The moment that I decided it was time to move on from PLOS is crystal clear in my mind. I was standing in a room at the South of Perth Yacht Club, giving a short talk on my view of the political economics of journals and scholarly publishing. I’d been puzzling for a while about a series of things. Why wasn’t the competitive market we predicted in APCs emerging? What was it that made change in the research communities so hard? How do we move from talking about public access to enabling public use? And how do we decide where to invest limited resources? What is thing we call culture and why is changing it hard? The people working on a program they called Cultural Science seemed to have some interesting approaches to this, so when they asked me to the workshop I gladly came.
It was a small group, so I was speculating. What if instead of treating knowledge as a public good we acknowledged that it is born exclusive? Knowledge can’t exist with just one person knowing, it must be held by a group. But it starts exclusive – held by the group – and when we choose to communicate it, publish it, open it up, translate or explain it we invest in making it less exclusive. I pointed to the exclusive – non-rivalrous quadrant of the classic goods diagram, labelled “toll goods” and said that the shift from a subscription journal (toll good) to Open Access was just one example of this kind of investment, that all of this “public-making” takes us towards the public good quadrant but that we never quite reach it. I might even have said we could do with a better name for that bottom right quadrant. Jason Potts, who was the other panelist in the session spoke up to say “…it has another name you know…they’re called ‘club goods'”.
That was the moment – we’d been talking about communities, cultures, economics, “public-making” but it was the word ‘club’ and its associated concepts, both pejorative and positive that crystalised everything. We were talking about the clubbishness of making knowledge – the term “Knowledge Clubs” emerged quickly – but also the benefits that such a club might gain in choosing to invest in wider sharing. John Hartley and Jason had laid much of the groundwork in connecting groups, culture, economics and communication in their book. What we might now have was a frame in which to interrogate why these clubs (research groups, disciplines, universities, but also journals) do what they do.
Pretty much everything since then flowed from that point. I’ve been frustrated for a long time with traditional economic analyses of scholarly publishing. They don’t seem to explain what actually happens, and fail to capture critical aspects of what is going on. The lens of club economics seems like it might help to capture more of the reality of what is going on. Jason has subsequently worked through this concept, laying out the issues and a new working paper is the result. This is at the idea stage, there is much detail to be worked out, but what the club formulation does is place group dynamics at the centre of the frame. Treating articles as simple supply and demand objects (which they’re not) at equilibrium (which they’re generally not) within the background of some sort of market (which the research community isn’t) leaves the important pieces, the messy human interactions, prestige and reputation out of the equation. I’m not going to claim we have the answer to solving that, but we do at least have a new way of looking at the questions.
Once again, reproducibility is in the news. Most recently we hear that irreproducibility is irreproducible and thus everything is actually fine. The most recent round was kicked off by a criticism of the Reproducibility Project followed by claim and counter claim on whether one analysis makes more sense than the other. I’m not going to comment on that but I want to tease apart what the disagreement is about, because it shows that the problem with reproducibility goes much deeper than whether or not a particular experiment replicates.
At the centre of the disagreement are two separate issues. The most easy to understand is the claim that the Reproducibility Project did not faithfully replicate the original studies. Of course this raises the question of what “replicate” means. Is a replication seeking to precise re-run the same test or to test the claim more generally? Being fuzzy about which is meant lies at the bottom of many disagreements about whether as experiment is “replicated”.
The second issue is the one that has generated the most interesting commentary, but which is the hardest for a non-expert to tease apart. At its core is a disagreement over how “replication” should be statistically defined. That is, what is the mathematical analysis to be applied to an original test, and its repeat, to provide a Yes/No answer to the question “did it replicate”. These issues were actually raised from the beginning. It is far from obvious what the right analysis would be, or indeed whether the idea of “a right answer” actually makes sense. That’s because, again, there are serious differences of definition in what is meant by replication, and these questions cut to the core of how we use statistics and mathematics to analyse the world in which our experiments are run.
Problems of language I: Levels of replication and re-test
When there is a discussion of terminology it often focusses around this issue. When we speak of “replicating” an experiment do we mean carrying it out exactly the same, at its most extreme simply re-running a computational process in “exactly the same” environment, in the laboratory perhaps using the same strains, primers, chemicals or analytical techniques? Or do we mean doing “the same” experiment but without quite the same level of detail, testing the precise claim but not the precise methodology, perhaps using a different measurement technique, differing antibodies, or an alternative statistical test or computational algorithm. Or perhaps we mean testing the general claim, not that this test in this mouse strain delivers this result, but that chemical X is a regulator of gene YÂ in general.
Often we make a distinction between “replicating” and “reproducing” a result which corresponds to the distinction between the first and second level. We might need a third term, perhaps “generalising” to describe the third. But the ground between these levels is a quagmire and depending on your concerns you might categorise the same re-test as a replication or a reproduction. Indeed this is part of the disagreement in the current case. Is it reasonable to call a re-test of flag priming in a different culture? One group might say that are testing the general claim made for flag priming but is it the same test if the group is different, even if the test is identical? What is test protocol and what is subject. Would that mean we need to run social psychology replications on the same subjects?
Problems of language II: Reproducible experiments should not (always) reproduce
The question of what a direct replication in social pyschology would require is problematic. It cuts to the heart of the claims that social pyschology makes, that it detects behaviours and modes of thinking that are general. But how general and across what boundaries? Those questions are ones that social pyschologists probably have intuitive answers for (as do stem cell biologists, chemists and economists when faced with similar issues) but not ones that are easy, or perhaps even possible, to explain across disciplinary boundaries.
Layered on top of this are differences of opinion, suspicions about probity and different experiences within each of these three categories. Do some experiments require a “craft” or “green fingers” to get right? How close should a result be to be regarded as “the same”? What does a well designed experiment look like? What is the role of “elegance”? Disagreements about what matters, and ultimately rather different ideas about what the interaction between “reality” and “experiment” looks like also contribute. In the context of strong pseudo- and anti-science agendas having the complex discussion about how we judge which contradictory results to take seriously seems to be challenging. These problems are hard because tackling them requires dealing with the social aspects of science in a way that many scientists are uncomfortable with.
Related to this is the point raised above, that its not clear what we mean by replication. Given that this often relates to claims that are supported by p-values, we should first note that these are often mis-used, or at very least misrepresented. Certainly we need to get away from “p = 0.05 means its 95% reliable”. The current controversy rests in part on the question of the distinction between the replication experiment providing a result in the 95% confidence interval of the initially reported effect size, or that initially reported effect size lying in the 95% confidence interval of the replication. Both arguments can lead to some fairly peculiar results. An early criticism of the initial Reproducibility Project paper suggested a Bayesian approach to testing reproducibility but that had its own problems.
