
ChemSpidey lives! Even in the face of Karen James’ heavy irony I am still amazed that someone like me with very little programming experience was able to pull together something that actually worked effectively in a live demo. As long as you’re not actively scared of trying to put things together it is becoming relatively straightforward to build tools that do useful things. Building ChemSpidey relied heavily on existing services and other people’s code but pulling that together was a relatively straightforward process. The biggest problems were fixing the strange and in most cases undocumented behaviour of some of the pieces I used. So what is ChemSpidey?
ChemSpidey is a Wave robot that can be found at chemspidey@appspot.com. The code repository is available at Github and you should feel free to re-use it in anyway you see fit, although I wouldn’t really recommend it at the moment, it isn’t exactly the highest quality. One of the first applications I see for Wave is to make it easy to author (semi-)semantic documents which link objects within the document to records on the web. In chemistry it would be helpful to link the names of compounds through to records about those compounds on the relevant databases.
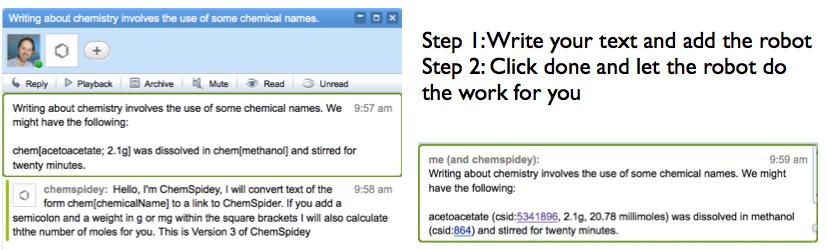
If ChemSpidey is added to a wave it watches for text of the form “chem[ChemicalName{;weight {m}g}]” where the curly bracketed parts are optional. When a blip is submitted by hitting the “done” button ChemSpidey searches through the blip looking for this text and if it finds it, strips out the name and sends it) to the ChemSpider SimpleSearch service. ChemSpider returns a list of database ids and the robot currently just pulls the top one off the list and adds the text ChemicalName (csid:####) to the wave, where the id is linked back to ChemSpider. If there is a weight present it asks the ChemSpider MassSpec API for the nominal molecular weight calculates the number of moles and inserts that. You can see video of it working here (look along the timeline for the ChemSpidey tag).
What have I learned? Well some stuff that is probably obvious to anyone who is a proper developer. Use the current version of the API. Google AppEngine pushes strings around as unicode which broke my tests because I had developed things using standard Python strings. But I think it might be useful to start drawing some more general lessons about how best to design robots for research, so to kick of the discussion here are my thoughts, many of which came out of discussions with Ian Mulvany as we prepared for last weeks demo.
- Always add a Welcome Blip when the Robot is added to a wave. This makes the user confident that something has happened. Lets you notify users if a new version has been released, which might change the way the robot works, and lets you provide some short instructions.It’s good to include a version number here as well.
- Have some help available. Ian’s Janey robot responds to the request (janey help) in a blip with an extended help blip explaining context. Blips are easily deleted later if the user wants to get rid of them and putting these in separate blips keeps them out of the main document.
- Where you modify text leave an annotation. I’ve only just started to play with annotations but it seems immensely useful to at least attempt to leave a trace here of what you’ve done that makes it easy for either your own Robot or others, or just human users to see who did what. I would suggest leaving annotations that identfy the robot, include any text that was parsed, and ideally provide some domain information. We need to discuss how to setup some name spaces for this.
- Try to isolate the “science handling” from the “wave handling”. ChemSpidey mixes up a lot of things into one Python script. Looking back at it now it makes much more sense to isolate the interaction with the wave from the routines that parse text, or do mole calculations. This means both that the different levels of code should become easier for others to re-use and also if Wave doesn’t turn out to be the one system to rule them all that we can re-use the code. I am no architecture expert and it would be good to get some clues from some good ones about how best to separate things out.
These are just some initial thoughts from a very novice Python programmer. My code satisfies essentially none of these suggestions but I will make a concerted attempt to improve on that. What I really want to do is kick the conversation on from where we are at the moment, which is basically playing around, into how we design an architecture that allows rapid development of useful and powerful functionality.
Maybe it’s just me, but I think that having applications in the cloud edit what I wrote is wrong on many levels.
Obviously, trust in the robot provider is the biggest issue here.
