
When it comes to getting data up on the web, I am actually a great optimist. I think things are moving in the right direction and with high profile people like Tim Berners-Lee making the case, the with meme of “Linked Data” spreading, and a steadily improving set of tools and interfaces that make all the complexities of RDF, OWL, OAI-ORE, and other standards disappear for the average user, there is a real sense that this might come together. It will take some time; certainly years, possibly a decade, but we are well along the road.
I am less sanguine about our ability to record the processes that lead to that data or the process by which raw data is turned into information. Process remains a real recording problem. Part of the problem for this is just that scientists are rather poor at recording process in most cases, often assuming that the data file generated is enough. Part of the problem is the lack of tools to do the recording effectively, the reason why we are interested in developing electronic laboratory recording systems.
Part of it is that the people who have been most effective at getting data onto the web tend to be informaticians rather than experimentalists. This has lead in a number of cases to very sophisticated systems for describing data, and for describing experiments, that are a bit hazy about what it is they are actually describing. I mentioned this when I talked about Peter Murray-Rust and Egon Willighagen’s efforts at putting at UsefulChem experiments into Chemistry Markup Language. While we could describe a set of results we got awfully confused because we weren’t sure whether we were describing a specific experiment, the average of several experiments, or a description of what we thought was happening in the experiments. This is not restricted to CML. Similar problems arise with many of the MIBBI guidelines where the process of generating the data gets wrapped up with the data file. None of these things are bad, it is just that we may need some extra thought about distinguishing between classes and instances.
In the world of linked data Process can be thought of either as a link between objects, or as an object in its own right. The distinction is important. A link between, say, a material and data files, points to a vocabulary entry (e.g. PCR, HPLC analysis, NMR analysis). That is the link creates a pointer to the class of a process, not to a specific example of carrying out that process. If the process is an object in its own right then it refers reasonably clearly to a specific instance of that process (it links this material, to that data file, on this date) but it breaks the links between the inputs and outputs. While RDF can handle this kind of break by following the links though it creates the risk of a rapidly expanding vocabulary to hold all the potential relationships to different processes.There are other problems with this view. The object that represents the process. Is it a a log of what happened? Or is it the instructions to transform inputs into outputs? Both are important for reproducibility but they may be quite different things. They may even in some cases be incompatible if for some reason the specific experiment went off piste (power cut, technical issues, or simply something that wasn’t recorded at the time, but turned out to be important later).
The problem is we need to think clearly about what it is we mean when we point at a process. Is it merely a nexus of connections? Things coming out, things going in. Is it the log of what happened? Or is it the set of instructions that lets us convert these inputs into those outputs. People who have thought about this from a vocabulary of informatics perspective tend to worry mostly about categorization. Once you’ve figure out what the name of this process is and where it falls in the heirachy you are done. People who work on minimal description frameworks start from the presumption that we understand what the process is (a microarray experiment, electrophoresis etc). Everything within that is then internally consistent but it is challenging in many cases to link out into other descriptions of other processes. Again the distinction between what was planned to be done, and what was actually done, what instructions you would give to someone else if they wanted to do it, and how you would do it yourself if you did it again, have a tendency to be somewhat muddled.
Basically process is complicated, and multifaceted, with different requirements depending on your perspective. The description of a process will be made up of several different objects. There is a collection of inputs and a collection of outputs. There is a pointer to a classification, which may in itself place requirements on the process. The specific example will inherit requirements from the abstract class (any PCR has two primers, a specific PCR has two specific primers). Finally we need the log of what happened, as well as the “script” that would enable you to do it again. On top of this for a complex process you would need a clear machine-readable explanation of how everything is related. Ideally a set of RDF statements that explain what the role of everything is, and links the process into the wider web of data and things. Essentially the RDF graph of the process that you would use in an idealized machine reading scenario.
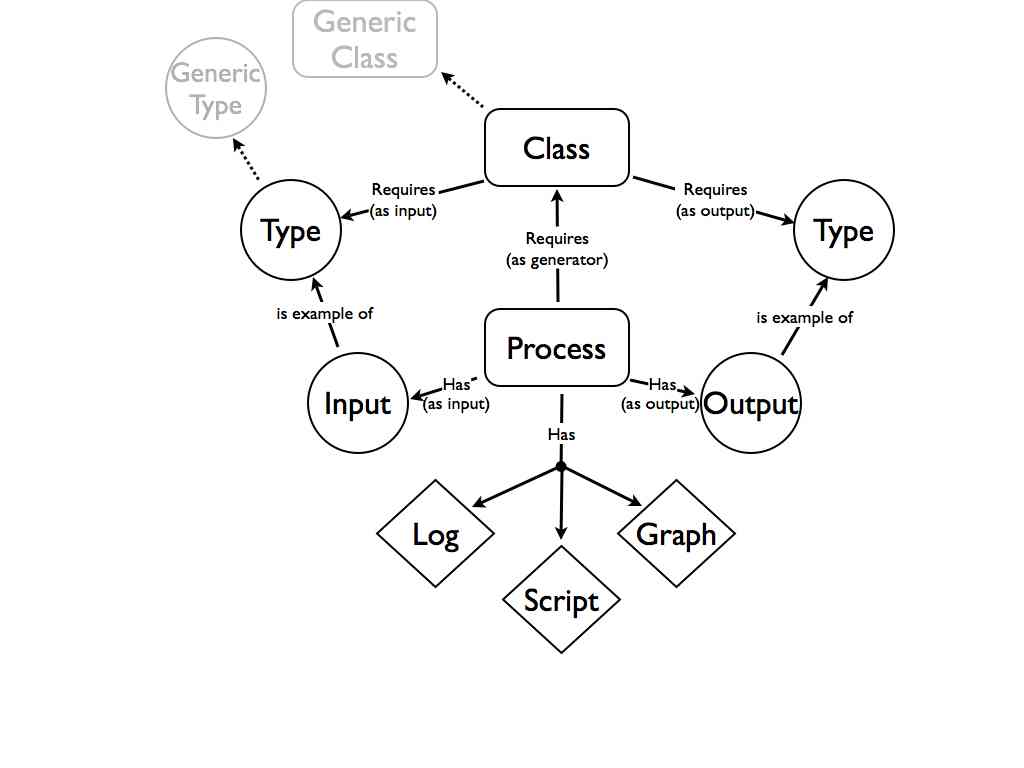
This is all very abstract at the moment but much of it is obvious and the rest I will try to tease out by example in the next post. At the core is the point that process is a complicated thing and different people will want different things from it. This means that it is necessarily going to be a composite object. The log is something that we would always want for any process (but often do not at the moment). The “script”, the instructions to repeat the process, whether it be experimental or analytical is also desirable and should be accessible either by stripping the correct commands out of the log, or by adapting a generic set of instructions for that type of process. The new things is the concept of the graph. This requires two things. Firstly that every relevant object has an identity that can be referenced. Secondly that we capture the context of each object and what we do to it at each stage of the process. It is building systems that capture this as we go that will be the challenge and what I want to try and give an example of in the next post.