At the core of this is a fundamental problem in science. Even if a claim is “true” we don’t expect to get the same results from the same experiment. Random factors, uncontrolled factors all can play a role. This is why we do experiments and repeat them and do statistical analysis. It’s a way of trying to ensure we don’t fool ourselves. But it increasingly seems that we’re facing a rather toxic mixture of the statistical methods not being up to the job, and the fact that many of us are not up to the job of using them properly. That fact that the vast majority of us researchers using those statistical tools aren’t qualified to figure out which is probably instructive.
Either way it shouldn’t be surprising that if there isn’t a clear definition of what it means for a repeated test “to replicate” a previous one that the way we talk about these processes can get confusing.
Problems in philosophy and language: Turtles all the way down
When people talk about the “reproducibility” of a claim they’re actually talking about at least four different kinds of things. The first is whether it is expected that additional tests will confirm a claim. That is, is the claim “true” in some sense. The second is whether a specific re-run of a specific trial will (or did) give “the same” result. The third is whether the design or a trial (or its analysis) is such that repeated trials would be expected to give the same result (whatever that is). That is, is the experiment properly designed so as to give “reliable” results. Finally we have the question of whether the description of an experiment is sufficiently good to allow it to be re-run.
That the relationship between “truth” and empirical approaches that use repeated testing to generating evidence to support claims is a challenging problem is hardly a new issue in the philosophy of science. The question of whether the universe is reliable is a question asked in a social context by humans, and the tests we run to try and understand that universe are designed by humans with an existing context. But equally those tests play out in an arena that appears to have some consistencies. Technologies, for good or ill, tend to work when built and tested, not when purely designed in the abstract. Maths seems useful. It really is turtles all the way down.
However, even without tackling the philosophical issues there are some avenues for solving problems of the language we use. “Reproducible” is often used as interchangeable with “true” or even “honest”. Sometimes it refers to the description of the experiment, sometimes to the ability of re-tests to get the same result. “Confidence” is often referred to as absolute, not relative, and discussed without clarity as to whether it refers to the claim itself or the predicted result of a repeated test. And all of these are conflated across the various levels of replication, reproduction and generalisation discussed above.
Problems of description vs problems of results
Discussion of whether an article is “replicable” can mean two quite different things. Is the description of the test sufficient to enable it be re-run (or more precisely, does it meet some normative standard of community expectation of sufficient description)? This is a totally different question to the one of what is expected (or happens) when such a test is actually re-run. Both in turn are quite different, although there is a relation, to the question of whether the test is well designed, either to generate consistently the same result, or to provide information on the claim.
Part of the solution may lie in a separation of concerns. We need much greater clarity in the distinction between “described well enough to re-do” and “seems to be consistent in repeated tests”. We need to maintain those distinctions for each of the different levels above: replication, reproduction and generalisation. All of these in turn are separate to the question of whether a claim is true, or the universe (or our senses) reliable, or the social context and power relations that guided the process of claim making and experiment. It is at the intersections between these different issues that things get interesting: does the design of an experiment may answer a general question, or is it much more specific? Is the failure to get the same result, or our expectation of how often we “should” get the same result a question of experimental design, what is true, or the way our experience guides us to miss, or focus on specific issues? In our search for reliable, and clearly communicated, results have we actually tested a different question to the one that really matters?
A big part of the problem is that by using sloppy language we make it unclear what we are talking about. If we’re going to make progress there will need to be a more precise, and more consistent way of talking about exactly what problem is under investigation at any point in time.
This is a working through of some conversations with a range of people, most notably Jennifer Lin. It is certainly not original – and doesn’t contain many answers – but is an effort to start organising thoughts around how to talk about the problems around reproducibility, which is after all the interesting problem. Any missing links and credits entirely my own fault and happy to make corrections.
European flag outside the Commission (Photo credit: Wikipedia)
The following is my application to join the European Commission Open Science Policy Platform. The OSPP will provide expert advice to the European Commission on implementing the broader Open Science Agenda. As you will see some of us have a concern that the focus of the call is on organisations, rather than communities. This is a departure from much of the focus that the Commission itself has adopted on the potential benefits and opportunities of Open Science. A few of us are therefore applying as representatives of the community of interested and experienced people in the Open Science space.
I am therefore seeking endorsement, in the form of a comment on this post or email directly to me if you prefer, as someone who could represent this broader community of people, not necessarily tied to one type of organisation or stakeholder. This being an open form you are also of course free to not endorse me as well :-)
I am writing to apply for membership of the Open Science Policy Platform as a representative of the common interest community of Open Science developers and practitioners. This community is not restricted to specific organisations or roles but includes interested people and organisations from across the spectrum of stakeholders including researchers, technologists, publishers, policy makers, funders and all those interested in the change undergoing research.
I have a concern that the developing policy frameworks and institutionalisation of Open Science are leaving behind precisely the community focus that is at the heart of Open Science. As the Commission has noted, one of the key underlying changes leading to more open practice in research is that many more people are becoming engaged in research and scholarship in some form. At the same time the interactions between this growing diversity of actors increasingly form an interconnected network. It is not only that this network reaches beyond organisational and sector boundaries that is important. We need to recognise that it is precisely that blurring of boundaries that underpins the benefits of Open Science.
I recognise that for practical policy making it is essential to engage with key stakeholders with the power to make change. In addition I would encourage the Commission to look beyond the traditional sites of decision making power within existing institutions to the communities and networks which are where the real cultural changes are occurring. In the end, institutional changes will only ever be necessary, and not sufficient, to support the true cultural change which will yield the benefits of Open Science.
I am confident I can represent some aspects of this community particularly in the areas of:
New models for research communications
Incentives and rewards that will lead to cultural change
The relationship between those incentives and research assessment.
To provide evidence of my relevance to represent this common interest I have posted this application publicly and asked for endorsement by community members.
I have a decade of relevant experience in Open Science. I have long been an advocate of radical transparency in research communication including being of the early practitioners of Open Notebook Science. I have been involved in a wide range of technical developments over the past decade in data management, scholarly communications and research assessment and tracking. I have been engaged in advising on policy development for Open Access, Open Data and open practice more generally for a wide range of institutions, funders and governments. I am also one of the authors of three key documents, the altmetrics manifesto, the Panton Principles, and the Principles for Open Scholarly Infrastructures.
As an advocate for Open Access and Open Data I have been involved in developing the arguments for policy and practice change in the UK, US and Europe. As Advocacy Director at PLOS (2012-2015) I was closely involved in developments on Open Access in particular. My team lead the coalition that supported the Californian Open Access bill and I testified before the UK House of Commons BIS committee. Submissions to the Commons Enquiry, the HEFCE Metrics Tide report, and the EU Expert Group on Copyright Reform all had an influence on the final text.
In 2015 I returned to academia, now in the humanities. In this capacity I am part of a small group looking critically at Open Science. I am an advisor for Open and Collaborative Science in Development Network, a research project looking at the application of Open Science practice in development contexts, as well as leading a pilot project for the International Development Research Centre on implementing Data Sharing practice amongst grantees. My research is focussing on how policy, culture and practice interact and how an understanding of this interaction can help us design institutions for an Open Science world.
