMIM) which netted me a total of two articles that actually looked across the case studies and tried to draw some general conclusions about the condition from more than one patient. I’m not going to say anything about the condition itself except that it involves mosaic tetrasomy, and both physical and intellectual developmental delay. One thing that is clear from the two larger studies is that physical and intellectual delays are strongly correlated. So understanding the variation in physical delay amongst the groups of patients, and where my family members sits on this, becomes a crucial question. The larger studies are…ok…at this but certainly not as easy to work with. The case studies are a disaster.
The question for a patient, or concerned family member, or even the non-expert physician faced with a patient, is what does the previously recorded knowledge tell us about likely future outcomes. Broad brush is likely the best we’re going to do given the low occurrence of the condition but one might hope that the existing literature would help. It doesn’t. The case studies are worse than useless, telling an interesting story about a patient who is not the same. Thirty case studies later all I know is that the condition is highly variable, that it seems to be really easy to get case studies published and that there is next to no coordination in data collection. The case studies also paint a biased picture. There could be many mild undiagnosed cases out there, so statistics from the case studies, even the larger studies would be useless. Or there might not be. Its hard to know but what is clear is how badly the information is organised if you want to get some sense of how outcomes for a particular patient might pan out.
None of this is new. Indeed many people from many organisations have told me all of this over many years. Patient organisations are driven to aggregating information, trying to ride herd on the researchers and physicians to gather representative data. They organise their own analyses, try to get a good sample of information, and in general structure information in a way that is actually useful to them. What’s new is my own reaction – these issues get sharper when they’re personal.
But even more than that it seems like we’ve got the whole thing backwards somehow. The practice of medicine matters and large amounts of resources are at stake. That means we want good evidence on what works and what doesn’t. To achieve this we use randomised control trials as a mechanism to prevent us from fooling ourselves. But the question we ask in these trials, that we very carefully structure things to ask, is “all things being equal, does X do Y”? Which is not the question we, or a physician, or a patient, want the answer to. We want the answer to “given this patient, here and now, what are the likely outcomes”? And the structure of our evidence actually doesn’t, I suspect can’t, answer that question. This is particularly true of rare conditions, and particularly those that are probably actually many conditions. In the end every treatment, or lack thereof, is an N=1 experiment without a control. I wonder how much, even under the best conditions, the findings of RCTs, of the abstract generalisation, actually help a physician to guide a patient or family on the ground?
There’s more to this than medicine, it actually cuts to the heart of the difference between science and humanities; the effort to understand a specific context and its story vs the effort to generalise and abstract, to understand the general. Martin Eve has just written a post that attacks this issue from the other end, asking the question whether methodological standards from the sciences, those very same standards that drive the design of randomised control trials, can be applied to literary analysis. The answer likely depends on what kinds of mistakes you want to avoid, and in what context do you want your findings to be robust. Like most of scholarship the answer is probably to be sure we’re asking the right question. I just happened to personally discover how at least some segments of the clinical research literature are failing to do that. And again, none of this is new.
It seems like a very long time ago that I got involved in the efforts to develop an ID system for contributors to research outputs. A post from 2009 seems to be the earliest I wrote about it alongside a summary from a few weeks later (ironically, given the discussion a summary for which most of the links are broken). I’ve been doing a lot of looking at old posts recently and those two illustrate an interesting turning point. In the first of the two there’s a somewhat idealised and naive technical proposal, and an evident distrust of the idea that publishers (or a publisher organisation like Crossref) should take the lead. In the second there is a rather more pragmatic perspective and (discounting the…ah…lets just say somewhat superseded technical ideas) a summary that ends with two sharp points.
Publishers and funders will have to lead. The end view of what is being discussed here is very like a personal home page for researchers. But instead of being a home page on a server it is a dynamic document pulled together from stuff all over the web. But researchers are not going to be interested for the most part in having another home page that they have to look after. Publishers in particular understand the value (and will get most value out of in the short term) unique identifiers so with the most to gain and the most direct interest they are best placed to lead, probably through organisations like CrossRef that aggregate things of interest across the industry. Funders will come along as they see the benefits of monitoring research outputs, and forward looking ones will probably come along straight away, others will lag behind. The main point is that pre-populating and then letting researchers come along and prune and correct is going to be more productive than waiting for ten millions researchers to sign up to a new service.
The really big question is whether there is value in doing this specially for researchers. This is not a problem unique to research and one in which a variety of messy and disparate solutions are starting to arise. Maybe the best option is to sit back and wait to see what happens. I often say that in most cases generic services are a better bet than specially built ones for researchers because the community size isn’t there and there simply isn’t a sufficient need for added functionality. My feeling is that for identity that there is a special need, and that if we capture the whole research community that it will be big enough to support a viable service. There is a specific need for following and aggregating the work of people that I don’t think is general, and is different to the authentication issues involved in finance. So I think in this case it is worth building specialist services.
Fast forward seven years and these still seem the core to the adoption problem. It was publishers (and a smaller number of forward thinking funders) that drove ORCID forward. It is still a problem getting across that an ORCID is not “just another profile” and the way in which institutions and services have implemented that hasn’t helped. The particular use case that is researchers I think has been answered in the way that ORCID can be made to work, the public API, the data dumps and the principle of Open Data, all offer opportunities across the research ecosystem that are only beginning to be worked out.
Achieving critical mass remains the question. The real benefits from being able to link outputs and contributors only comes when the graph of links between them is open. And as with all changes there is the question of who should push that, when; and how hard. Institutions could have, but have largely dropped the ball. Looking at the countries listed in affiliations in the most recent data dump suggests that where there is a strong national agenda to use ORCID that adoption is high (you need to zoom in to see but I find the adoption in some South American countries striking).
https://plot.ly/~CameronNeylon52d7/22
National adoption is slow, meaning publishers and funders need to take a lead. One thing I got wrong in that summary was the assumption that publishers would get the most short term benefits from adoption of contributor IDs. That may be true in the medium term as we get to critical mass, but in the short term those publishers taking a stance on this are actually taking a risk. It costs money to implement, it will involve some addition friction for authors, and it will take time to deliver benefits, both for publishers and authors. One of the best parts of this announcement is the commitment to using the ORCID API to populate the information. Done right this will reduce the burden for authors in submitting, improve the quality of bibliographic metadata in general, and make it easier for researchers to report outputs to institutions and funders.
I believe in ORCID as a way to create an open and community owned basis for building better and cheaper systems and services for research communication. There are risks and potential problems along the way. But the alternative is just to see us continue down the road where the data itself is owned and controlled by corporate interests. That data ought to be in the hands of the community, and through that we can work to build lower cost systems that support both relevant and cost effective services for a global system of research communications. The eight publishers engaging in taking that forward deserve credit for working together in a way that supports the whole community.

 This is a short reflection on a new Working Paper I’m an author on. The paper is largely the work of Jason Potts with contributions from myself, Lucy Montgomery, Ellie Rennie, and John Hartley.Â
This is a short reflection on a new Working Paper I’m an author on. The paper is largely the work of Jason Potts with contributions from myself, Lucy Montgomery, Ellie Rennie, and John Hartley. 




 You probably don’t think too much about where all the services to your residence run. They go missing from view until something goes wrong. But how do we maintain them unless they are identified? An entire utilities industry, which must search for utility infrastructure, hangs in the balance on this knowledge. There’s even
You probably don’t think too much about where all the services to your residence run. They go missing from view until something goes wrong. But how do we maintain them unless they are identified? An entire utilities industry, which must search for utility infrastructure, hangs in the balance on this knowledge. There’s even 