Then, bugs in the robot implementation run the risk of completely destructing our data (which is balanced somewhat by Wave’s unlimited undo/playback, IIUC).
Then, this makes auditing content much more difficult, since robot contributions aren’t clearly marked (unless all robots use some common annotations…). Wave proposes the playback feature to discover the trail of changes that led to the current state, but I think that’s a bad idea: I don’t want to watch a possibly very long animation just to see who wrote what (Note: all of this is based on my limited understanding of Wave, which I haven’t tried yet.)
Then, there’s the engineering question of what happens to the robot-generated content when I edit what I wrote. The robot will have to reparse the text, and update its inserted content. But I may have moved, edited, etc, that content by purpose or accidentally. I think that’s just a big stupid mess altogether.
Maybe it’s just me, but I think that having applications in the cloud edit what I wrote is wrong on many levels.
Obviously, trust in the robot provider is the biggest issue here.
Then, bugs in the robot implementation run the risk of completely destructing our data (which is balanced somewhat by Wave’s unlimited undo/playback, IIUC).
Then, this makes auditing content much more difficult, since robot contributions aren’t clearly marked (unless all robots use some common annotations…). Wave proposes the playback feature to discover the trail of changes that led to the current state, but I think that’s a bad idea: I don’t want to watch a possibly very long animation just to see who wrote what (Note: all of this is based on my limited understanding of Wave, which I haven’t tried yet.)
Then, there’s the engineering question of what happens to the robot-generated content when I edit what I wrote. The robot will have to reparse the text, and update its inserted content. But I may have moved, edited, etc, that content by purpose or accidentally. I think that’s just a big stupid mess altogether.
Manuel, any modifications and who or what triggered them are all available in the Wave document. I do agree that good robots should clearly annotate what they have done and what they modified in the process. That’s what I was trying to say above. When it hits mainstream I think there will be a lot of Robots that work at marking up a Wave to show who did what and when. The visualisation will be a challenge but I don’t think it is insurmountable.
Simultaneous edits may be a problem but again its a design issue not something that is impossible. Most of the robots we’ve built so far only act when a blip is submitted, mainly I think because people are a bit scared of exactly what you suggest. Having thought about though I have wondered whether real time character by character interaction might be easier. I haven’t tried it yet though!
Finally I think you probably either like the idea of dynamic documents that can be modified, enhanced, (or broken) by independent agents or not. If you are concerned about control then this is going to worry you. If you are excited by the potential for independent agents to make your life easier then you will be excited. Obviously we want to maximise the positives while minimising the problems (which are serious and real) but really people are only going to buy into this if they want to see the nature of document change. That’s something I want which is why I’m excited. If it isn’t, and the issues worry you more than the potential excites you, then Wave really isn’t for you.
Manuel, any modifications and who or what triggered them are all available in the Wave document. I do agree that good robots should clearly annotate what they have done and what they modified in the process. That’s what I was trying to say above. When it hits mainstream I think there will be a lot of Robots that work at marking up a Wave to show who did what and when. The visualisation will be a challenge but I don’t think it is insurmountable.
Simultaneous edits may be a problem but again its a design issue not something that is impossible. Most of the robots we’ve built so far only act when a blip is submitted, mainly I think because people are a bit scared of exactly what you suggest. Having thought about though I have wondered whether real time character by character interaction might be easier. I haven’t tried it yet though!
Finally I think you probably either like the idea of dynamic documents that can be modified, enhanced, (or broken) by independent agents or not. If you are concerned about control then this is going to worry you. If you are excited by the potential for independent agents to make your life easier then you will be excited. Obviously we want to maximise the positives while minimising the problems (which are serious and real) but really people are only going to buy into this if they want to see the nature of document change. That’s something I want which is why I’m excited. If it isn’t, and the issues worry you more than the potential excites you, then Wave really isn’t for you.
Hi… thanks for your reply.
One thing that has been bouncing around my head has been your quote about “seeing the nature of document[s] change”…
Actually, I don’t see what Wave brings to the table here, that your proposal for a web-native notebook [1] doesn’t address (better, IMO).
AFAICS, Wave provides some kind of hierarchical structure and the ability to edit it simultaneously.
But this is a very small part to the radical change that documents currently undergo — as outlined in [1] — isnt’ it?