I therefore believe I am well placed to represent a researcher, developer, and practitioner perspective on the OSPP as well as to bring a critical view to how the details of implementation can help to bring about what it is that we really want to achieve in the long term, a cultural change that embraces the opportunity of the web for science.
I promised some thinking out loud and likely naive and uninformed opinion in my plans for the new year. Here’s a start on that with apologies to Science and Technology Studies and Cultural Studies people who’ve probably thought all of this through. Yes, I am trying to get people to do my due diligence literature review for me.
Cultures of Pseudomonas syringae  (Photo credit: Wikipedia)
It’s a common strand when we talk about improving data sharing or data management, or access to research, or public engagement…or… “Cultural Change, its hard”. The capitals are deliberate. Cultural Change is seen as a thing, perhaps a process that we need to wait for, because we have internalised the Planck narrative that “science progresses one funeral at a time”1. Yet we are also still waiting for the Google generation with their “culture of sharing” to change the world for us.
Some of us get bored waiting and look for hammers. We decide that policies, particularly funder policies, but also journal or institutional policies requiring data sharing, are the best way to drive changes in practice. And these work, to some extent, in some places, but then we (and I use the “we” seriously) are disappointed when changes in practice turn out to be the absolute minimum that has to be done; that the cultural change that we assumed would follow does not, even in some cases is hampered by an association of the policy with all those other administrative requirements that we (again, I use the word advisedly) researchers complain are burying us, preventing us from getting on with what we are supposed to be doing.
We (that word again) point at the successes. Look at the public genome project and the enormous return on investment! Look at particle physics! Mathematics and the ArXiv. The UK ESRC and the UK Data Archive, the ICPSR! Why is it that the other disciplines can’t be like them? It must be a difference in culture. In history. In context. And we make up stories about why bioinformatics is different to chemistry, why history isn’t more like economics. But the benefits are clear. Data sharing increases impact, promotes engagement, improves reproducibility, leads to more citations, enhances career prospects and improves skin tone. Some of these even have evidence to back them up. Good data management and sharing practice has real benefits that have been shown in specific contexts and specific places. So its good that we can blame issues in other places, and other contexts, on “differences of culture”. That makes the problem something that is separate from what we believe to be objectively best practice that will drive real measurable outcomes.
Then there are the cultural clashes. When the New England Journal of Medicine talked about the risk of communities of “research parasites” arising to steal people’s research productivity the social media storm was immense. Again, observers trying not to take sides might point to the gulf in cultures between the two camps. One side committed to the idea that data availability and critique is the bedrock of science, although not often thinking deeply about what is available to who, or for what or when. Just lots, for everyone, sooner! On the other a concern for the structure of the existing community, of the quality of engagement, albeit perhaps too concerned with the stability of one specific group of stakeholders. Should the research productivity of a tenured professor be valued above the productivity of those critiquing whether the drugs actually work?
In each of these cases we blame “culture” for things being hard to change. And in doing so we externalise it, make it something that we don’t really engage with. It probably doesn’t help that the study of culture, and the way it is approached is alien to most with a sciences background. But even those disciplines we might to tackle these issues seem reticent to engage. Science and Technology studies appears to be focussed on questions of why we might want change, who is it for, what does the technology want? But seems to see cultures as a fixed background, focussing rather on power relations around research. Weirdly (and I can’t claim to have got far into this so I may be wrong) Cultural Studies doesn’t seem to deal with culture per se so much as seek to generalise stories that arise from the study of individuals and individual cases. Ethnography looks at individuals, sociology focusses on interactions, as does actor-network theory, rarely treating cultures or communities as more than categories to put things into or backgrounds to the real action.
It seems to me that if we’re serious about wanting to change cultures and not merely to wait for Cultural Change (with its distancing capitals) to magically happen then we need to take culture – and cultures – seriously. How do they interact and how do they change? What are the ways in which we might use all of the levers at our disposal: policy yes, but also evidence and analysis, new (and old) technology, and the shaping of the stories we tell ourselves and each other about why we do what we do. How can we use this to build positive change and coherent practice, while not damaging the differences in culture, and the consequent differences in approach, that enrich scholarship and its interaction withe communities it is carried out within?
The question of who “we” is in any given context, what cultures are we a part of, what communities is a challenging one. But I increasingly think if we don’t have frameworks for understanding the differing cultures amongst research disciplines and researchers and other stakeholders, how they interact, compete, clash and change, then we will only make limited progress. Working with an understanding of our own cultures is the lever we haven’t pulled, in large part because thinking about culture, let alone examining our own is so alien. We need to take culture seriously.
Cite as “Bilder G, Lin J, Neylon C (2016) Where are the pipes? Building Foundational Infrastructures for Future Services, retrieved [date], https://cameronneylon.net/blog/where-are-the-pipes-building-foundational-infrastructures-for-future-services/ ‎” You probably don’t think too much about where all the services to your residence run. They go missing from view until something goes wrong. But how do we maintain them unless they are identified? An entire utilities industry, which must search for utility infrastructure, hangs in the balance on this knowledge. There’s even an annual competition, a rodeo no less, to crown the best infrastructure locators in the land, rewarding those who excel at re-discovering where lost pipes and conduits run.
It’s all too easy to forget where the infrastructure lies when it’s running well. And then all too expensive if you have to call in someone to find it again. Given that preservation and record keeping lies at the heart of research communications, we’d like to think we could do a better job. Good community governance makes it clear who is responsible for remembering where the pipes run as well as keeping them “up to codeâ€. Turns out that keeping the lights on and the taps running involves the greater We (i.e., all of us).
Almost a year ago, we proposed a set of principles for open scholarly infrastructure based on discussions over the past decade or so. Our intention was to generate conversation amongst funders, infrastructure players, tool builders, all those who identify as actors in the scholarly ecosystem. We also sought test cases for these principles, real world examples that might serve as reference models and/or refine the set of principles.
One common question emerged from the ensuing discussions in person and online, and we realized we ducked a fundamental question: “what exactly is infrastructure“? In our conversations with scholars and others in the research ecosystem, people frequently speak of “infrastructures†to reference services or tools that support research and scholarly communications. The term is gaining currency as more scholars and developers are turning their attention to a) the need for improved research tools and platforms that can be openly shared and adopted and b) that sense that some solutions are interoperable and more efficiently implemented across communities (for example, see this post from Bill Mills).
