Written on the train on the way from Barcelona to Grenoble. This life really is a lot less exotic than it sounds…Â
The workshop that I’ve reported on over the past few days was both positive and inspiring. There is a real sense that the ideas of Open Access and Open Data are becoming mainstream. As several speakers commented, within 12-18 months it will be very unusual for any leading institution not to have a policy on Open Access to its published literature. In many ways as far as Open Access to the published literature is concerned the war has been won. There will remains battles to be fought over green and gold routes – the role of licenses and the need to be able to text mine – successful business models remain to be made demonstrably sustainable – and there will be pain as the inevitable restructuring of the publishing industry continues. But be under no illusions that this restructuring has already begun and it will continue in the direction of more openness as long as the poster children of the movement like PLoS and BMC continue to be successful.
Open Data remains further behind, both with respect to policy and awareness. Many people spoke over the two days about Open Access and then added, almost as an addendum ‘Oh and we need to think about data as well’. I believe the policies will start to grow and examples such as the BBSRC Data Sharing Policy give a view of the future. But there is still much advocacy work to be done here. John Wilbanks talked about the need to set achievable goals, lines in the sand which no-one can argue with. And the easiest of these is one that we have discussed many times. All data associated with a published paper, all analysis, and all processing procedures, should be made available. This is very difficult to argue with – nonetheless we know of examples where the raw data of important experiments is being thrown away. But if an experiment cannot be shown to have been done, cannot be replicated and checked, can it really be publishable? Nonetheless this is a very useful marker, and a meme that we can spread and promote.
In the final session there was a more critical analysis of the situation. A number of serious questions were raised but I think they divide into two categories. The first involves the rise of the ‘Digital Natives’ or the ‘Google Generation’. The characteristics of this new generation (a gross simplification in its own right) are often presented as a pure good. Better networked, more sharing, better equipped to think in the digital network. But there are some characteristics that ought to give pause. A casualness about attribution, a sense that if something is available then it is fine to just take it (its not stealing after all, just copying). There is perhaps a need to recover the roots of ‘Mertonian’ science, to as I think James Boyle put it, publicise and embed the attitudes of the last generation of scientists, for whom science was a public good and a discipline bounded by strict rules of behaviour. Some might see this as harking back to an elitist past but if we are constructing a narrative about what we want science to be then we can take the best parts of all of our history and use it to define and refine our vision. There is certainly a place for a return to the compulsory study of science history and philosophy.
The second major category of issues discussed in the last session revolved around the question of what do we actually do now. There is a need to move on many fronts, to gather evidence of success, to investigate how different open practices work – and to ask ourselves the hard questions. Which ones do work, and indeed which ones do not. Much of the meeting revolved around policy with many people in favour of, or at least not against, mandates of one sort or another. Mike Carroll objected to the term mandate – talking instead about contractual conditions. I would go further and say that until these mandates are demonstrated to be working in practice they are aspirations. When they are working in practice they will be norms, embedded in the practice of good science. The carrot may be more powerful than the stick but peer pressure is vastly more powerful than both.
So they key questions to me revolve around how we can convert aspirations into community norms. What is needed in terms of infrastructure, in terms of incentives, and in terms of funding to make this stuff happen? One thing is to focus on the infrastructure and take a very serious and critical look at what is required. It can be argued that much of the storage infrastructure is in place. I have written on my concerns about institutional repositories but the bottom line remains that we probably have a reasonable amount of disk space available. The network infrastructure is pretty good so these are two things we don’t need to worry about. What we do need to worry about, and what wasn’t really discussed very much in the meeting, is the tools that will make it easy and natural to deposit data and papers.
The incentive structure remains broken – this is not a new thing – but if sufficiently high profile people start to say this should change, and act on those beliefs, and they are, then things will start to shift. It will be slow but bit by bit we can imagine getting there. Can we take shortcuts. Well there are some options. I’ve raised in the past the idea of a prize for Open Science (or in fact two, one for an early career researcher and one for an established one). Imagine if we could make this a million dollar prize, or at least enough for someone to take a year off. High profile, significant money, and visible success for someone each year. Even without money this is still something that will help people – give them something to point to as recognition of their contribution. But money would get people’s attention.
