
Many efforts at building data infrastructures for the “average researcher” have been funded, designed and in some cases even built. Most of them have limited success. Part of the problem has always been building systems that solve problems that the “average researcher” doesn’t know that they have. Issues of curation and metadata are so far beyond the day to day issues that an experimental researcher is focussed on as to be incomprehensible. We clearly need better tools, but they need to be built to deal with the problems that researchers face. This post is my current thinking on a proposal to create a solution that directly faces the researcher, but offers the opportunity to address the broader needs of the community. What is more it is designed to allow that average researcher to gradually realise the potential of better practice and to create interfaces that will allow technical systems to build out better systems.
Solve the immediate problem – better backups
The average experimental lab consists of lab benches where “wet work” is done and instruments that are run off computers. Sometimes the instruments are in different rooms, sometimes they are shared. Sometimes they are connected to networks and backed up, often they are not. There is a general pattern of work – samples are created through some form of physical manipulation and then placed into instruments which generate digital data. That data is generally stored on a local hard disk. This is by no means comprehensive but it captures a large proportion of a lot of the work.
The problem a data manager or curator sees here is one of cataloguing the data created, creating a schema that represents where it came from and what it is. We build ontologies and data models and repositories to support them to solve the problem of how all these digital objects relate to each other.
The problem a researcher sees is that the data isn’t backed up. More than that, its hard to back up because institutional systems and charges make it hard to use the central provision (“it doesn’t fit our unique workflows/datatypes”) and block what appears to be the easiest solution (“why won’t central IT just let me buy a bunch of hard drives and keep them in my office?”). An additional problem is data transfer – the researcher wants the data in the right place, a problem generally solved with a USB drive. Networks are often flakey, or not under the control of the researcher so they use what is to hand to transfer data from instrument to their working computer.
The challenge therefore is to build systems under group/researcher control that the needs for backup and easy file transfer. At the same time they should at least start to solve the metadata capture problem and satisfy the requirements of institutional IT providers.
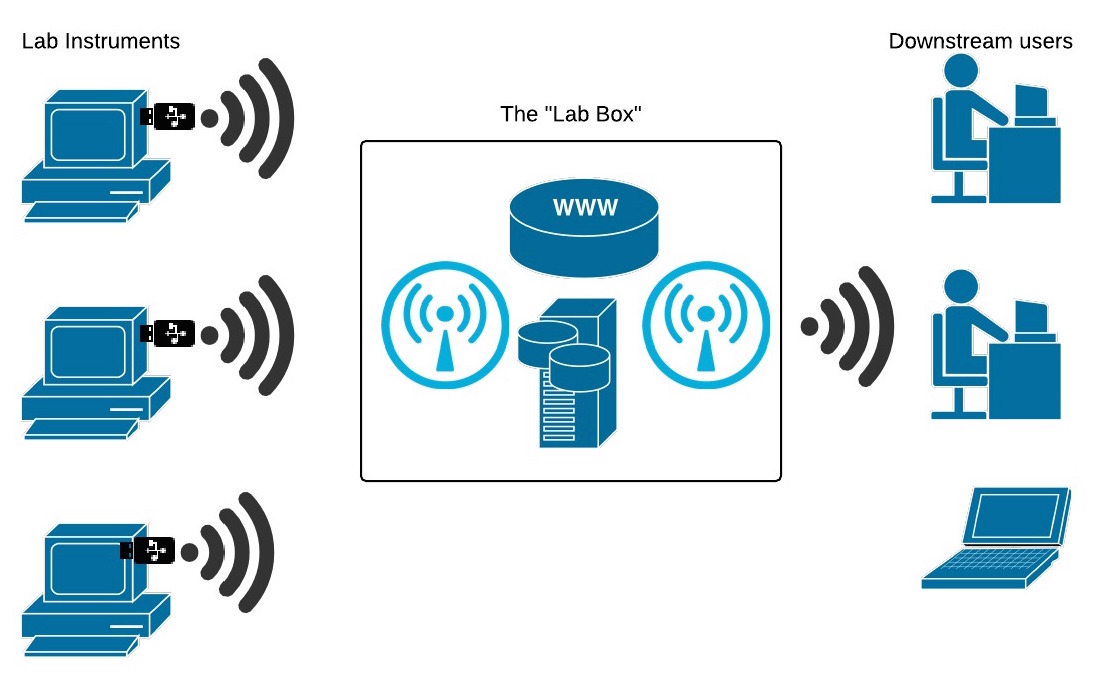
The Lab Box
The PI wants to know that data is being collected, backed up and is findable. They generally want this to be local. Just as researchers still like PDFs because they can keep them locally, researchers are happiest if data is on a drive they can physically locate and control. The PI does not trust their research group to manage these backups – but central provision doesn’t serve their needs. The ideal is a local system under their control that automates data backups from the relevant control computers.
