
Tap…tap…is this thing still on…..SKKRRREEEEEEEEEEEEEE
Epistemic diversity and knowledge production
Consider this yet another commitment to trying to write here a little more regularly. Lots of thinking has been going on but not much writing! At least not writing as I’m going…
Three things colliding over the past few weeks have led me to want to try and get some ideas down. The first was a conversation – one of a set really – with Titus Brown and Dan Katz relating to the application of political economy and collective action theory to communities building research.
The second was the posting of video of a talk I gave a month or so back to our research centre, the Centre for Culture and Technology at Curtin University. In this, I tried to work through the full story of some recent thinking for the first time. I’m trying to articulate what has evolved in my thinking from a view driven by network theory that open is good, more open is better, to an understanding of where and how things have gone wrong.
The final piece was the publication of a new paper (preprint version is also available, actually its what I read so that’s what I’ll link to) by Sabina Leonelli which tackles the value of reproducibility as a concept head on. Leonelli’s work has been a big influence on my developing thinking. Two pieces are particularly relevant. The idea that data is not a thing, but is a category defined by use. That is, we can’t say whether a particular object is data, only that something is data when it is used in particular ways. This is true of many things in research, the objectivist in us wants the qualities of objects like data, methods, and knowledge itself to be eternal platonic concepts inherent in the objects themselves. In practice however these qualities only reveal themselves in certain activities.
These activities depend in turn on ‘repertoires’ another concept I’ve taken from Leonelli’s work, this time from a paper published with Rachel Ankeny. The concept here is that research communities are defined by practices and that these practices are not just learned, but displayed and internalised, in a similar manner to a musician learning repertoire as a set of hurdles to be jumped in their development. I first read this paper at the same time as I was reading Lave and Wenger’s Situated Learning and the parallel between craft learning (see also Ravetz), identity making (see also Hartley and Potts) and community had a significant resonance for me.
In the new piece Leonelli tackles the range of different, and largely incommensurate meanings that are ascribed to the concept of ‘reproducibility’. The paper tackles a range of disciplinarily bound practices ranging from computational sciences, where there is ‘total control’ (yes I could quibble about machine states and compilers but this is philosophy, let’s accept the abstraction) through to ethnography, where there is the expectation that the life experience of the researcher affects the outcome, and that a different researcher would reach different conclusions.
The article focuses on how the necessity for documentation changes as different aspects of accountability rather than reproducibility are taken into account. These concepts of responsibility and accountability for sources of variability that have implications for the claims being made seems more productive and more readily contextualised and generalised. The article finishes with a call to value ‘epistemic diversity’. That is, it is through differing kinds of cross referencing, with different sources of variability, accountability, and reliability that we can most usefully build knowledge.
All of this resonates for me because I’ve been working towards a similar end from a different place. My concern has been thinking about how to operationalise social models of knowledge production. There are a broad class of constructivist models of knowledge where validation occurs when groups come together and contest claims. I have a paper currently in review that casts this as ‘productive conflict’.
In such models the greater the diversity of groups in contact the more ‘general’ the knowledge that is created. However the more diverse those groups are, the less likely it is that such contact will be productive. Indeed it can be harmful – and in most cases involving disadvantaged groups (which is practically everyone in comparison to a professional, permanently employed, western academic) it is at the very least a significant burden and frequently significantly damaging.
In the talk I’m trying to work through the question of how such contacts can be made safe, while equally privileging the value of closing ranks, returning to community to regain strength and re-affirm identity. If diversity is a first order principle in the utilitarian goal of making knowledge, what are the principles of care that allow us to protect the communities that contribute that diversity?
Part of the argument I make is that we need to return to the thinking about network structures. Five years ago I was making the case that ‘bigger is better’ underpinned by an assumption that even if benefits flowed to those who were already well connected the new opportunities of scale would still spread benefits more widely. That seems less and less to be the case today, and the key problems appear to be ones where the benefits of locality are reduced or broken, boundaries are too readily traversed, and groups come into contact in non-productive conflict too frequently.
In the talk I discuss the need to privilege locality. This is the opposite of what most of our systems do today, both in the wider world (‘you need to go viral!’) and in academia (‘international rankings! international journals!’). Many social models draw simple lines with groups inside or outside. Even with a mental view of groups within groups and overlapping groups this tends to miss the messiness that results from non-homogenous interactions across group boundaries. Network structural analysis is harder to do and harder to visualise but it seems to me crucial to get a view of what the optimal dynamics are.
One way to frame the question of network and community dynamics is economically. That is, to ask how the differing groups and communities in contact are sustained and succeed or fail. This in turn is a question of exchange (not necessarily purely financial exchange, but there are limitations to this framing!). Models of club economics and collective action from political economy are useful here and this leads us back to the first conversation I mentioned above.
Titus Brown has been working through a series of posts, relating to the NIH Data Commons project looking at the goods produced in open source projects through the lens of commons and clubs goods. Dan Katz was raising good questions about issues of time and scale that are not well captured by the classical analysis of goods.
I have quibbles with Brown’s analyses and often with others who use this kind of goods-class analysis. However I only just realised that my issue was similar to Leonelli’s point about data. The question of what is ‘the good’ in any particular case is relational, not an absolute. Our discussion of these models tends to turn on an implicit assumption that something (prestige, code, knowledge, expert attention) is the specific good in play, something that in turn surfaces a common assumption in most classical economics that it is appropriate to assume some kind of ‘numeraire good’ that allows exchange of all the others (this is what money is for, and if there’s anything wrong with economic analysis, its money..).
This doesn’t leave me with any firm conclusions beyond some possible routes to analysis. It seems likely that simple analysis based on static descriptions of community and the environment aren’t going to give us answers. We need to understand dynamics of groups opening up and enclosing over time, what sustains them, and what they might find valuable in exchange. We need agent based modelling of the network structures these occur over, and ways of translating from local structure in networks to more ‘bright-lined’ social models of groups. We need to move beyond the simple ‘economic mathematics’ that is often developed from the the club economics of Buchannan and Olson and to develop much more sophisticated and flexible models that allow the nature of exchange and goods to change when viewed from different perspectives.
All in all it emphasises the conclusion I’d reached, that diversity is a first order principle. All forms of diversity and the more diverse the better, provided the coordination between groups is principled. There’s a lot to unpack in that word ‘principled’ but I feel like its the link to the ethical dimension I’ve been missing. I need to dig deeper into notions of ‘care’ (Moore, Priego) and ‘flourishing’ (Holbrook) to tease this out.
Thinking out loud: Tacit knowledge and deficit models
This post was prompted by Donna Lanclos tweeting a link to a talk by Eamon Tewell:
https://twitter.com/DonnaLanclos/status/992843570238377984
His talk, on the problems of deficit models chimed with me on issues of tacit knowledge. I’m still noodling around an underpinning theory of knowledge for my work (blog post currently has spent nearly 12 months in the draft folder). The core to the model is that (general? non-local?) knowledge is made when local knowledge is translated across group boundaries.
This draws heavily on people like Ludwig Fleck and Jerome Ravetz and indeed most social models of knowledge. Ravetz makes two critical observations. First that locally bound contextual knowledge is rooted in what he calls “craft skills” and what Harry Collins would refer to collective tacit knowledge. In our models this is language bound, context dependent, and often tacit. Second that the (attempted) transfer of this knowledge across group boundaries is lossy.
This family of versions of the facts[…]will show diversity in every respect: in their form, in the arguments whereby they can be related to experience, and in their logical relation to other facts. They will however, have certain basic features in common: the assertions and their objects will be simpler than those of their original, and frequently vulgarized out of recognition.
Ravetz (1971) Scientific Knowledge and its Social Problems, p234, emphasis added (1996 Edition, Transaction Publishers)
There is abstraction and generalisation, but also loss of specificity, and loss of detail. Generalisation (reproducibility amongst other things, for instance in Collins’ example of building a specific form of laser) requires that we make the tacit explicit, that we convert collective tacit knowledge, first to relational tacit knowledge and then to explicit statement.