It is exciting for us that the principles might have a broader application and we are more than happy to talk with groups and organisations that are interested in how the principles might apply in these setting. However our interest was always in going deeper. The kinds of “infrastructures†– we would probably say “services†– that Bill is talking about rely on deeper layers. Our follow-up blog post was aimed at addressing the question, but it ended with a koan:
“It isn’t what is immediately visible on the surface that makes a leopard a leopard, otherwise the black leopard wouldn’t be, it is what is buried beneath.â€
Does making the invisible visible require an infrared camera trap or infrastructure rodeo competitions? Thankfully, no. But we do continue to see the need to shine a light on those deeper underlying layers to reveal the leopard’s spots. This is the place where we feel the most attention is needed, precisely because these layers are invisible and largely ignored. We have started to use the term “foundational infrastructure” to distinguish these deeper layers, that for us need to be supported by organisations with strong principles.
The important layers applicable to foundational infrastructure seem to be:
Storage: places to put stuff that is generated by research, including possibly physical stuff
Identifiers: means of uniquely identifying each of the – sufficiently important – objects the research process created
Metadata: information about each of these objects
Assertions: relationships between the objects, structured as assertions that link identifiers
This is just a beginning list and some might object to the inclusion of one or more on the list. Certainly many will object to some that are missing and certainly none would fully qualify as compliant with the principles. Some have a disciplinary focus, some are at least perceived to be controlled by or serving specific stakeholder interests rather than the community as a whole. That “perceived to be” can be as important as real issues of control. If an infrastructure is truly foundational it needs to be trusted by the whole community. That trust is the foundation in a very real sense, the core on which the SIMA infrastructures should sit.
We originally avoided a list of names as we didn’t want to give the impression of criticising specific organisations against a set of principles we still think of as being at a draft stage. Now we name these examples because we’d like to elevate the conversation on the importance of these foundational infrastructures and the organisations that support them. Some examples may never fit the community principles. Some might with changes in governance or focus. The latter are of particular interest: what would those changes look like and how can we identify those infrastructures which are truly foundational? Institutional support for these organisations in the long run is a critical community discussion.
At the moment, numerous cross-stakeholder initiatives for new services are being developed, and in many cases being hampered by the lack of shared, reliable, and trusted foundations of SIMA infrastructures. Where these infrastructures do exist, initiatives take hold and thrive. Where they are patchy, we struggle. At the same time these issues are starting to be recognised more widely, for instance in the technology world where Nadia Eghbal recently left a venture capital firm to investigate important projects invisible to VCs. She identified Open Source Infrastructure, as a class of foundational projects “which tech simply cannot do without” but which are generally without any paths to funding.
Identifying foundational infrastructure – an institutional construct – is neither an art nor a science. There’s no point in drawing lines in the sand for its own sake. This question is more a means to a greater end if we take a holistic point of view: how do we create a healthy, robust ecosystem of players that support and enable scholarly communications? We know all of these layers are necessary, each with different roles they play and serving distinct communities. They each have different paths for setting up and sustainability. It is precisely the fact that these common needs are boring that means they starts to disappear from view, in some cases before they even get built. Understanding the distinctions between these two layers will help us better support both of them.
The other option is to forget where the pipes are, and to have to call in someone to find them again.
Over, and over, and over again…
Credits:
cowboy hat by Lloyd Humphreys from the Noun Project, used here under a CC-BY license
tower by retinaicon from the Noun Project, used here under a CC-BY license
The authors are writing in a personal capacity. None of the above should be taken as the view or position of any of our respective employers or other organisations.
Spectral human karyotype (Photo credit: Wikipedia)
I’ve been engaged in different ways with some people in the rare genetic disease community for a few years. In most cases the initial issue that brought us together was access to literature and in some cases that lead towards Open Science issues more generally. Many people in the Open Access space have been motivated by personal stories and losses, and quite a few of those relate to rare genetic diseases.
I’ve heard, and relayed to others how access has been a problem, how the structure and shape of the literature isn’t helpful to patients and communities. At an intellectual level the asymmetry of information for these conditions is easy to grasp. Researchers and physicians are dealing with many different patients with many different conditions, the condition in question is probably only a small part of what they think about. But for the patients and their families the specific condition is what they live. Many of these people actually become far more expert on the condition and the day to day issues that one particular patient experiences, but that expertise is rarely captured in the case studies and metastudies and reviews. The problem can be easily understood. But for me it’s never been personal.
That changed on Christmas Eve, when a family member got a diagnosis of a rare chromosomal mosaic condition. So for the first time I was following the information discovery pathway that I’ve seen many others work their way through. Starting with Google I moved to Wikipedia, and then onto the (almost invariably US-based) community networks for this condition. From the community site and its well curated set of research articles (pretty much entirely publisher PDFs on the community website) I started working through the literature. At first I hit the access barrier. For what it’s worth I found an embargoed copy of one of the articles in a UK Institutional Repository with a “request a copy” button. Copy requested. No response two weeks later. I keep forgetting that I now actually have a university affiliation and Curtin University has remarkably good journal holdings, but its a good reminder of how normal folk live.
Of course once I hit the literature I have an advantage, having a background in biomedicine. From the 30-odd case studies I got across to the OMIM Database (see also the Wikipedia Entry for OMIM) which netted me a total of two articles that actually looked across the case studies and tried to draw some general conclusions about the condition from more than one patient. I’m not going to say anything about the condition itself except that it involves mosaic tetrasomy, and both physical and intellectual developmental delay. One thing that is clear from the two larger studies is that physical and intellectual delays are strongly correlated. So understanding the variation in physical delay amongst the groups of patients, and where my family members sits on this, becomes a crucial question. The larger studies are…ok…at this but certainly not as easy to work with. The case studies are a disaster.
The question for a patient, or concerned family member, or even the non-expert physician faced with a patient, is what does the previously recorded knowledge tell us about likely future outcomes. Broad brush is likely the best we’re going to do given the low occurrence of the condition but one might hope that the existing literature would help. It doesn’t. The case studies are worse than useless, telling an interesting story about a patient who is not the same. Thirty case studies later all I know is that the condition is highly variable, that it seems to be really easy to get case studies published and that there is next to no coordination in data collection. The case studies also paint a biased picture. There could be many mild undiagnosed cases out there, so statistics from the case studies, even the larger studies would be useless. Or there might not be. Its hard to know but what is clear is how badly the information is organised if you want to get some sense of how outcomes for a particular patient might pan out.
None of this is new. Indeed many people from many organisations have told me all of this over many years. Patient organisations are driven to aggregating information, trying to ride herd on the researchers and physicians to gather representative data. They organise their own analyses, try to get a good sample of information, and in general structure information in a way that is actually useful to them. What’s new is my own reaction – these issues get sharper when they’re personal.
But even more than that it seems like we’ve got the whole thing backwards somehow. The practice of medicine matters and large amounts of resources are at stake. That means we want good evidence on what works and what doesn’t. To achieve this we use randomised control trials as a mechanism to prevent us from fooling ourselves. But the question we ask in these trials, that we very carefully structure things to ask, is “all things being equal, does X do Y”? Which is not the question we, or a physician, or a patient, want the answer to. We want the answer to “given this patient, here and now, what are the likely outcomes”? And the structure of our evidence actually doesn’t, I suspect can’t, answer that question. This is particularly true of rare conditions, and particularly those that are probably actually many conditions. In the end every treatment, or lack thereof, is an N=1 experiment without a control. I wonder how much, even under the best conditions, the findings of RCTs, of the abstract generalisation, actually help a physician to guide a patient or family on the ground?