The obvious solution is a substantial hard drive with some form of simple server that “magically” sucks data up from the relevant computers. In the best case scenario appropriate drives on the instrument computers are accessible on a local network. In practice life is rarely this simple and individually creating appropriate folder permissions to allow backups is enough of a problem that it rarely gets done. One alternate solution is to use the USB drive approach – add an appropriate USB fob to the instrument computer that grabs relevant data and transmits it to the server, probably over a dedicated WiFi network. There are a bunch of security issues on how best to design this but one option is a combined drive/Wifi fob where data can be stored and then transmitted to the server.
Once on the server the data can be accessed and if necessary access controls applied. The server system need not be complex but it probably does at least need to be on the local network. This would require some support from institutional IT. Alternately a separate WiFi network could be run, isolating the system entirely from both the web and the local network.
Collecting Metadata
The beauty of capturing data files at the source is that a lot of metadata can be captured automatically. The core metadata of relevance is “What”, “Who”, and “When”. What kind of data has been collected, who was the researcher who collected it and when was it collected. For the primary researcher use cases (finding data after the student has left, recovering lost data, finding your own data six months later) this metadata is sufficient. The What is easily dealt with as is the When. We can collect the original source location of the data (and that tells us what instrument it came from) and the original file creation date. While these are not up to standards of data curators who might want a structured description of what the data is it is enough for the user, it provides enough context for a user to apply their local knowledge of how source and filetype relate to data type.
“Who” is a little harder, but it can be solved with some local knowledge. Every instrument control computer I have ever seen has a folder, usually on the desktop helpfully called “data”. Inside that folder are a set of folders with lab members names on them. This convention is universal enough that with a little nudging it can be relied on to deliver reasonable metadata. If the system allows user registration and automatically creates the relevant folders then saving files to the right folder, and thus providing that critical metadata will be quite reliable.
The desired behaviour can be encouraged even further if files dropped into the correct folder are automatically replicated to a “home computer” thus removing the need for transfer via  USB stick. Again a “convention over configuration” approach can be taken in which the directory structure found on the instrument computers is simply inverted. A data folder is created in which a folder is provided for each instrument. As an additional bonus other folders could be added which would then be treated as if they were an instrument and therefore replicated back to the main server.

How good is this?
If such a system can be made reliable (and that’s not easy - finding a secure way to ensure data gets transferred to the server and managing the dropbox style functionality suggested above is not trivial) then it can solve for a remarkable number of the use cases faced by the small scale laboratory on a regular basis. It doesn’t work for massive files or for instruments that write to a database. That said in research labs, researchers are often “saving as” some form of CSV, text or Excel file type even when the instrument does have a database. It isn’t trivial to integrate into existing shared data systems for instance for departmental instruments. Although adaptors could be easily built they would likely need to be bespoke developments working with local systems. Again though frequently what happens in practice is the users make a local copy of the data in their own directory system.
The major limitations are that there is no real information on what the files really are, just an unstructured record of the instrument that they came from. This is actually sufficient for most local use cases (the users know what the instruments are and the file types that they generate) but isn’t sufficient to support downstream re-use or processing. However, as we’ve argued in some previous papers, this can be seen as a feature not a bug. Many systems attempt to enforce a structured view of what a piece of data is early in creation process. This works in some contexts but often fails in the small lab setting. The lack of structure, while preserving enough contextual information to be locally useful, can be seen as a strength – any data type can be collected and stored without it needing to be available in some sort of schema. That doesn’t mean we can’t offer some of that structure, if and when there is functionality that gives an immediate benefit back to the user, but where there isn’t an immediate benefit we don’t need to force the user to do anything extra.
Offering a route towards more
At this point the seasoned data management people are almost certainly seething if not shouting at their computers. This system does not actually solve many of the core issues we have in data management. That said, it does solve the problem that the community of adopters actually recognises. But it also has the potential to guide them to better practice. One of the points that was made in the LabTrove paper that described work from the Frey group that I was involved in was how setting up a virtuous cycle has the potential to encourage good metadata practice. If good metadata drives functionality that is available to the user then the user will put that metadata in. But more than that, if the schema is flexible enough they will also actively engage in improving it if that improves the functionality.