This model works for me because I’m interested in the question of what it is in the culture the academy, or of scholars (not the same thing!) that makes it successful. Where I’m getting to is that we share a culture that provides some common practices and scaffolding which forces us to attempt to make our local knowledge more general (publication for a start) while at the same time pushing us into groups and communities that don’t share language and scaffolding so that we are forced to work at this translation process across groups. My hypothesis is that our long standing culture and practices actually manage this tension successfully and do so at all scales.
So what does this have to do with deficit models? We never talk about the deficit model within the scholarly community. We, by definition don’t have a deficit. Having the thing is how we define the “we”. Within the scholarly community we are (more or less) happy to do the work of translation of trying to explain our context for those who do not understand it because it is part of what we do. Complaints about referee #2 and “those damn scientists” aside we subscribe to a rhetoric of how much we benefit from explaining our thing, that “if you can’t teach it you don’t know it”. Making the tacit explicit – including the tools we apply to force ourselves to do it; teaching, reproducibility, data sharing, peer review – is a core part of our culture when dealing with each other.
But when we talk to outsiders we invoke deficit models. These fail (as various responders to our tweet conversation helpfully provided links to the literature on) precisely because there is not a deficit on their side, of knowledge, there is a deficit on our side of effective translation. Translation is not merely dumbing down here but the work of making concepts relevant, embedding them in local scaffolding, seeking to identify or build boundary objects that can be shared across the border between communities.
If this works then there are a couple of useful things that arise. One is that deficit model rhetoric is a signal that the boundaries of “our” scholarly community have been reached. That’s more useful than you might imagine. Defining where we start and end is not a trivial exercise. Second that working to identify and understand the cultural practices that seek to make the tacit explicit within our communities takes me to the core of my problems of interest. I’ve already speculated a little on the role of teaching here but there is more to this.
What is perhaps most interesting is that we might be able to make something positive out of the failures of deficit model thinking by using failure modes to help us understand the translation deficit. Something that I really haven’t worked out remains the challenge of resource allocation between translation focussed on a known group and that for potential users whose characteristics are as yet unknown. This again, is not a new question but one that I’ve been grappling with for a long time. This might provide a new way in.
Against the 2.5% Commitment
Three things come together to make this post. The first is the paper The 2.5% Commitment by David Lewis, which argues essentially for top slicing a percentage off library budgets to pay for shared infrastructures. There is much that I agree with in the paper, the need for resourcing infrastructure, the need for mechanisms to share that burden, and fundamentally the need to think about scholarly communications expenditures as investments. But I found myself disagreeing with the mechanism. What motivates me to getting around to writing this is the recent publication of my own paper looking at resourcing of collective goods in scholarly communications, which lays out the background to my concerns, and the announcement from the European Commission that it will tender for the provision of a shared infrastructure for communicating research funded through Horizon2020 programs.
The problem of shared infrastructures
The challenge of resourcing and supporting infrastructure is well rehearsed elsewhere. We understand it is a collective action problem and that these are hard to solve. We know that the provision of collective and public-like goods is a problem that is not well addressed by markets, and better addressed by the state (for true public goods for which there are limited provisioning problems) or communities/groups (for collective goods that are partly excludable or rivalrous). One of the key shifts in my position has been the realization that knowledge (or its benefits) are not true public goods. They are better seen as club good or common pool resources for which we have a normative aspiration to make them more public but we can never truly achieve this.
This has important implications, chief amongst them that communities that understand and can work with knowledge products are better placed to support them than either the market, or the state. The role of the state (or the funder in our scholarly communications world) then becomes providing an environment that helps communities build these resources. It is the problem of which communities are best placed to do this that I discuss in my recent paper, focussing on questions of size, homogeneity, and solutions to the collective action problem drawing on the models of Mancur Olson in The Logic of Collective Action. The short version is that large groups will struggle, smaller groups, and in particular groups which are effectively smaller due to the dominance of a few players, will be better at solving these problems. Shorter version, publishers, of which there are really only 5-8 that matter will solve problems much better than universities, of which there are thousands.
Any proposal that starts “we’ll just get all the universities to do X” is basically doomed to failure from the start. Unless coordination mechanisms are built into the proposal. Mechanism one is abstract the problem up till there are a smaller number of players. ORCID is gaining institutional members in those countries where a national consortium has been formed. Particularly in Europe where a small number of countries have worked together to make this happen. The effective number of agents negotiating drops from thousands to around 10-20. The problem is this is politically infeasible in the United States where national coordination, government led is simply not possible. This isn’t incidentally an issue to do with Trump or Republicans but a long-standing reality in the USA. National level coordination, even between the national funding agencies is near impossible. The second mechanism is where a small number of players dominate the space. This works well for publishers (at least the big ones) although the thousands of tiny publishers do exploit the investment that the big ones make in shared infrastructures like Crossref. If the Ivy Plus group in the US did something, then maybe the rest would follow but in practice that seems unlikely. The patchwork of university associations is too disparate in most cases to reach agreement on sharing burden.
The final mechanism is one where there are direct benefits to contributors that arise as a side effect of contributing to the collective resource. More on that later.
A brief history of top-slicing proposals
The idea of top-slicing budgets to pay for scholarly infrastructure is not new. I first heard it explicitly proposed by Raym Crow in a meeting in the Netherlands that was seeking to find ways to fund OA Infrastructures. I have been involved in lobbying funders over many years that they need to do something along these lines. The Open Access Network follows a similar argument. The problem then, was the same as the problem now, what is the percentage? If I recall correctly Raym proposed 1%, others have suggested 1.5%, 2% and now 2.5%. Putting aside the inflation in the figure over the years there is a real problem here for any collective action. How can we justify the “correct” figure?
There are generally two approaches to this. One approach is to put a fence around a set of “core” activities and define the total cost of supporting them as a target figure. This approach has been taken by a group of biomedical funders convened by the Human Frontiers Science Program Organization who are developing a shared approach to funding to ensure “that core data resources for the life sciences should be supported through a coordinated international effort(s) that better ensure long-term sustainability and that appropriately align funding with scientific impact”. Important to note is that the convening involved a relatively small number of the most important funders, in a specific discipline, and it is a community organization, the ELIXR project that is working to define how “core data resources” should be defined. This approach has strengths, it helps define, and therefore build community through agreeing commitments to shared activities. It also has a weakness in that once that community definition is made it can be difficult to expand or generalize. The decisions of what is a “core data resource” in the biosciences is unlikely to map well to other disciplines for instance.
The second approach, attempts to get above the problem of disciplinary communities by defining some percentage of all expenditure to invest, effectively a tax on operations to support shared services. In many ways the purpose of the modern nation state is to connect such top-slicing, through taxation, to a shared identity and therefore an implicit and ongoing consent to the appropriation of those resources to support shared infrastructures that would otherwise not exist. That in turn is the problem in the scholarly communication space. Such shared identities and notions of consent do not exist. The somewhat unproductive argument over whether it is the libraries responsibility to cut subscriptions or academics responsibility to ask them to illustrates this. It is actually a shared responsibility, but one that is not supported by sense of shared identity and purpose, certainly not of shared governance. And notably success stories in cutting subscriptions all feature serious efforts to form and strengthen shared identity and purpose within an institution before taking action.
The problem lies in the politics of community. The first approach defines and delineates a community, precisely based on what it sees as core. While this strengthens support for those goods seen as core it can wall off opportunities to work with other communities, or make it difficult to expand (or indeed contract) without major ructions in the community. Top-slicing a percentage does two things, it presumes a much broader community with a sense of shared identity and a notion of consent to governance (which generally does not exist). This means that arguments over the percentage can be used as a proxy for arguments about what is in and out which will obscure the central issues of building a sense of community by debating the identity of what is in and out. In the absence of a shared identity it means adoptions requires unilateral action by the subgroup with their logistical hands on the budgets (in this case librarians). This is why percentages are favoured and those percentages look small. In essence the political goal is to hide this agenda in the noise. That makes good tactical sense, but leaves the strategic problem of building that shared sense of community that might lead to consent and consensus to grow ever bigger. It also stores up a bigger problem. It makes a shift towards shared infrastructures for larger proportions of the scholarly communications system impossible. The numbers might look big today, but they are a small part of managing an overall transition.