[1] http://blog.openwetware.org/scienceintheopen/2009/01/27/the-integrated-lab-record-or-the-web-native-lab-notebook/
Hi… thanks for your reply.
One thing that has been bouncing around my head has been your quote about “seeing the nature of document[s] change”…
Actually, I don’t see what Wave brings to the table here, that your proposal for a web-native notebook [1] doesn’t address (better, IMO).
AFAICS, Wave provides some kind of hierarchical structure and the ability to edit it simultaneously.
But this is a very small part to the radical change that documents currently undergo — as outlined in [1] — isnt’ it?
[1] http://blog.openwetware.org/scienceintheopen/2009/01/27/the-integrated-lab-record-or-the-web-native-lab-notebook/
Cameron, I saw you are organising a Google Wave for Research Hackday. Do you have more information about it somewhere?
Given that only people with wave accounts are likely to be interested in participating, we could use wave to communicate about the hackday. I have created a public wave about science research collaboration via wave that we could use. Just search for “with:public tag:collaboration tag:research”.
Cameron, I saw you are organising a Google Wave for Research Hackday. Do you have more information about it somewhere?
Given that only people with wave accounts are likely to be interested in participating, we could use wave to communicate about the hackday. I have created a public wave about science research collaboration via wave that we could use. Just search for “with:public tag:collaboration tag:research”.
Yep – and hackday is looking like 23 October at least for the first one. There may be more to follow after that.
Yep – and hackday is looking like 23 October at least for the first one. There may be more to follow after that.
Great proof-of-concept, Cameron. Just grabbed ChemSpidey to have a little look-see.
Great proof-of-concept, Cameron. Just grabbed ChemSpidey to have a little look-see.
Hi,
I’ve just been playing with the Chemspidey robot and I have a few queries.
1. Can the robot handle names which contain a space? I’ve tried getting entering chem[acetic acid] and other various names such as bengazole A etc, without any sucess.
2. Is there a limit to the number of chemical names that the robot can process at one time?
3. Does the robot re-parse a wave after an edit? If so is there any way of knowing that the robot has reparsed the wave?
4. How does the robot deal with a situation where more than one ChemSpider record has the same name?
To give you an idea of why I’m asking all this, I’m looking to process a list of about 100 natural product names as a method for keeping track of a deposition and I was just interested in how easy it would be to use ChemSpidey to keep track of records.
Thanks for all your hard work on this robot,
Cheers,
Dave
Hi,
I’ve just been playing with the Chemspidey robot and I have a few queries.
1. Can the robot handle names which contain a space? I’ve tried getting entering chem[acetic acid] and other various names such as bengazole A etc, without any sucess.
2. Is there a limit to the number of chemical names that the robot can process at one time?
3. Does the robot re-parse a wave after an edit? If so is there any way of knowing that the robot has reparsed the wave?
4. How does the robot deal with a situation where more than one ChemSpider record has the same name?
To give you an idea of why I’m asking all this, I’m looking to process a list of about 100 natural product names as a method for keeping track of a deposition and I was just interested in how easy it would be to use ChemSpidey to keep track of records.
Thanks for all your hard work on this robot,
Cheers,
Dave
Hi Dave, in a rush so some very brief answers – drop me a line in Wave if you want to follow up.
1. Probably not, but easy to fix the regex to do this – I need to re-write anyway to improve this and its on the todo list
2. In principle no, in practice it will probably break because there is very limited error catching and if e.g. it doesn’t get a response for one chemical, it may get confused about which one is which.
3. It is supposed to re-parse a given blip every time the “done” button gets pressed for that blip
4. It just takes the first one it gets at the moment.
Doing a complete re-write is on my list of things to do as well as abstracting some of the error catching that should be done. So all your questions are things that may break it but that I should fix!
Hi Dave, in a rush so some very brief answers – drop me a line in Wave if you want to follow up.
1. Probably not, but easy to fix the regex to do this – I need to re-write anyway to improve this and its on the todo list
2. In principle no, in practice it will probably break because there is very limited error catching and if e.g. it doesn’t get a response for one chemical, it may get confused about which one is which.
3. It is supposed to re-parse a given blip every time the “done” button gets pressed for that blip
4. It just takes the first one it gets at the moment.
Doing a complete re-write is on my list of things to do as well as abstracting some of the error catching that should be done. So all your questions are things that may break it but that I should fix!