There’s more to this than medicine, it actually cuts to the heart of the difference between science and humanities; the effort to understand a specific context and its story vs the effort to generalise and abstract, to understand the general. Martin Eve has just written a post that attacks this issue from the other end, asking the question whether methodological standards from the sciences, those very same standards that drive the design of randomised control trials, can be applied to literary analysis. The answer likely depends on what kinds of mistakes you want to avoid, and in what context do you want your findings to be robust. Like most of scholarship the answer is probably to be sure we’re asking the right question. I just happened to personally discover how at least some segments of the clinical research literature are failing to do that. And again, none of this is new.
Victory Press of Type used by SFPP (Photo credit: Wikipedia)
This post wasn’t on the original slate for the Political Economics of Publishing series but it seems apposite as the arguments and consequences of the Editorial Board of Lingua resigning en masse to form a new journal published by Ubiquity Press continue to rumble on.
The resignation of the editorial board of Lingua from the (Elsevier owned) journal to form a new journal, that is intended to really be “the same journal” raises interesting issues of ownership and messaging. Perhaps even more deeply it raises questions of what the real assets of a journal are. The mutual incomprehension on both sides really arises from very different views of what a journal is and therefore of what the assets are, who controls them, and who owns them. The views of the publisher and the editorial board are so incommensurate as to be almost comical. The views, and more importantly the actions, of the group that really matters, the community that underlies the journal, remains to be seen. I will argue that it is that community that is the most important asset of the strange composite object that is “the journal” and that it is control of that asset that determines how these kinds of process (for as many have noted this is hardly the first time this has happened) play out.
The publisher view is a fairly simple one and clearly expressed by Tom Reller in a piece on Elsevier Connect. Elsevier no doubt holds paperwork stating that they own the trademark of the journal name and masthead and other subsidiary rights to represent the journal as continuing the work of the journal first founded in 1949. That journal was published by North Holland, an entity purchased by Elsevier in the 90s. The work of North Holland in building up the name was part of the package purchased by Elsevier, and you can see this clearly in Reller’s language in his update to the post where he says Elsevier sees the work of North Holland as the work of Elsevier. The commercial investment and continuity is precisely what Elsevier purchased and this investment is represented in the holding of the trademarks and trading rights. The investment, first of North Holland, and then Elsevier in building up the value of these holdings was for the purpose of gaining future returns. Whether the returns are from subscription payments or APCs no longer matters very much, what matters is realising them and retaining control of the assets.
As a side note the ownership of these journals founded in the first half of the twentieth century is often much less clear than these claims would suggest. Often the work of an original publisher would have been seen as a collaboration, contracts may not exist and registering of trademarks and copyright may have come much later. I know nothing about the specifics of Lingua but it is not uncommon for later instantiations of an editorial board to have signed over trademarks to the publisher in a way that is legally dubious. The reality of course is that legal action to demonstrate this would be expensive, impractical and pretty risky. A theoretical claim of legal fragility is not much use against the practical fact that big publishers can hire expensive lawyers. The publisher view is that they own those core assets and have invested in them to gain future returns. They will therefore act to protect those assets.
The view of the editorial board is almost diametrically opposed. They see themselves as representing a community of governance and creating and providing the intellectual prestige of the journal. For the editorial board that community prestige is the core asset. With the political shifts of Open Access and digital scholarship questions of governance have started to play into those issues of prestige. Communities and journals that want to position themselves as forward looking, or supporting their community, are becoming increasingly concerned with access and costs. This is painted as a question of principle, but the core underlying concern is the way that political damage caused by lack of access, or by high (perceived) prices will erode the asset value of the prestige that the editorial board has built up through their labour.
This comes to a head where the editorial board asks Elsevier to hand over the rights to the journal name. For Elsevier this is a demand to simply hand over an asset, the parcel of intellectual property rights. David Mainwaring’s description of the demands of the board as “a gun to the head” gives a sense of how many people in publishing would view that letter. From that perspective it is clearly unreasonable, even deliberately so, intended to create conflict with no expectation of resolution. This is a group demanding, with menaces, the handover of an asset which the publisher has invested in over the years. The paper holdings of trademarks and trading rights represent the core asset and the opportunities for future returns. A unilateral demand to hand them over is only one step from high way robbery. Look closely at the language Reller uses to see how the link between investment and journal name, and therefore those paper holdings is made.
For the editorial board the situation is entirely different. I would guess many researchers would look at that letter and see nothing unreasonable in it at all. The core asset is the prestige and they see Elsevier as degrading that asset, and therefore the value of their contribution over time. For them, this is the end of a long road in which they’ve tried to ensure that their investment is realised through the development of prestige and stature, for them and for the journal. The message they receive from Elsevier is that it doesn’t value the core asset of the journal and that it doesn’t value their investment. To address this they attempt to gain more control, to assert community governance over issues that they hadn’t previously engaged with. These attempts to engage over new issues – price and access – are often seen as naive, or at best fail to connect with the publisher perspective. The approaches are then rebuffed and the editorial group feel they have only a single card left to play, and the tension therefore rises in the language that they use. What the publisher sees as a gun to the head, the editorial board see as their last opportunity to engage on the terms that they see as appropriate.
Of course, this kind of comprehension gap is common to collective action problems that reach across stakeholder groups, and as in most cases that lack of comprehension leads to recrimination and dissmissal of the other parties perspective as on one hand motivated by self-interest on one hand and on the other by naivety and arrogance. There is some justice in these characterisations but regardless of which side of the political fence you may sit it is useful to understand that these incompatible views are driven by differing narratives of value, by an entirely different view as to what the core assets are. On both sides the view is that the other party is dangerously and wilfully degrading the value of the journal.
Both views; that the value of the journal is the prestige and influence realised out of expert editorial work, and that the value is the brand of the masthead and the future income it represents, are limited. They fail to engage with the root of value creation in the authorship of the content. The real core asset is the community of authors. Of course both groups realise this. The editorial board believes that they can carry the community of authors with them. Elsevier believes that the masthead will keep that community loyal. The success or failure of the move depends on which of them is right. That answer is that probably both are to some extent which means the community gets split, the asset degraded in a real-life example of the double-defection strategy in a Prisoner’s Dillemma game.