Investment returns to community as a model for internal incentives
Thus far you might take my argument as leading to a necessity for some kind of “coming together” for a broad consensus. But equally if you follow the line of my argument this is not practical. The politics of budgets within libraries are heterogeneous enough. Add into that the agendas and disparate views of academics across disciplines (not to mention ignorance on both sides of what those look like) and this falls into the category of collective action problems that I would describe as “run away from screaming”. That doesn’t mean that progress is not feasible though.
Look again at those cases where subscription cancellations have been successfully negotiated internally. These generally fall into two categories. Small(ish) institutions where a concerted effort has been made to build community internally in response to an internally recognized cash crisis, and consortial deals which are either small enough (see the Netherlands) or where institutions have bound themselves to act together voluntarily (see Germany, and to some extent Finland). In both cases community is being created and identity strengthened. In this element, I agree with Lewis’ paper, the idea of shared commitment is absolutely core. My disagreement is that I believe making that shared commitment an abstract percentage is the wrong approach. Firstly because any number will be arbitrary, but more importantly because it assumes common cause with academics that is not really there, rather than focusing on the easier task of building a community of action within libraries. This community can gradually draw in researchers, providing that it is attractive and sustainable, but to try and bridge this to start with is too big a gap to my mind.
This leads us to the third of Olson’s options for solving collective action problems. This option involves the generation of a byproduct, something which is an exclusive benefit to contributors, as part of the production of the collective good. I don’t think a flat percentage tax does this, but other financial models might. In particular reconfiguring the thinking of libraries around expenditure towards community investment might provide a route. What happens when we ask about return on investment to the scholarly community as a whole and to the funding library for not some percentage of the budget but the whole budget?
When we talk about about scholarly communications economics we usually focus on expenditure. How much money is going out of library or funder budgets? A question we don’t ask is how much of that money re-circulates within the community economy and how much leaves the system? To a first approximation all the money paid to privately held and shareholder owned commercial entities leaves the system. But this is not entirely true, the big commercials do invest in shared systems, infrastructure and standards. We don’t actually know how much, but there is at least some. You might think that non-profits are obliged to recirculate all the money but this is not true either, the American Chemical Society spends millions on salaries and lobbying. And so does PLOS (on salaries, not lobbying, ‘publishing operations’ is largely staff costs). For some of these organizations we have much better information on how much money is reinvested and how because of reporting requirements but it’s still limited.
You might think that two start-ups are both contributing similar value, whether they are (both) for profit or not-for-profit. But look closer, which ones are putting resources into the public domain as open access content, open source code, open data? How do those choices relate to quality of service? Here things get interesting. There’s a balance to found in investing in high quality services, which may be building on closed resources to secure a return to (someone else’s) capital, vs building the capital within the community. It’s perfectly legitimate for some proportion of our total budgets to leave the system, both as a route to securing investment from outside capital, but also because some elements of the system, particular user-facing service interfaces, have traditionally been better provided by markets. It also provides a playing field on which internal players might compete to make this change.
This is a community benefit but it also a direct benefit. Echoing the proposal of the Open Access Network, this investment would likely include instruments for investment in services (like Open Library of Humanities) and innovation (projects like Coko might be a good fit). Even if access to this capital is not exclusively accessible to projects affiliated with contributing libraries (which would be a legitimate approach, but probably a bit limiting) access to the governance of how that capital is allocated provides direct advantages to investing libraries. Access to the decisions that fund systems that their specific library needs is an exclusive benefit. Carefully configured this could also provide a route to draw in academics who want to innovate, as well as those who see the funding basis of their traditional systems crumbling. In the long term this couples direct benefits to the funding libraries to community building within the academic library community, to a long game of drawing in academics (and funders!) to an ecosystem in which their participation implies the consent of the governed, ultimately justifying a regime of appropriate taxation.
Actually in the end my proposal is not very different to Lewis’s. Libraries make a commitment to engage in and publicly report on their investment in services and infrastructure, in particular they report on how that portfolio provides investment returns to the community. There is competition for the prestige of doing better, and early contributors get to claim that prestige of being progressive and innovative. As the common investment pool grows there are more direct financial interests that bring more players in, until in the long term it may become an effectively compulsory part of the way academic libraries function. The big difference for me is not setting a fixed figure. Maybe setting targets would help, but in the first instance I suspect that simply reporting on community return on investment would change practice. One of the things Buchannan and Olson don’t address (or at least not to any great extent) is that identity and prestige are club goods. It is entirely economically rational for a library to invest in something that provides no concrete or immediate material return, if in doing so it gains profile and prestige, bolstering its identity as “progressive” or “innovative” in a way that plays well to internal institutional politics, and therefore in turn to donors and funders. Again, here I agree with Lewis and the 2.5% paper that signalling (including costly signalling from an evolutionary perspective) is a powerful motivator. Where I disagree is with the specifics of the signal, who it signals to, and how that can build community from a small start.
The inequity of traditional tenders
How does all of this relate to the European Commission statement that they will tender for an Open Science Platform? The key here is the terms of the tender. There is an assumption amongst many people I follow that F1000Research have this basically sewn up. Certainly based on numbers I’m aware of they are likely the best placed to offer a cost effective service that is also high quality. The fact that Wellcome, Gates and the African Academy of Sciences have all bought into this offering is not an accident. The information note states that the “Commission is implementing this action through a public procurement procedure, which a cost-benefit analysis has shown to be the most effective and transparent tool”. What the information note does not say is that the production of community owned resources and platforms will be part of the criteria. Framing this as an exercise in procuring a service could give very different results to framing it as investment in community resources.
Such tender processes put community organisations at a disadvantage. Commercial organisations have access to capital that community groups often do not. Community groups are more restricted in risk taking. But they are also more motivated, often it is part of their mission, to produce community resources, open source platforms and systems, open data, as well as the open content which is the focus of the Commission’s thinking. We should not exclude commercial and non-community players from competing for these tenders, far from it. They may well be more efficient, or provide better services. But this should be tensioned against the resources created and made available as as result of the investment. Particularly for the Commission, with its goal of systemic change, that question should be central. The resources that are offered to the community as part of a tender should have a value placed on them, and that should be considered in the context of pricing. The Commission needs to consider the quality of the investment it is making, as well as the price that it pays.
The key point of agreement, assessing investment quality
This leads to my key point of agreement with Lewis. The paper proposes a list of projects, approved for inclusion in the public reporting on investment. I would go further and develop an index of investment quality. The resources to support building this index would be the first project on the list. And members, having paid into that resource, get early and privileged access to the reporting, just as in investment markets. For any given project or service provider an assessment would be made on two main characteristics. How much of the money invested is re-circulated in the community? And an assessment of the quality of governance and management that the investment delivers, including the risk on the investment (high for early-stage projects, low for stable infrastructures)? Projects would get a rating, alongside an estimated percentage of investment that recirculates. Projects were all outputs get delivered with open licensing would get a high percentage (but not 100%, some will go in salaries and admin costs).
Commercial players are not excluded. They can contribute information on the resources that they circulate back to the community (perhaps money going to societies, but also contribution to shared infrastructures, work on standards, dataset contributions) that can be incorporated. And they may well claim that although the percentage is lower than some projects the services are better. Institutions can tension that, effectively setting a price on service quality, which will enhance competition. This requires more public reporting than commercial players are naturally inclined to provide, but equally it can be used as a signal of commitment to the community. One thing that might choose to do is contribute directly to the pool of capital, building shared resources that float all the boats. Funders could do the same, some already do by funding these projects, and that in turn could be reported.
The key to this, is that it can start small. A single library, funding an effort to examine the return it achieves on its own investment will see some modest benefits. A group working together will tell a story about how they are changing the landscape. This is already why efforts like Open Library of Humanites and Knowledge Unlatched and others work at all. Collective benefits would rise as the capital pool grew, even if investment was not directly coordinated, but simply a side effect of libraries funding various of these projects. Members gain exclusive benefits, access to information, identity as a leading group of libraries and institutions, and the prestige that comes with that in arguing internally for budgets and externally for other funding.
2.5% is both too ambitious and not ambitious enough
In the end I agree with the majority of the proposals in the 2.5% Commitment paper, I just disagree with the headline. I think the goal is over-amibitious. It requires too many universities to sign up, it takes political risks both internally and externally that are exactly the ones that have challenged open access implementation. It assumes power over budgets and implicit consent from academics that likely doesn’t exist, and will be near impossible to gain, and then hides it by choosing a small percentage. In turn that small percentage requires coordination across many institutions to achieve results, and as I argue in the paper, that seems unlikely to happen.