I am sceptical about the value of ‘microcredit’ systems where a person’s diverse and perhaps diffuse contributions are aggregated together to come up with some sort of ‘contribution’ value, a number by which job candidates can be compared. Philosophically I think it’s a great idea, but in practice I can see this turning into multiple different calculations, each of which can be gamed. We already have citation counts, H-factors, publication number, integrated impact factor as ways of measuring and comparing one type of output. What will happen when there are ten or 50 different types of output being aggregated? Especially as no-one will agree on how to weight them. What I do believe is that those of us who mentor staff, or who make hiring decisions should encourage people to describe these contributions, to include them in their CVs. If we value them, then they will value them. We don’t need to compare the number of my blog posts to someone else’s – but we can ask which is the most influential – we can compare, if subjectively, the importance of a set of papers to a set of blog posts. But the bottom line is that we should actively value these contributions – let’s start asking the questions ‘Why don’t you write online? Why don’t you make your data available? Where are your protocols described? Where is your software, your workflows?’
Funding is key, and for me one of the main messages to come from the meeting was the need to think in terms of infrastructure, and in particular, to distinguish what is infrastructure and what is science or project driven. In one discussion over coffee I discussed the problem of how to fund development projects where the two are deeply intertwined and how this raises challenges for funders. We need new funding models to make this work. It was suggested in the final panel that as these tools become embedded in projects there will be less need to worry about them in infrastructure funding lines. I disagree. Coming from an infrastructure support organisation I think there is a desperate need for critical strategic oversight of the infrastructure that will support all science – both physical facilities, network and storage infrastructure, tools, and data. This could be done effectively using a federated model and need not be centralised but I think there is a need to support the assumption that the infrastructure is available and this should not be done on a project by project basis. We build central facilities for a reason – maybe the support and development of software tools doesn’t fit this model but I think it is worth considering.
This ‘infrastructure thinking’ goes wider than disk space and networks, wider than tools, and wider than the data itself. The concept of ‘law as infrastructure’ was briefly discussed. There was also a presentation looking at different legal models of a ‘commons’; the public domain, a contractually reconstructed commons, escrow systems etc. In retrospect I think there should have been more of this. We need to look critically at different models, what they are good for, how they work. ‘Open everything’ is a wonderful philosophical position but we need to be critical about where it will work, where it won’t, and where it needs contractual protection, or where such contractual protection is counter productive. I spoke to John Wilbanks about our ideas on taking Open Source Drug Discovery into undergraduate classes and schools and he was critical of the model I was proposing, not from the standpoint of the aims or where we want to be, but because it wouldn’t be effective at drawing in pharmaceutical companies and protecting their investment. His point was, I think, that by closing off the right piece of the picture with contractual arrangements you bring in vastly more resources and give yourself greater ability to ensure positive outcomes. That sometimes to break the system you need to start by working within it by, in this case, making it possible to patent a drug. This may not be philosophically in tune with my thinking but it is pragmatic. There will be moments, especially when we deal with the interface with commerce, where we have to make these types of decisions. There may or may not be ‘right’ answers, and if there are they will change over time but we need to know our options and know them well so as to make informed decisions on specific issues.
But finally, as is my usual wont, I come back to the infrastructure of tools. The software that will actually allow us to record and order this data that we are supposed to be sharing. Again there was relatively little on this in the meeting itself. Several speakers recognised the need to embed the collection of data and metadata within existing workflows but there was very little discussion of good examples of this. As we have discussed before this is much easier for big science than for ‘long tail’ or ‘small science’. I stand by my somewhat provocative contention that for the well described central experiments of big science this is essentially a solved problem – it just requires the will and resources to build the language to describe the data sets, their formats, and their inputs. But the problem is that even for big science, the majority of the workflow is not easily automated. There are humans involved, making decisions moment by moment, and these need to be captured. The debate over institutional repositories and self archiving of papers is instructive here. Most academics don’t deposit because they can’t be bothered. The idea of a negative click repository – where this is a natural part of the workflow can circumvent this. And if well built it can make the conventional process of article submission easier. It is all a question of getting into the natural workflow of the scientist early enough that not only do you capture all the contextual information you want, but that you can offer assistance that makes them want to put that information in.