Such editorial board resignations are not new. There have been a number in the past, some more successful than others. It is important to note that the editorial board is not the community, or representative of them. It is precisely those cases where the editorial board is most directly representing the community of authors where defections are most successful. On the past evidence Elsevier are probably correct to gamble that the journal will at least survive. The factors in favour of the editorial board are that Linguistics is a relatively small, tight knit community, that they have a credible (and APC free) offer on the table that will look and feel a lot like the service offering that they had. I would guess that Lingua authors are focussed on the journal title and only think of the publisher as a distant second issue, if they are even aware of who the publisher is. In that sense the emergence of new lean publishers like Ubiquity Press and consortial sustainability schemes like Open Library of Humanities are a game changer, offering a high quality experience that otherwise looks and feels like a traditional journal process (again, it is crucial to emphasise that lack of APCs to trouble the humanities scholar) while also satisfying the social, funder and institutional pressure for Open Access.
Obviously my sympathies lie with the editorial board. I think they have probably the best chance to make this work we have yet seen. The key is to bring the author community with them. The size and interconnections of this specific community make this possible.
But perhaps more interesting is to look at it from the Elsevier perspective. The internal assessment will be that there were no options here. They’ve weathered similar defections in the past, usually with success and there would be no value in acceding to the demands of the editorial board. The choice was to hold a (possibly somewhat degraded) asset or to give it away. The internal perception will be that the new journal can’t possibly survive, probably that Ubiquity Press will be naively under funded and can’t possibly offer the level of service that the community will expect. Best case scenario is steady as she goes, with a side order of schadenfreude as the new journal fails; worst case, the loss of value to a single masthead. And on the overall profit and loss sheet a single journal doesn’t really matter as its the aggregate value that sells subscription bundles. Logical analysis points to defection as the best move in the prisoner’s dilemma.
Except I think that’s wrong, for two reasons. One is that this is not a single trial prisoners dillemma, its a repeated trial with changing conditions. Second, the asset analysis plays out differently for Elsevier than it does for the editorial board making the repeated trials more important. The asset for the editorial board is the community of the journal. The asset for Elsevier is the author community of all their journals. Thus for the editorial board they are betting everything on one play – they are all in, hence the strength of the rhetoric being deployed. Elsevier need to consider how their choices may play into future conditions.
Again, the standard analyis would be “protect the assets”. Send a strong message to the wider community (including shareholders), that the company will hold its assets. The problem for me is that this is both timid, and in the longer term potentially toxic. It’s timid, compared to what should surely be a robust internal view of the value that Elsevier offers. That the quality services they provided simply cannot be offered sustainably at a lower price. The confident response would be to call the board’s bluff, put the full costing and offer transparently on the table in front of the community and force them to do a compare and contrast. More than just saying “it can’t be done at the price you demand” put out the real costs and the real services.
The more daring move would be to let the editorial board take the name on a “borrow and return” basis, giving Elsevier first right of refusal if (and in the Elsevier view, when) they find that they’re not getting what they need in their new low cost (and therefore, in the Elsevier view, low service) environment. After all, the editorial board already have money to support APCs according to their letter. It’s risky of course, but again it would signal strong confidence in the value of the services offered. Publishers rarely have to do this, but I find it depressing that they almost always shy away from opportunities to really place their value offering in a true market in front of their author communities. To my mind it shows a lack of robust internal confidence in the value they offer.
But beyond the choice of actions there’s a reason why this standard approach is potentially toxic, and potentially more toxic long term even if, perhaps especially if, Elsevier can continue to run the journal with a new board. If Elsevier are to protext the existing asset as they see it, they need to make the case that the journal can continue to run as normal with a new board. The problem is that this case can only be made if the labour of editors is interchangeable, devaluing the contribution of the existing board and by extension the contribution of all other Elsevier editorial boards. If Elsevier can always replace the board of a journal then why would an individual editor, one who believes that it is their special and specific contribution that is building journal prestige, stay engaged? And if its merely to get the line on their CV and they really don’t care, how can Elsevier rely on the quality of their work? Note it is not that Elsevier don’t see the value of that contributed labour, it is clear that editors are part of the value creation chain that adds to Elsevier income, but that the situation forces them to claim that this labour is interchangeable. Elsevier see the masthead as the asset that attracts that labout. The editorial board see their labour and prestige as the asset that attracts the publisher investment in the masthead.
You can see this challenge in Elsevier statements. David Clark, interviewed as part of a Chronicle piece is quoted as follows:
He sees the staff departures as a routine part of the publishing world. “Journals change and editors change,” Mr. Clark said. “That happens normally.”
The editors of Lingua wanted for Elsevier to transfer ownership of the journal to the collective of editors at no cost. Elsevier cannot agree to this as we have invested considerable amount of time, money and other resources into making it a respected journal in its field. We founded Lingua 66 years ago.
You can see here the attempt to discount the specific value of the current editorial board, but in terms that are intended to come across as conciliatory. Elsevier’s comms team are clearly aware of the risk here. Too weak a stance would look weak (and might play badly with institutional share holders) and too strong a stance sends a message to the community that their contribution is not really valued.
This is the toxic heart of the issue. In the end if Elsevier win, then what they’ve shown is that the contribution of the current editorial board doesn’t matter, that the community only cares about the brand. That’s a fine short term win and may even strengthen their hand in subscription negotiations. But it’s utterly toxic to the core message that publishers want to send to the research communities that they serve, that they are merely the platform. It completely undermines the value creation by editorial boards that Elsevier relies on to sell journals (or APCs) and generate their return on investment.
Playing both sides worked in the world before the web, when researchers were increasingly divorced from any connection with the libraries negotiating access to content. Today, context collapse is confronting both groups. Editorial boards suddenly becoming aware that they had acquiesced in giving up control, and frequently legal ownership of “their” journal, at the same time as issues of pricing and cost are finally coming to their attention. Publishers in general, and Elsevier in particular, can’t win a trick in the public arena because their messaging to researchers, lobbying of government, and actions in negotiation are now visible to all the players. But more than that, all those players are starting to pay attention.
The core issue for Elsevier is that if they win this battle, they will show that it is their conception of the core assets of the journal that is dominant. But if that’s true then it means that editorial boards contribute little or no value. That doesn’t mean that a “brand only” strategy couldn’t be pursued, and we will return to the persistence of prestige and brand value in the face of increasing evidence that they don’t reflect underlying value later in the series. But that’s a medium term strategy. In the longer term, if Elsevier and other publishers continue to seek to focus on and hold the masthead and trademarks as the core asset of the journal that they are forced into a messaging and communications stance that will be ultimately disasterous.
There’s no question that Elsevier understands the value that editorial board contributions bring. But continuing down the ownership path through continued rebellions will end up forcing them to keep signalling to senior members of research communities that their personal contribution has no value, that they can easily be replaced with someone else. In the long term that is not going to play out well.
Reproduction of a Charles Mills painting (Photo credit: Wikipedia)
In the first post in this series I identified a series of challenges in scholarly publishing while stepping through some of the processes that publishers undertake in the management of articles. A particular theme was the challenge of managing a heterogenous stream of articles and their associated heterogeneous formats and problems, in particular at a large scale. An immediate reaction many people have is that there must be technical solutions to many of these problems. In this post I will briefly outline some of the charateristics of possible solutions and why they are difficult to implement. Specifically we will focus on how the pipeline of the scholarly publishing process that has evolved over time makes large scale implementation of new systems difficult.
