
Frank Gibson has posted again in our ongoing conversation about using FUGE as a data model for laboratory notebooks. We have also been discussing things by email and I think we are both agreed that we need to see what actually doing this would look like. Frank is looking at putting some of my experiments into a FUGE framework and we will see how that looks. I think that will be the point where we can really make some progress. However here I wanted to pick up on a couple of points he has made in his last post. Continue reading “More on FuGE and data models for lab notebooks”
The science exchange
How do we actually create the service that will deliver on the promise of the internet to enable collaborations to form as and where needed, to increase the speed at which we do science by enabling us to make the right contacts at the right times, and critically; how do we create the critical mass needed to actually make it happen? In another example of blog based morphic resonance there has been a discussion a discussion over at Nature Networks on how to enable collaboration occurred almost at the same time as Pawel Szczeny was blogging on freelance science. I then hooked up with Pawel to solve a problem in my research; as far as we know the first example of a scientific collaboration that started on Friendfeed. And Shirley Wu has now wrapped all of this up in a blog post about how a service to enable collaborations to be identified might actually work which has provoked a further discussion. Continue reading “The science exchange”
Bursty science depends on openness
 Image via Wikipedia
Image via Wikipedia
There have been a number of interesting discussions going on in the blogosphere recently about radically different ways of practising science. Pawel Szczesny has blogged about his plans for freelancing science as a way of moving out of the rigid career structure that drives conventional academic science. Deepak Singh has blogged a number of times about ‘bursty science‘, the idea that projects can be rapidly executed by distributing them amongst a number of people, each with the capacity to undertake a small part of the project. Continue reading “Bursty science depends on openness”
We still have a way to go folks…
The mainstream media has a lot of negative things to say about blogs and user based content on the web. Most of them can be discounted but there is one that I think does need to be taken seriously. The ability of communities to form and to some extent to close around themselves and to simply reinforce their own predjudices is a serious problem and one that we need to work against. This week I had two salutary lessons that reminded me that while the open research community is growing and gaining greater recognition, we remain a pretty marginal fringe group. Continue reading “We still have a way to go folks…”
Another lab notebook framework
 Image via Wikipedia
Image via Wikipedia
Just a very brief note, which really follows on from the vigorous discussion in Jennifer Rohn’s blog at Nature Networks this week, to say that the guys at OpenWetWare appear to have gone live with some of the new functionality for laboratory notebooks on the wiki. Check it out from the OWW main page. I will have a closer look and make some comments as and when I have a bit of time but it looks like a good start.

Provenance, identity, and Google App Engine
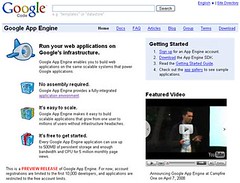 Image by davemc500hats via Flickr
Image by davemc500hats via Flickr
One thing that has been becoming clearer and clearer to me is the need to an agreed central authority for identify. This is one thing, possibly the one thing, that needs to be absolutely secure and inviolable for Open Science to work. Trust relies on provenance. Attribution, which is at the heart of open practice, relies on provenance. And pulling all of my data together from multiple streams in an automatic way relies on a record of their provenance.
There has been a lot of discussion about Google App Engine but two posts in particular have collided for me. First was the first blog post about an app I saw off the rank which uses a Google account to access an open id. Useful and cool. Secondly was the emphasis in another post from David Recordon about Google Apps as a potential Facebook Killer that the access to Google accounts is a key part of the offering.
Then I realised. Google already probably had the highest penetration as a validator of identities but these only really provide access to Google services. OpenID is great in principle but is not perhaps getting the traction it needs to go global. But all of that now just goes away. If you can write an app to authenticate someone via Google and then link that to OpenID you can do it for anything. Google have just positioned themselves to be the de facto provider of identities. And they may have solved the provenance problem into the bargain.
Picture and Wikipedia links via Zemanta.

Semantics in the real world? Part II – Probabilistic reasoning on contingent and dynamic vocabularies
 And other big words I learnt from mathematicians…
And other big words I learnt from mathematicians…
The observant amongst you will have realised that the title of my previous post pushing a boat out into the area of semantics and RDF implied there was more to come. Those of you who followed the reaction [comments in original post, 1, 2, 3] will also be aware that there are much smarter and more knowledgeable people out there thinking about these problems. Nonetheless, in the spirit of thinking aloud I want to explore these ideas a little further because they underpin the way I think about the LaBLog and its organization. As with the last post this comes with the health warning that I don’t really know what I’m talking about. Continue reading “Semantics in the real world? Part II – Probabilistic reasoning on contingent and dynamic vocabularies”
Science in the 21st Century
 Perimeter Institute by hungryhungrypixels (Picture found by Zemanta).
Perimeter Institute by hungryhungrypixels (Picture found by Zemanta).
Sabine Hossenfelder and Michael Nielsen of the Perimeter Institute for Theoretical Physics are organising a conference called ‘Science in the 21st Century‘ which was inspired in part by SciBarCamp. I am honoured, and not a little daunted, to have been asked to speak considering the star studded line up of speakers including, well lots of really interesting people, read the list. The meeting looks to be a really interesting mix of science, tools, and how these interact with people (and scientists). I’m looking forward to it. Continue reading “Science in the 21st Century”
Open drug discovery in the undergraduate lab
Following on from my post there has been lots of discussion both in the comments to the post and also support and ideas on other blogs. I also had a good talk (I know, face to face, how archaic :) with Jeremy Frey about the idea. Here I want to collate a few of the comments and ideas. Continue reading “Open drug discovery in the undergraduate lab”
Friendfeed, lifestreaming, and workstreaming
As I mentioned a couple of weeks or so ago I’ve been playing around with Friendfeed. This is a ‘lifestreaming’ web service which allows you to aggregate ‘all’ of the content you are generating on the web into one place (see here for mine). This is interesting from my perspective because it maps well onto our ideas about generating multiple data streams from a research lab. This raw data then needs to be pulled together and turned into some sort of narrative description of what happened. Continue reading “Friendfeed, lifestreaming, and workstreaming”