The same is true for capturing data. We must capture it at source. This is the point where it has the potential to add the greatest value to the scientist’s workflow by making their data and records more available, by making them more consistent, by allowing them to reformat and reanalyse data with ease, and ultimately by making it easy for them to share the full record. We can and we will argue about where best to order and describe the elements of this record. I believe that this point comes slightly later – after the experiment – but wherever it happens it will be made much easier by automatic capture systems that hold as much contextual information as possible. Metadata is context – almost all of it should be possible to catch automatically. Regardless of this we need to develop a diverse ecosystem of tools. It needs to be an open and standards based ecosystem and in my view needs to be built up of small parts, loosely coupled. We can build this – it will be tough, and it will be expensive but I think we know enough now to at least outline how it might work, and this is the agenda that I want to explore at SciFoo.
John Wilbanks had the last word, and it was a call to arms. He said ‘We are the architects of Open’. There are two messages in this. The first is we need to get on and build this thing called Open Science. The moment to grasp and guide the process is now. The second is that if you want to have a part in this process the time to join the debate is now. One thing that was very clear to me was that the attendees of the meeting were largely disconnected from the more technical community that reads this and related blogs. We need to get the communication flowing in both directions – there are things the blogosphere knows, that we are far ahead on, and we need to get the information across. There are things we don’t know much about, like the legal frameworks, the high level policy discussions that are going on. We need to understand that context. It strikes me though that if we can combine the strengths of all of these communities and their differing modes of communication then we will be a powerful force for taking forward the open agenda.

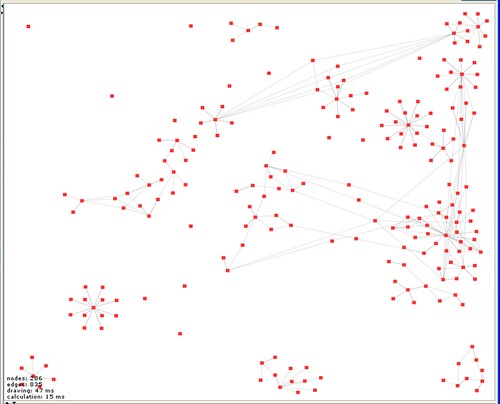 ings that are immediately obvious. The first is that I start a lot of things and don’t necessarily manage to get very far with them and that I do a number of (currently) unrelated things (isolated subgraphs aren’t connected). Also that there are some materials that get widely re-used and some that don’t. There are also clearly things that I haven’t finished entering properly (isolated nodes). Finally, that we need a more sophisticated tool for playing with the view because building a human readable version of the graph will require some manipulation, grabbing subgraphs and moving them around. Welkin is great but after 30 minutes playing I have a bunch of feature requests. But this is what I’ve done so far. I am sure there are many things that can be done with this kind of view – but for the moment what is important is that it is an entirely new kind of way of looking at the record.
ings that are immediately obvious. The first is that I start a lot of things and don’t necessarily manage to get very far with them and that I do a number of (currently) unrelated things (isolated subgraphs aren’t connected). Also that there are some materials that get widely re-used and some that don’t. There are also clearly things that I haven’t finished entering properly (isolated nodes). Finally, that we need a more sophisticated tool for playing with the view because building a human readable version of the graph will require some manipulation, grabbing subgraphs and moving them around. Welkin is great but after 30 minutes playing I have a bunch of feature requests. But this is what I’ve done so far. I am sure there are many things that can be done with this kind of view – but for the moment what is important is that it is an entirely new kind of way of looking at the record.