At the same time it is far from ambitious enough. If the goal is to shift investment in scholarly communications away from service contracts and content access to shared platforms, then locking in 2.5% as a target may doom us to failure. We don’t know what that figure should be, but I’d argue that it is clear that if we want to save money overall, it will be at least an order of magnitude high in percentage terms. What we need is a systemic optimisation that lets us reap the benefits of commercial provision, including external capital, quality of service, and competition, while progressively retaining more of the standards, platforms and interchange mechanisms in the community sphere. Shifting our thinking from purchasing to investment is one way to work towards that.
2560 x 1440 (except while traveling)
It’s not my joke but it still works. And given my pretty much complete failure to achieve even written resolutions it’s probably better to joke up front. But…here are a set of things I really need to write this year. Maybe more for my benefit than anyone else but it’s good to have a record.
Blog Posts: I have a few things that either need finishing or need writing, these are relatively immediate
- Against the 2.5% Commitment – argument that fixed top-slicing of scholarly communications budgets is not the right way to think about funding infrastructure and support services. Rather we need some market-like social incentives that are internal to organisations. My proposal is a shift to thinking about budgets as investments, including the extent to which they recirculate value or money to the scholarly community.
- The local context of peer review – I owe Hilda Bastian a more detailed response as to why, while I agree with her analysis of where the problems lie and what the optimal state is, that the studies we have of peer review don’t show what we might think. Part of the reason for trying this is that I need to make this argument in the broader context for a book (below)
- Some hard truths on APCs, exclusion and charity – There is a received wisdom circulating that APCs are the source of all problems with exclusion. I think, while APCs have their problems that this is looking in the wrong place, in fact that APCs may surface issues of exclusion in a way that could be ultimately positive. The real risk of exclusion lies in work-flows and no-one seems to be focussed on the interaction of structural power in publishers and submission systems and the risks they pose.
- Sketching a theory of knowledge – first step in working out the article (4 below) to get some ideas out and down
Articles: Things that really need writing, mostly have been sitting for a while
- Institutions for productive conflict in knowledge-making – working on this at the moment. It’s not really feasible to describe the argument in a few sentences, which means I haven’t got it fully refined yet! It’s a much evolved version of parts of the argument from this paper from ElPub last year.
- The structure of scientific evolutions – we have a theory of everything (in knowledge communications and production). It’s quite exciting, and quite simple in outline, complex in its implications. A draft of this exists but it may be a small book rather than an article. I desperately need to do the background reading to properly support the arguments.
- A clash of peer review cultures – a kind of auto-ethnography of the experience of the peer review process for the Excellence paper. There were many weird moments when an attitude amongst the researchers involved (including editors and referees) in favour of open review clashed with the journal’s assumptions of double-blind review. Mainly blocked because I don’t know diddly squat about doing ethnography properly and need to talk to someone who does…
- Repertoires, learning and social theories of knowledge – I’ve been using and developing an implicit social theory of knowledge that is really just a mix of notions of community from a wide range of different places. It needs to be properly fleshed out, ideally with someone who knows what they’re talking about. This is likely more review/synthesis than new ideas per se, but as far as I can tell that synthesis doesn’t exist across the silos I’ve been looking at.
Books
- The core piece of work I need to do on the book I should be focused on. It is code-named Telling Stories with the subtitle A personal journey from the sciences to the humanities (and back). The first (very rough!) drafts of the introduction and first chapter I posted as Telling a Story and Portrait of the Scientist as a Young Man.
- Possibly pull together a series of texts into a thing on Networked Knowledge. I put together a “book” based on old posts and reflections a few years back. That doesn’t in and of itself merit formal publication (that’s the view of the referees incidentally) but, particularly with the resurgence of interest in “federate all the things”, there are a series of texts that could be pulled together in a kind of manifesto of the technological possibilities.
- Political Economics of Scholarly Publishing – I’ve been occasionally adding to this list of posts, and this new paper is relevant, but that work needs drawing together in some form. Might be worth seeking a grant to cover the time to finish it off properly perhaps…
That looks like a long list…
Leaving the Gold Standard
This is a piece I wrote for Jisc, as part of a project looking at underpinning theories of citation. There are a few more to come, and you can read the main report for the project at the Jisc repository. This post cross-posted from the Open Metrics blog.
Citations, we are told, are the gold standard in assessing the outputs of research. When any new measure or proxy is proposed the first question asked (although it is rarely answered with any rigour) is how this new measure correlates with the “gold standard of citationsâ€. This is actually quite peculiar, not just because it raises the question of why citations came to gain such prominence, but also because the term “gold standard†is not without its own ambiguities.
The original meaning of “gold standard†referred to economic systems where the value of currency was pegged to that of the metal; either directly through the circulation of gold coins, or indirectly where a government would guarantee notes could be converted to gold at a fixed rate. Such systems failed repeatedly during the late 19th and early 20th centuries. Because they coupled money supply – the total available amount of government credit – to a fixed quantity of bullion in a bank, they were incapable of dealing with large-scale and rapid changes. The Gold Standard was largely dropped in the wake of World War II and totally abandoned by the 1970s.
But in common parlance “gold standard†means something quite different to this fixed point of reference, it refers to the best available. In medical sciences the term is used to refer to treatments or tests that currently are regarded as the best available. The term itself has been criticised over the years, but it is perhaps more ironic that this notion of “best available†is actually in direct contradiction to intent of the currency gold standard – that value is fixed to a single reference point for all time.
So are citations the best available measure, or the one that we should use as the basis for all comparisons? Or neither? For some time they were the only available quantitative measure of the performance of research outputs. The only other quantitative research indicator being naive measures of output productivity. Although records have long been made of journal circulation in libraries – and one time UK Science Minister David Willetts has often told the story of choosing to read the “most thumbed†issue of journals as a student – these forms of usage data were not collated and published in the same ways as the Science Citation Index. Other measure such as research income, reach, or even efforts to quantify influence or prestige in the community have only been available for analysis relatively recently.
If the primacy of citations is largely a question of history, is there nonetheless a case to be made that citations are in some sense the best basis for evaluation? Is there something special about them? The short answer is no. A large body of theoretical and empirical work has looked at how citation-based measures correlate with other, more subjective, measures of performance. In many cases at the aggregate level those correlations or associations are quite good. As a proxy at the level of populations citation based indicators can be useful. But while much effort has been expended on seeking theories that connect individual practice to citation-based metrics there is no basis for the claim that citations are in any way better (or to be fair, any worse) than a range of other measures we might choose.
Actually there are good reasons for thinking that no such theory can exist. Paul Wouters, developing ideas also worked on by Henry Small and Blaise Cronin, has carefully investigated the meaning that gets transmitted as authors add references, publishers format them into bibliographies, and indexes collect them to make databases of citations. He makes two important points. First that we should separate the idea of the in text reference and bibliographic list – the things that authors create – from the citation database entry – the line in a database created by an index provider. His second point is that, once we understand the distinction between these objects we see clearly how the meaning behind the act of the authors is systematically – and necessarily – stripped out by the process. While we theorists may argue about the extent to which authors are seeking to assign credit in the act of referencing, all of that meaning has to be stripped out if we want citation database entries to be objects that we can count. As an aside the question of whether we should count them, let alone how, does not have an obvious answer.
It can seem like the research enterprise is changing at a bewildering rate. And the attraction of a gold standard, of whatever type, is stability. A constant point of reference, even one that may be a historical accident, has a definite appeal. But that stability is limited and it comes at a price. The Gold Standard helped keep economies stable when the world was a simple and predictable place. But such standards fail catastrophically in two specific cases.
The first failure is when the underlying basis of trade changes, when the places work is done expands or shifts, when new countries come into markets, or when the kinds of value being created changes. Under these circumstances the basis of exchange changes and a gold standard can’t keep up. Similar to the globalisation of markets and value chains, the global expansion of research and the changing nature of its application and outputs with the advent of the web puts any fixed standard of value under pressure.