The shape of solutions
Many of the problems raised in the previous post, as well as many broader technical challenges in scholarly communications can be characterised as issues of either standardisation (too many different formats) or many-to-many relationships (many different source image softwares and a range of different publisher systems, but equally many institutions trying to pay APCs to many publishers). Broadly speaking, the solutions to this class of problem involve adopting standards.
Without focussing too much on technical details, because there are legitimate differences of opinion on how best to implement this, solutions would likely involve re-thinking the form of the documents flowing through the system. In an ideal world authors would be working in a tool that interfaces directly and cleanly with publisher systems. At the point of submission they would be able to see what the final published article would like, not because the process of conversion to its final format would be automated but it would be unnecessary. The document would be stored throughout the whole process in a consistent form from which it could always be rendered to web or PDF or whatever is required on the fly. Metadata would be maintained throughout in a single standard form, ideally one shared across publisher systems.
The details of these solutions don’t really matter for our purposes here. What matters is that they are built on a coherent standard representation of documents, objects and bibliographic metadata that flow from the point of submission (or ideally even before) through to the point of publication and syndication (or ideally long after that).
The challenges of the solutions
Currently the scholarly publishing pipeline is really two pipelines. The first is the pipeline where format conversions of the document are carried out and the second a pipeline where data about the article is collected and managed. There is usually redundancy, and often inconsistency between these two pipelines and they are frequently managed by Heath Robinson-esque processes which have been developed to patch systems from different suppliers together. A lot of the inefficiencies in the publication process are the result of this jury-rigged assembly but at the same time its structure is one of the main things preventing change and innovation.
If the architectural solution to these problems is one of adopting a coherent set of standards throughout the submission and publication process then the technical issue is one of systems re-design to adopt these standards. From the outside this looks like a substantial job, but not an impossible one. From the inside of a publisher it is not merely Sysyphean, but more like pushing an ever growing boulder up a slope which someone is using as a (tilted) bowling alley.
There is a critical truth which few outside the publishing industry have grasped. Most publishers do not control their own submission and publication platforms. Some small publishers successfully build their entire systems (PeerJ and PenSoft) are two good examples. But these systems are built for (relatively) small scale and struggle as they grow beyond a thousand papers a year. Some medium sized publishers can successfully maintain their own web server platforms (PLOS is one example of this) but very few large publishers retain technical control over their whole pipelines.
Most medium to large publishers outsource both their submission systems (to organisations like Aries and ScholarOne) and their web server platforms (to companies like Atypon and HighWire). There were good tactical reasons for this in the past, advantages of scale and expertise, but strategically it is a disaster. It leaves essentially the entire customer facing (whether the author or the reader) part of a publishing business in the hands of third parties. And the scale gained by that centralisation, as well as the lack of flexibility that scale tends to create, makes the kind of re-tooling envisaged above next to impossible.
Indeed the whole business structure is tipped against change. These third party players hold quasi-monopoly positions. Publishers have nowhere else to go. The service providers, with publishers as their core customers, need to cover the cost of development and do so by charging their customers. This is a perfectly reasonable thing to do, but with the choice of providers limited (and a shift from to the other costly and painful), and with no plausible DIY option for most publishers, the reality is that it is in the interests of the providers to hold of implementing new functionality until they can charge the maximum for it. Publishers are essentially held to ransom for relatively small changes, radical re-organisation of the underlying platform is simply impossible.
Means of escape
So what are the means of escaping this bind? Particularly given that its a natural consequence of the market structure and scale? No-one designed the publishing industry to do this. The biggest publishers have the scale to go it alone. Elsevier took this route when they purchased the source code to Editorial Manager, the submission platform that is run by Aries as a service for many other publishers. Alongside their web platforms (and probably the best back end data system in the business) this gives Elsevier end-to-end control over their technical systems. It didn’t stop Elsevier spending a rumoured $25M on a new submission system that has never really surfaced, illustrating just how hard these systems are to build.
But Elsevier has a scale and technical expertise (not to mention cash) that most other publishers can only envy. Running such systems in house is a massive undertaking and doing further large scale development even bigger again. Most publisher can not do this alone.
Where there is a shared need for a scalable platform, Community Open Source projects can provide a solution. Publishing has not traditionally embraced Open Source or shared tools, preferring to re-invent the wheel internally. The Public Knowledge Project‘s Open Journal Systems is the most successful play in this space, running more journals (albeit small ones) than any other software platform. There are technical criticisms to be made of OJS and it is in need of an overhaul, but a big problem is that, while it is a highly successful community, it has never become a true Open Source Community Project. The Open Source code is taken and used in many places, but it is locally modified and there had not been the development of a culture of contributing code back to the core.
The same could be said of many other Open Source projects in the publishing space. Frequently the code is available and re-usable, but there is little or no effort put into creating a viable community of contribution. It is Open Source Code, not an Open Source Project. Publishers are often so focussed on maintaining their edge against competition that the hard work of creating a viable community around a shared resource gets lost or forgotten.
It is also possible that the scale of publishing is insufficient to support true Open Source Community projects. The big successful Open Source infrastructure projects are critical across the web, toolsets that are so widely used that its a no-brainer for big corporations more used to patent and copyright fights to invest in them. It could be that there are simply too few developers and too little resource in publishing to make pooling them viable. My view is that the challenge is more political than resourcing, more in fact a result of the fact that there are maybe one or two CTOs or CEOs in the entire publishing industry with deep experience of the Open Source world, but there are differences from those other web-scale Open Source projects and it is important to bear that in mind.
Barriers to change
When I was at PLOS I got about one complaint a month about “why can’t PLOS just do X” where X was a different image format, a different process for review, a step outside the standard pipeline. The truth of the matter is that it can almost always be done. If a person can be found to hand-hold that specific manuscript through the entire process. You can do it once, and then someone else wants it, and then you are in a downward spiral of monkey patching to try and keep up. It simply doesn’t scale.
A small publisher, one that has completely control over their pipeline and is operating at hundreds or low thousands of articles a year, can do this. That’s why you will continue to see most of the technical innovation within the articles themselves come from small players. The very biggest players can play both ends, they have control over their systems, the technical expertise to make something happen, and the resources to throw money at solving a problem manually to boot. But then those solutions don’t spread, because no-one else can follow them. Elsevier is alone in this category, with Springer-Nature possibly following if they can successfully integrate the best of both companies together.