A second form of crisis is a gold rush. Under normal circumstances a gold standard is supposed to constrain inflation. But when new reserves are discovered and mined hyperinflation can follow. The continued exponential expansion of scholarly publishing has lead to year on year inflation of citation database derived indicators. Actual work and value becomes devalued if we continue to cling to the idea of a citation as a constant gold standard against which to compare ourselves.
The idea of a gold standard is ambiguous to start with. In practice citation data-based indicators are just one measure amongst many, neither the best available – whatever that might mean – nor an incontrovertible standard against which to compare every other possible measure. What emerges more than anything else from the work of the past few years on responsible metrics and indicators is the need to evaluate research work in its context.
There is no, and never has been, a “gold standardâ€. And even if there were, the economics suggests that it would be well past time to abandon it.
Packaging Data: The core problem in general data sharing?
In this final post about the IDRC data sharing pilot project I want to close the story that started with an epic rant a few months ago. To recap, I had data from the project that I wanted to deposit in Zenodo. Ideally I would have found an example of doing this well, organised my data files in a similar way, zipped up a set of directories with a structured manifest or catalogue in a recognised format and job done. It turned out to not be so easy.
In particular there were two key gaps. The first was my inability to find specific guidance on how to organise the kinds of data that I had. These were, amongst other things, interview recordings and transcripts. You’d think that it would be common enough, but I could not find any guidance on standard metadata schema or the best way to organise the data. That is not the say that it isn’t out there. There is likely some very good guidance, and certainly expertise, but I struggled to find it. It was not very discoverable, and as I said at the time, if I can’t find it then its highly unlikely that the ‘average’ non-computational researcher generating small scale data sets will be able to. In the end the best advice I got on organizing the package was ‘organise it in the way that makes most sense for the kinds of re-use you’d expect’, so I did.
The second problem was how to create a manifest or catalogue of the data in a recognised format. First there was still the question of format, but more importantly there is a real lack of tools to generate well formed and validated metadata. You’d think there would be a web-based system to help you generate some basic dublin core or other standard metadata but the only things I could find were windows only and/or commercial. Both of which are currently non-starters for me. This really illustrates a big gap in RDM thinking. Big projects manage data which gets indexed, collected, and catalogued into specialist systems. Single data objects get reasonable support with generic data repositories with a form based system that lets you fill in key metadata. But for any real project, you’re going to end up with a package of data with complex internal relationships. You need a packager.
At this point, after I’d posted my rant, Petie Sefton from the University of Technology Sydney got in touch. Petie has worked for many years on practical systems that help the average scholar manage their stuff. His work mixes the best of pragmatic approaches and high standards of consistency. And he’d been working on a tool that did exactly what I needed. Called Calcyte, it is an approach to data packaging that is designed to work for the average researcher and produce an output that meets high standards. Petie has also written about how we used the tool and presented this at eResearch Australasia.
What does Calcyte do?
Calcyte is ‘is experimental early- stage open source software’ that generates ‘static-repository[s] for human-scale data collections’. We worked with Petie running the software and me filling in the info, although I could potentially have run it myself. What this looked like from a user perspective was very simple. First Petie and I shared a folder (we used Google Drive, sue me) where we could work together. After the first run of the tool each of the subdirectories in my folder had a CATALOG file, which was an Excel file (yeah, sue us again…).
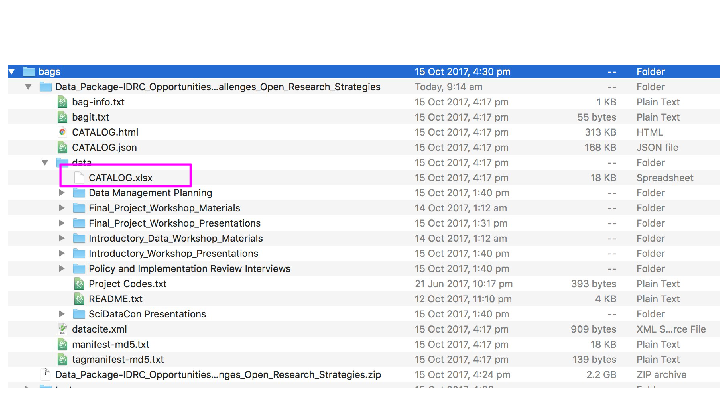
Opening up the Excel file showed a partially filled in spreadsheet with information about the files in that directory. Which I then filled out.

Running the tool again generated a top level CATALOG.html file, which is a human-readable guide to all the files in the package. The information and relationships is all hoovered up from the entries in the various spreadsheets.

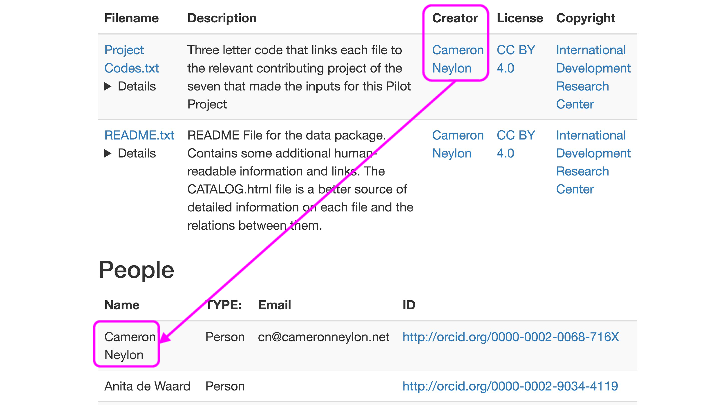
…but more than that. The human-readable file has relationships both about the files, like for instance copyright assignments, people and external identifiers where available. Here for instance, we’ve done something which is generally close to impossible, noting that I’m the creator of a file, with links to my ORCID, but also that the Copyright belongs to someone else (in this case the IDRC) while also providing file-level licensing information.
But it’s not just information about the files but also between files, like for instance that one is a translation of another…
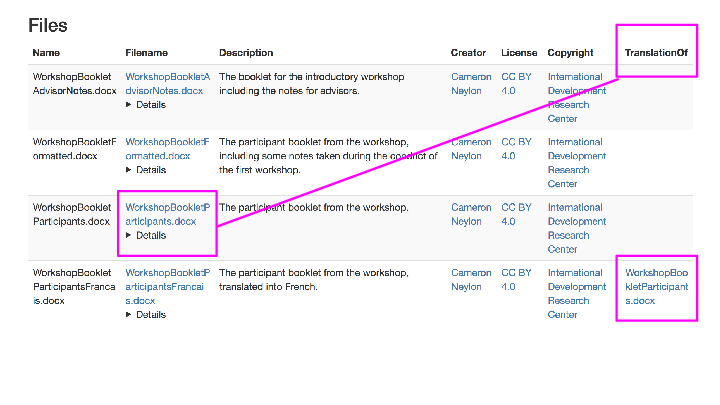
All of this is also provided in machine-readable form as JSON-LD and it is all basically schema.org metadata. We rinsed and repeated several times to refine what we were doing, how to represent things, until we were happy. Things that were not obvious included what the canonical ID for the project was (we settled on the DOI for the formally published grant proposal), how to represent the role of interviewee as opposed to interviewer, and a whole series of other niggly things, that mostly related to questions of granularity, or particular choices of how to represent relationships (versions of objects that were not updates or mere format shifts).
Finally all of this was packaged up and sent of to Zenodo. It is a shame that Zenodo can’t (at the moment) surface the CATALOG.html in the root directly as a preview. If it did and this ‘DataCrate’ approach caught on then it is easy to imagine the generation of a set of tools that could help. I can imagine (in fact I’ve already started doing this) writing out simple CSV files in computational projects that record provenance that could then be processed to support the production of the CATALOG files. Working in a shared folder with Excel files actually worked extremely well, the only real issue being Excel isn’t great for text data entry, and its habit of screwing up character encodings. It is easy to imagine an alternative web-based or browser-based approach to that walks you through a cycle of data entry until you’re happy. Adding on a little conventional configuration to guide a user towards standard ways of organising file sets could also be helpful. And actually doing this as you went with a project could help not just to organise your data for sharing, but also provide much better metadata records as you were going.