But the majority of content passes through the hands of medium sized players, and players with no real interest in technical developments. These publishers are blocked. Without a significant structural change in the industry it is unlikely we will see significant change. To my mind that structural change can only happen if a platform is developed that provides scale by supporting across multiple publishers. Again, to my mind, that can only be provided by an Open Source platform. One with a real community program behind it. No medium sized publisher wants to shift to a new proprietary platform which will just lock them in again. But publishers across the board have collectively demonstrated a lack of willingness as well as a lack of understanding of what an Open Source Project really is.
Change might come from without, from a new player providing a fresh look at how to manage the publishing pipeline. It might come from projects within research institutions or a collaboration of scholarly societies. It could even come from within. Publishers can collaborate when they realise it is in their collective interests. But until we see new platforms that provide flexible and standards based mechanisms for managing documents and their associated metadata throughout their life cycle, that operate successfull at a scale of tens to hundreds of thousands of articles a year, and that above all are built and governed by systems that publishers trust we will at most incremental change.
Ernesto Priego has invited me to speak at City University in London on Thursday the 22nd October as part of Open Access Week. I wanted to pull together a bunch of the thinking I’ve been doing recently around Open Knowledge in general and how we can get there from here. This is deliberately a bit on the provocative side so do come along to argue! There is no charge but please register for the talk.
The Limits of “Open”: Why knowledge is not a public good and what to do about it
A strong argument could be made that efforts to adopt and require Open Access and Open Data in the 21st Century research enterprise is really only a return to the 17th Century values that underpinned the development of modern scholarship. But if that’s true why does it seem so hard? Is it that those values have been lost, sacrificed to the need to make a limited case for why scholarship matters? Or is something more fundamentally wrong with our community?
Drawing on strands of work from economics, cultural studies, politics and management I will argue that to achieve the goals of Open Knowledge we need to recognise that they are unattainable. That knowledge is not, and never can be, a true public good. If instead we accept that knowledge is by its nature exclusive, and therefore better seen as a club good, we can ask a more productive question.
How is it, or can it be, in the interests of communities to invest in making their knowledge less exclusive and more public? What do they get in return? By placing (or re-placing) the interests of communities at the centre we can understand, and cut through, the apparent dilemma that “information wants to be free†but that it also “wants to be expensiveâ€. By understanding the limits on open open knowledge we can push them, so that, in the limit, they are as close to open as they can be.
The University Rankings season is upon us with the QS league table released a few weeks back to much hand wringing here in the UK as many science focussed institutions tumbled downwards. The fact that this was due to a changed emphasis in counting humanities and social sciences rather than any change at the universities themselves was at least noted, although how much this was to excuse the drop rather than engage with the issue is unclear.
At around the same time particle physicists and other “big science” communities were up in arms as the Times Higher ranking, being released this week, announced that it would not count articles with huge numbers of authors. Similar to the change in the QS rankings this would tend to disadvantage institutions heavily invested in big science projects, although here the effect would probably be more the signals being sent to communities than a substantial effect on scores or rankings. In the context of these shifts the decision of Japanese government to apparently shut a large proportion of Humanities and Social Sciences departments so as to focus on “areas for which society has strong needs” is…interesting.
The response is interesting because it suggests there is a “right way” to manage the “problem”. The issue of course is rather the other way around. There can be no right way to solve the problem independent of an assessment of what it is you are trying to assess. Is it the contribution of the university to the work? Is it some sense of the influence that accrues to the institution for being associated with the article? Is it the degree to which being involved will assist in gaining additional funding?
This, alongside the shifts up and down the QS rankings, illustrates the fundamental problem of rankings. They assume that what is being ranked is obvious, when it is anything but. No linear ranking can ever capture the multifaceted qualities of thousands of institutions but worse than that the very idea of a ranking is built on the assumption that we know what we’re measuring.
Now you might ask why this matters. Surely these are just indicators, mere inputs into decision making, even just a bit of amusing fun that allows Cambridge to tweak the folks at Imperial this year? But there is a problem. And that problem is that these ranking really show a vacuum at the centre of our planning and decision making processes.
What is clear from the discussion above and the hand wringing over how the rankings shift is that the question of what matters is not being addressed. Rather it is swept under the carpet by assuming there is some conception of “quality” or “excellence” that is universally shared. I’ve often said that for me when I hear the word “quality” it is a red flag that means someone wants to avoid talking about values.
What matters in the production of High Energy Physics papers? What do we care about? Is HEP something that all institutions should do or something that should be focussed on a small number of places? But not just HEP, but genomics, history, sociology…or perhaps chemistry. To ask the question “how do we count physics the same as history” is to make a basic category error. Just as it is to assume that one authorship is the same as another.
If the question is was which articles in a year have the most influence, and which institutions contributed, the answer would be very different to the question of which institutions made the most contribution in aggregate to global research outputs. Rankings ignore these questions and try to muddle through with forced compromises like the ones we’re seeing in the THES case.
All that these rankings show is that the way you choose to value things depends how you would (arbitrarily) rank them. Far more interesting is the question of what the rankings tell us about what we really value, and how hard that is in fact to measure.

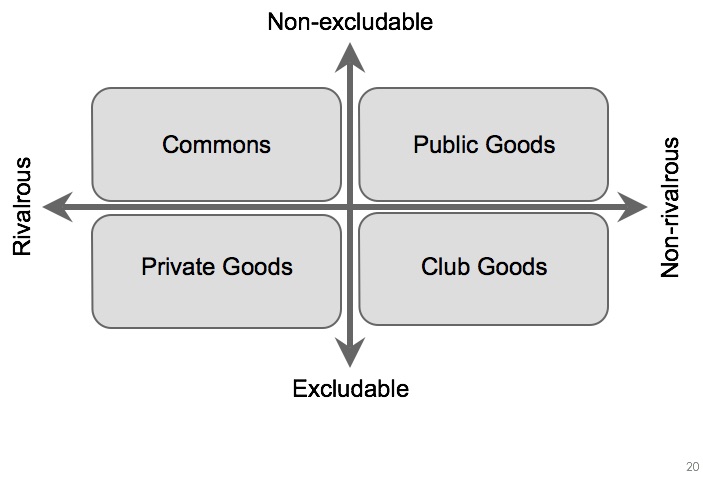 This is a short reflection on a new Working Paper I’m an author on. The paper is largely the work of Jason Potts with contributions from myself, Lucy Montgomery, Ellie Rennie, and John Hartley.Â
This is a short reflection on a new Working Paper I’m an author on. The paper is largely the work of Jason Potts with contributions from myself, Lucy Montgomery, Ellie Rennie, and John Hartley. 


 You probably don’t think too much about where all the services to your residence run. They go missing from view until something goes wrong. But how do we maintain them unless they are identified? An entire utilities industry, which must search for utility infrastructure, hangs in the balance on this knowledge. There’s even
You probably don’t think too much about where all the services to your residence run. They go missing from view until something goes wrong. But how do we maintain them unless they are identified? An entire utilities industry, which must search for utility infrastructure, hangs in the balance on this knowledge. There’s even 