The happy medium
When I was getting fed up, my complaint was really that online support seemed to be either highly technical (and often inconsistent) advice on specific schema or so general as to be useless. What was missing was what PT calls ‘human-scale’ systems for when you’ve got too many objects to be uploading them all one by one, but you have too few, or your objects are too specialist for there to be systems to support you to do that. For all that we talk about building systems and requiring data sharing, this remains a gap which is very poorly supported, and as a result we are getting less data sharing than would be ideal, and what data sharing there is is less useful than it could be. The challenge of the long tail of research data production remains a big one.
In the report we note how crucial it is that there be support where researchers need it, if the goal of changing culture is to be achieved. Researchers struggle both with good data management within projects and with packaging data up in a sensible fashion when subject to data sharing mandates at formal publication. Because we struggle, the data that is shared is not so useful, so the benefits to the researcher are less likely. Add this to a certain level of antagonism caused by the requirement for DMP provision at grant submission, and a virtually complete lack of follow-up on the part of funders, and the end result is not ideal. Of course, doing the practical work of filling these gaps with good (enough) tools is neither sexy nor easily fundable. Implementation is boring, as is maintenance, but its what’s required if we want to move towards a culture of data sharing and re-use. The kind of work that Petie and his group do needs more support.
Images in this post are (c) Peter (Petie) Sefton, taken from http://ptsefton.com/2017/10/19/datacrate.htm
Walking the walk – How easily can a whole project be shared and connected?
One of the things I wanted to do with the IDRC Data Sharing Pilot Project that we’ve just published was to try and demonstrate some best practice. This became more important as the project progressed and our focus on culture change developed. As I came to understand more deeply how much this process was one of showing by doing, for all parties, it became clear how crucial it was to make a best effort.
This turns out to be pretty hard. There are lots of tools out there to help with pieces of the puzzle, but actually sharing a project end-to-end is pretty rare. This means that the tools that help with one part don’t tend to interconnect well with others, at multiple levels. What I ended up with was tangled mess of dependencies that were challenging to work through. In this post I want to focus on the question of how easy it is to connect up the multiple of objects in a project via citations.
The set of objects
The full set of objects to be published from the project were:
- The grant proposal – this acts as a representation of the project as a whole and we published it quite early on in RIO
- The literature and policy review – this was carried out relatively early on but took a while to publish. I wanted it to reference the materials from expert interviews that I was intended to deposit but this got complicated (see below)
- The Data Management Plan for the project – again published in RIO relatively early on in the process
- Seven Data Management Plans – one from each of the participating projects in the pilot
- Seven Case Studies – one on each of the participating projects. This in turn needed to be connected back to the data collected, and ideally would reference the relevant DMP.
- The final report – in turn this should reference the DMPs and the case studies
- The data – as a data sharing project we wanted to share data. This consisted of a mix of digital objects and I struggled to figure out how to package it up for deposit, leading in the end to this epic rant. The solution to that problem will be the subject for the next post.
Alongside this, we wanted as far as possible to connect things up via ORCID and to have good metadata flowing through Crossref and Datacite systems. In essence we wanted to push as far as is possible in populating a network of connections to build up the map of research objects.
The problem
In doing this, there’s a fairly obvious problem. If we use DOIs (whether from Crossref or DataCite) as identifiers, and we want the references between objects to be formal citations, that are captured by Crossref as relationships between objects, then we can only reference in one direction. More specifically, you can’t reference an object until its DOI is registered. Zenodo lets you “reserve” a DOI in advance, but until it is registered formally (with DataCite in this case) none of the validation or lookup systems work. This citation graph is a directed graph, so ordering matters. On top of this, you can’t update it after formal publication (or at least not easily)
The effect of this is that if you want to get the reference network right, and if “right” is highly interconnected as was the case here then publication has to proceed in a very specific order.
In this case the order was:
- The grant proposal – all other objects needed to refer to “the project”
- The data set – assuming there was only one. It may have been better to split it but its hard to say. The choice to have one package meant that it had to be positioned here.
- The review – because it needed to reference the data package
- The contributing project Data Management Plans – these could have gone either second or third but ended up being the blocker
- The Case Studies – because they need to reference review, data package, project and Data Management Plans
- The final report – has to go last because it refers to everything else
In practice, the blocker became the Data Management Plans. Many of the contributing projects are not academic, formal publishing doesn’t provide any particular incentive for them and they had other things to worry about. But for me, if I was to formally reference them, they had to be published before I could release the Case Studies or final report. In the end four DMPs were published and three were referenced by the documents in the Data Package. Some of the contributors had ORCIDs that got connected up via the published DMPs but not all.

The challenges and possible solutions
The issue here was that the only way in practice to make this work was to get everything lined up, and then release carefully over a series of days once each of the objects were released by the relevant publisher (Zenodo and Pensoft Publishing for RIO). This meant a delay of months as I tried to get all the pieces fully lined up. For most projects this is impractical. The best way to get more sharing is to share early, once each object is ready. If we have to wait until everything is perfect it will never happen, researchers will lose interest, and much material will either not be shared, or not get properly linked up.
One solution to this is to reserve and pre-register DOIs. Crossref is working towards “holding pages” that allow a publisher to register a DOI before the document is formally released. However this is intended to operate on acceptance. This might be ok for a journal like RIO where peer review operates after publication and acceptance is based on technical criteria, but it wouldn’t have worked if I had sought to publish in a more traditional journal. Registering Crossref DOIs that will definitely get used in the near future may be ok, registering ones that may never resolve to a final formally published document would be problematic.
The alternative solution is to somehow bundle all the objects up into a “holding package” which, once it is complete triggers the process of formal publication and identifier registration. One form of this might be a system, a little like that imagined for machine-actionable DMPs where the records get made and connections stored until, when things are ready the various objects get fired off to their formal homes in the right order. There are a series of problems here as well though. This mirrors the preprint debate. If its not a “real” version of the final thing does that not create potential confusion? The system could still get blocked by a single object being slow in acceptance. This might be better than a researcher being blocked, the system can keep trying without getting bored, but it will likely require researcher intervention.
A different version might involve “informal release” by the eventual publisher(s), with the updates being handled internally. Again recent Crossref work can support this through the ability of DOIs for different versions of objects to point forward to the final one. But this illustrates the final problem, it requires all the publishers to adopt these systems.
Much of what I did with this project was only possible because of the systems at RIO. More commonly there are multiple publishers involved, all with subtly different rules and workflows. Operating across Zenodo and RIO was complex enough, with one link to be made. Working across multiple publishers with partial and probably different implementations of the most recent Crossref systems would be a nightmare. RIO was accommodating throughout when I made odd requests to fix things manually. A big publisher would likely have not bothered. The fiddly process of trying to get everything right was hard enough, and I knew what my goals were. Someone with less experience, trying to do this across multiple systems would have given up much much earlier.
Conclusions and ways forward (and backwards)
A lot of what I struggled with I struggled because I wanted to leverage the “traditional” and formal systems of referencing. I could have made much more progress with annotation or alternative modes of linking, but I wanted to push the formal systems. These formal systems are changing in ways that make what I was trying to do easier. But it’s slow going. Many people have been talking about “packages” for research projects or articles, the idea of being able to easily grab all the materials, code, data, documents, relevant to a project with ease. For that need much more effective ways of building up the reference graph in both directions.
The data package, which is the piece of the project where I had the most control over internal structure and outwards references, does not actually point at the final report. It can’t because we didn’t have the DOI for that when we put the data package together. The real problem here is the directed nature of the graph. The solution lies in some mechanism that either lets up update reference lists after publication or that lets us capture references that point in both directions. The full reference graph can only be captured in practice if we look for links running both from citing to referenced object and from referenced object to citing object, because sometimes we have to publish them in the “wrong” order.
How we manage that I don’t know. Update versioned links that simply use web standards will be one suggestion. But that doesn’t provide the social affordances and systems of our deeply embedded formal referencing systems. The challenge is finding flexibility as well as formality and making it easier to wire up the connections to build the full map.
Policy for Culture Change: Making data sharing the default
Open Access week is a fitting time to be finalising a project on Open Data. About two years ago I started working with the Canadian development funder, the International Development Research Center, to look at the implementation of Open Data policy. This week the final report for that project is being published.
Everyone, it seems agrees that opening up research data is a good thing, at least in the abstract. While there are lots of good reasons for not making data open in specific cases, its hard to make a case against the idea that, in general, it would be good for more of the outputs of research to be more available. The traditional way to achieve this, at least for funded research projects is through funder policies requiring data management and data sharing.
But while there’s a steadily increasing number of funders requiring data management plans and data sharing there is less work asking whether they work. There’s a lot less work asking what might be an even harder question, what does it actually mean for them to work? For the past two years I’ve been working with the IDRC, a Canadian funder of development research to probe that question. In particular I’ve been looking at how policy, and support of policy can support the kind of cultural change that leads to good data management and data sharing being the default for researchers.
The reason the project focused this way was due to a striking early finding. My first task was to interview a set of international experts on research data management and sharing for their views on what worked and what did not. What emerged was a sharp divide between those who thought that Data Management Plans were the best way to get researchers thinking about RDM, and those who were worried that the requirement for DMPs was leading to a tick box “compliance cultureâ€. There was a concern that this might actually be damaging the process of culture change. I wrote about this concern in the review written for the project, published in RIO Journal (where all the formal documentary outputs for the project can be found).
The main part of the project was focussed on seven case studies of IDRC-funded projects. We worked with the projects to examine the data that they were generating, and then to develop a Data Management Plan. Then we followed the challenges and issues that arose as the projects implemented those plans. IDRC funds development research done in developing countries. We had projects based in Vietnam, Niger, South Africa, Columbia Egypt and Brazil working on projects in areas from copyright to climate change, health issues to sexual harassment, ecology to economics.
When we looked at the projects we found any of the challenges you might expect for data sharing in places away traditional centers of research prestige. Lack of good network connectivity, limited capacity and resources. We saw serious issues arising out of the English-centric nature of not just research communication, but systems and infrastructures. And we saw that the funding of infrastructures was inconsistent, periodic and unstable.
But what we also saw were challenges that arose at the funder level. These were not restricted to IDRC, and not limited to development funding or even data sharing, but general issues of policy design and implementation for research funders. Funders work with many projects, and those projects have different contexts and issues. Often the relationship between funder and project is mediated through a single person, the Program Officer. This single person then has to be the conduit for all policy communication, implementation, and monitoring.
Its hardly news that the hard working people within funders have a lot on their plate. What I certainly hadn’t seen before was how this limited progress towards culture change amongst researchers. Within our pilot project we had a group of highly engaged program officers that were learning about data management as they went. New policies required them to become instant experts able to advise, and where necessary push, funded projects towards new practice. There are a lot of policy initiatives within funders at the moment, and the load means that not all of them get the attention they need.
This turns out to be a problem because of the message it can send. Culture change really involves change within both researchers, and the funder. Each on their own can change practice, but embedding that practice so it becomes a culture, of “that’s just how things are done†requires mutual reinforcement. It is not enough to say something is important, you have to show you care about it. Many policies say nice things, but without the backup, and the infrastructure to support it, the message that can come across is “we talk about this, but we don’t really careâ€.
I had a very engaged and sympathetic group of program officers and projects, but even for this group, data wasn’t always the highest priority. We had to plan to regularly reinforce, and provide support for, the message that data was important over the course of the pilot project. Across a whole funder the risk of balls being dropped is very high. This raises issues for policy design and implementation. In the final report, just published at RIO the following recommendations are made.
- Policies serve at least two distinct functions. They serve as a) signals that a specific issue, in this case improvements in data management and sharing, are an issue that the policy maker takes seriously and b) as a means of creating interventions in the behaviour of those subject to the policy. These two aspects of policy intent can be in tension with each other. Policies in general have been designed with the intent of requiring and driving behaviour change. The aspect of signalling, and its role in supporting culture change has been taken less seriously. In the initial review it was noted that the aspirational signalling aspects of some policies were at odds with the content of their interventions.
- The signalling function of a policy is important for culture change. Researchers and funder staff take note of the direction of travel. Articulation of aspirations, particularly when they align with existing sympathies and narratives is important. The details of policy design seem less important and can be antagonistic to cultural change where the aspirations are not matched by capacities provided by the policy maker.
- Internal audiences are at least as important as external. Policy needs to be designed with a view as to how it can effect the desired cultural change within a funder as much as among researcher communities. How does the policy articulate the importance of its aspirational goals, does it give permission for individuals to act, how does it help create a strong culture that aligns with the policy goals? Perhaps most importantly does it provide the necessary internal levers to ensure that those charged with implementing policy can access the necessary resources, infrastructure and expertise?
- The primary failure mode for policy is overreach. The most common issue with policy implementation is where demands are made that cannot be met or evaluated. Generally the concern is whether researchers have the capacities, resources or expertise to deliver on policy requirements. However the risks can be substantially higher where the shortfall is at the funder. The core of culture change is a sense that the aspirations underpinning the change are both important and shared amongst stakeholders. Where a grantee falls short, allowances can be made in a way that reinforces the importance of the direction of travel to the grantee. However when a funder fails to provide the support and infrastructures – including Program Officer time, skills and expertise – necessary for policy implementation, and most particularly when implementation is not evaluated, the message is sent that the issue is not in fact important. This in turn leads to instrumental behaviour and in turn a lack of, or even negative, cultural change.
- The interventions required by policy must be properly resourced, continuous, and self-reinforcing. The second aspect of policy remains important. Interventions at the level of requirements and practice have a role to play, both as opportunities to engage – and therefore transmit culture – and as a means of driving best practice and therefore achieving successes for grantees from their behaviour change. For this goal to be achieved the interventions need to be embedded in an ongoing and reinforced narrative that engages both researchers and funder staff.
This being Open Access week it seems worth thinking about how we design policy, not just within funders but more generally so as to effect culture change, not just change behavior. What might we do to better design both policies and implementation to build a greater sense of a collective direction of travel, and how do we ensure that travel is monitored in a way that is sustainable and builds momentum rather than becoming a tick-box exercise?
Pushing costs upstream and risks downstream: Making a journal publisher profitable
I’m not quite sure exactly what was the reason but there was a recent flare-up of the good old “how much does it cost to publish a scholarly article” discussion recently. Partly driven by the Guardian article from last month on the history of 20th century scholarly publishing. But really this conversation just rumbles along with a regular flare up when someone does a new calculation that comes to a new number, or some assertion is made about “value” by some stakeholder.
Probably the most sensible thing said in the most recent flare up in my view was this from Euan Adie:
There isn't a "true cost" of publishing an article independent of context. More things with no true costs: bananas, newspapers, tweets
— Euan Adie (@Stew) July 7, 2017
There is a real problem with assigning a “true” cost. There are many reasons for this. One is the obvious, but usually most contentious, question of what to include. The second issue is the question of whether a single cost “per-article” even makes sense. I think it doesn’t because the costs of managing articles vary wildly even within a single journal so the mean is not a very useful guide. On top of this is the question of whether the marginal costs per article are actually the major component of rising costs. One upon a time that was probably true. I think its becoming less true with new platforms and systems. The costs of production, type-setting and format shifting for the web, should continue to fall with automation. The costs of running a platform tend to scale more with availability requirements and user-base than with the scale of content. And if you’re smart as a publisher you can (and should be) reducing the costs of managing peer review per article by building an internal infrastructure that automates as much as possible and manages the data resources as a whole. This shifts costs to the platform and away from each article, meaning that the benefits of scale are more fully realised. Dig beyond the surface outrage at Elsevier’s patent on waterfall peer review processes and you’ll see this kind of thinking at work.
Put those two things together and you reach an important realization. Driving per-article costs to platform costs makes good business sense, and that as you do this the long tail of articles that are expensive to handle will dominate the per-article costs. This leads to a further important insight. It will be an increasingly important part of a profitable journal’s strategy will be to prevent submission of high cost articles. Add back in the additional point that there is no agreement on a set of core services that publishers provide and you see another important part of the strategy. A good way to minimise both per-article and platform costs is to minimise the services provided, and seek to ensure those services handle the “right kind of articles” as efficiently as possible.
Pushing costs upstream
Author Selectivity
Nature, the journal has one of the best business models on the planet and, although figures are not publicly available, is wildly profitable. The real secret to its success is two-fold. Firstly, that a highly trained set of professional editors are efficient at spotting things that “don’t fit”. There is plenty of criticism as to whether they’re good at spotting articles that are “interesting” or “important” but there is no question that they are effective at selecting a subset of articles that are worth the publishing company investing in. The second contributor is author selectivity. Author’s do the work for the journal by selecting only their “best” stuff to send. Some people of course, think that all their work is better than everyone elses’s but they in turn are usually that arrogant because they have the kind of name that gets them past the triage process anyway. The Matthew effect works for citations as well.
It may seem counter intuitive but the early success of PLOS ONE was built on a similar kind of selectivity. PLOS ONE launched with a splash that meant many people were aware of it, but the idea of “refereeing for soundness” was untested, and perhaps more importantly not widely understood. And of course it was not indexed and had no Journal Impact Factor. The subset of authors submitting were therefore those who a) had funds to pay an APC b) could afford to take a punt on a new, unproven journal and c) had a paper that they were confident was “sound”. Systematically this group, choosing articles there were sure were “sound” would select good articles. When ONE was indexed it debuted with a quite high JIF (yes, I’m using a JIF, but for the purpose it is intended for, describing a journal) which immediately began to slide as the selectivity of submission decreased. By definition, the selectivity of the peer review process didn’t (or at least shouldn’t) change.
Anecdotally my own submissions follow exactly this path. I’ve never had a research paper sent to be refereed at Nature, every one was rejected without review. Each one of those articles went on to get a lot of citations – several are considered important in their field (although no-one ever really got the thermal equivalence thing, shame really). Similarly the first article my group sent to PLOS ONE (after rejection at several other journals) hasn’t done too badly either (as an aside, you can get to the articles via Scholar, I don’t want to artificially inflate altmetrics by linking directly). As an aside there’s an irony here. One of the ways to maximise the “quality” of articles a journal gets is to avoid being indexed, but have a profile amongs traditional academics in North America and Europe, and publish fast. That way you will systematically get submissions people think are good, but have been rejected by other journals. These are systematically likely to include important articles unrecognised by more conventional journals.
If you follow this logic through then having systems to rapidly reject papers that are likely to be problematic makes sense. Some journals have internal (but obviously secret) systems that reject everything from specific countries (one large publisher had an automatic rejection for everything from Iran at one point) or that fit specific patterns (GWAS studies that link single, or small numbers, of gene up or down regulation to a specific stimulus). Many editorial processes apply various forms of conscious or unconscious bias to “positive” effect here, rejecting articles from unknown institutions.
Technical measures
It isn’t just editorial processes that push costs upstream. It’s also possible to get authors to do extra work by technical means. The most obvious of these is journal submission systems. Once upon a time all the metadata for an article would have been extracted by the publisher or an indexer from the manuscript itself. Submissions involved some number of hard copies and a cover letter being posted. Today the many hours of filling in forms that are typical of submission systems places that work onto the authors’ shoulders.
Similarly the many, many efforts to get authors to use publisher-supported authoring tools seek the same goal. If successful, which they are generally not, they would push work out of the publisher workflow upstream to authors. One of the problems that has arisen with this is that authoring technologies keep moving faster than publishing ones. In some cases there are journals that successfully use the outputs of LaTex directly but these are the exceptions.
The best example remains that of the IUCr journals that essentially provide web based forms to upload standard data formats and small chunks of text into predefined sections. By obtaining structured data from the authors in a standardised format the publishing costs are reduced massively. This is a near ideal case where many reports that are structurally very similar can be supported by a platform. Doing this for articles in general is clearly much harder and there are no good examples of this that I’m aware of for articles in other fields (some fields have side-stepped this for particular data types but that’s different in subtle but important ways).
Obviously there are limits here. It’s not feasible to simply impose new technical requirements and expect all authors to simply acquiesce. And as noted previously in this quasi-series there are challenges relating to the control that submission system vendors hold over publisher workflows. Nonetheless this is an area where publisher costs can be substantially reduced at least in theory.
Pushing costs (and risks) downstream
If one solution to reducing costs is pushing the upstream, then another is clearly pushing them downstream. This can mean a range of things – costs to authors, funders, institutions, or “the system”. As these are often not obviously direct cash costs they can be diffuse. These are the costs of the publisher (or really of any actor in the publishing workflow) not doing something.
An extreme example of these is so-called “predatory” publishers that do not do peer review. To simplify the example we can put aside the question of whether publishers “add value” through peer review and treat this simply as a question of validation and certification. In a world where we assume that being published in “a journal” means an article has been peer reviewed, what (and where) are the costs of that not happening?
Eve and Priego (2017) have dissected the question of who is harmed in a recent article. In particular they note that the harm, largely in the form of risk, falls largely on those relying on “publication” in “a journal” as a quality indicator or a certification of peer review. There is an accumulating risk of being exploited by unscrupulous authors for systems and institutions that rely on such markers. The cost may materialise either as wastage when a poor decision is made (to hire someone or to fund a project) or more directly as the cost of replicating the validation process that was supposed to occur. Whatever you may have thought of Beall’s list, and I really didn’t think much of it, it was a product of donated labour. When it folded, many of the evaluation systems that had come to depend on it discovered those costs and had to find a way to cover them. What is worth noting is that, the more institutions rely on such markers (including eponymous lists) as reliable proxies, the greater the risk and the greater the cost when problems arise.
This is a toy example, albeit one that really did play out in practice. The risks also run the other way as Eve and Priego note, the loss of perfectly good work that is published in an otherwise unreliable venue. Similar kinds of cost and loss do play out across the publishing system where venue is relied upon as a proxy; at the extreme end the costs (financial and in terms of mortality and morbidity) of cases such as the Wakefield paper, assumed to be reliable because it was published in the lancet, and on the other of highly promising young researchers neglected (and the investment in their careers wasted) because they happen not to have the required paper in the right journals, or book with the right publisher.
There are many examples where publishers have to make a choice to internalise costs or push the risk downstream. Checking for image manipulation is a good example. This remains costly, and in most cases prohibitively so, to apply to every submitted image so spot checking is common, or restricting checks to accepted articles. But that passes the cost downstream, either to the next journal in the submission chain, or to the community of readers. Readers may even be unable to check images because of format shifting and resolution changes in the production process to reduce publisher costs. Unfortunately most of these decisions are done quietly without any publicity. It remains almost impossible to determine across journals exactly what checks are carried out, with what frequency, and at which stage.
What does this mean?
First and foremost, don’t take anyone who says “the cost of an article is [or should be] X” seriously unless they are very, very, clear on exactly what parts of the process of publishing they are talking about and the context in which those parts are taking place. Second, we need to get much more explicit about what services are being provided. There have been a range of efforts to try and improve on this, but they’ve not really taken off, at least in part because they’re not really in the interests of the big publishers, who benefit the most from playing the games I’ve described here. As I’ve argued elsewhere we need a much better understanding of how shifting the costs from the publisher balance sheet, to the academic worker, or institutional infrastructure, play out. How do cash costs of managing a strong quality assurance process within a publisher scale when they become the non-cash costs of an academic editor, or referee’s time? When they become the time wasted by researchers on following up on fatally flawed research?
All of the above relates to costs, and none of the above relates to price. We also need a better understanding of the political economics of pricing. Particularly we need to understand where we are creating a luxury goods market where price (either in work to get through the selection process or in money) drives the perception of brand, which reinforces the perceived value of the investment, and therefore leads to an increase in price. Be very wary of claims that publishing is a “value driven market”. This is both a way of avoiding a discussion of internal costs, which in some cases are outrageous, and of avoiding the discussion about precisely which services are being provided. It’s also a captive market. Another value-based market is plane flights out of Florida this week…
Above all, we need a much more sophisticated understanding and far better models of how costs are being distributed across the system in cash and non-cash costs, in labour and in capital. Overall we can point at the direction of travel, and the problems with existing pricing and cost structures. But its hard to make usable predictions or good design decisions without a lot more data. Getting that data out of the system as it exists at the moment will be hard, but the direction of travel is positive. There’s nothing wrong with publishers making a surplus, but any conversation about what kind of surplus is “appropriate” needs to based on a much deeper understanding of all the costs in the system.