The system I’ve described has two weaknesses – limited structured metadata on what the digital objects themselves actually are and as a result very limited possibilities for capturing the relationships between them. Because we’ve focussed on “merely” backing up our provenance information beyond that intrinsic to the objects themselves is limited. It is reasonably easy to offer the opportunity to collect more structured information on the objects themselves – when configuring an instrument offer a selection of known types. If a known type of instrument is selected then this can be flagged to the system which will then know to post-process the data file to extract more metadata, perhaps just enriching the record but perhaps also converting it to some form of standard file type. In turn automating this process means that the provenance of the transformation is easily captured. In standard form the system might offer in situ visualisation or other services direct to the users providing an immediate benefit. Such a library of transformations and instrument types could be offered as a community resource, ideally allowing users to contribute to build the library up.
Another way to introduce this “single step workflow” concept to the user is suggested above. Let us say that by creating an “analysis” folder on their local system this gets replicated to the backup server. The next logical step is to create a few different folders, that receive the results of different types of analysis. These then get indexed by the server as separate types but without further metadata. So they might separate mass spectrometry analyses from UV-Vis but not have the facility to search either of these for peaks in specific ranges. If a “peak processing” module is available that provides a search interface or visualisation then the user has an interest in registering those folders as holding data that should be submitted to the module. In doing this they are saying a number of things about the data files themselves – firstly that they should have peaks but also possibly getting them converted to a standard format, perhaps saying what the x and y coordinates of the data are, perhaps providing a link to calibration files.
The transformed files themselves can be captured by the same data model as the main database, but because they are automatically generated the full provenance can be captured. As these full provenance files populate the database and become easier to find and use the user in turn will look at those raw files and ask what can be done to make them more accessible and findable. It will encourage them to think more carefully about the metadata collection for their local analyses. Overall it provides a path that at each step offers a clear return for capturing a little more metadata in a little more structured form. It provides the opportunity to take the user by the hand, solve their immediate problem and carry them further along that path.
Building the full provenance graph
Once single step transformations are available then chaining them together to create workflows is an obvious next step. The temptation at this point is to try to build a complete system in which the researcher can work but in my view this is doomed to failure. One of the reasons workflow systems tend to fail is that they are complex and fragile. They work well where the effort involved in a large scale data analysis justifies their testing and development but aren’t very helpful for ad hoc analyses. What is more workflow systems generally require that all of the relevant information and transformation be available. This is rarely the case in an experimental lab where some crucial element of the process is likely to be offline or physical.
Therefore in building up workflow capabilities within this system it is crucial to build in a way that creates value when only a partial workflow is possible. Again this is surprisingly common – but relatively unexplored. Collecting a set of data together, applying a single transformation, checking for known types of data artefacts. All of these can be useful without needing an end to end analysis pipeline. In many cases implied objects can be created and tracked without bothering the user until they interested. For instance most instruments require samples. The existence of a dataset implies a sample. Therefore the system can create a record of a sample – perhaps of a type appropriate to the instrument, although that’s not necessary. If a given user does runs on three instruments, each with five samples over the course of a day its a reasonable guess that those are the same five samples. The system could then offer to link those records together so a record is made that those datasets are related.
From here its not a big mental leap to recording the creation of those samples in another digital object, perhaps dropping it into a directory labelled “samples”. The user might then choose to link that record with the sample records. As the links propagate from record of generation, to sample record, to raw data to analysis, parts of the provenance graphs are recorded. The beauty of the approach is that if there is a gap in the graph it doesn’t reduce the base functionality the user enjoys, but if they make the effort to link it up then they can suddenly release all the additional functionality that is possible. This is essentially the data model that we proposed in the LabTrove paper but without the need to record the connections up front.
Challenges and complications
None of the pieces of this system are terribly difficult to build. There’s an interesting hardware project – how best to build the box itself and interact with the instrument controller computers. All while keeping the price of the system as low as possible. There’s a software build to manage the server system and this has many interesting user experience issues to be worked through. The two clearly need to work well together and at the same time support an ecosystem of plugins that are ideally contributed by user communities.
The challenge lies in building something where all these pieces work well together and reliably. Actually delivering a system that works requires rapid iteration on all the components while working with (probably impatient and busy) researchers who want to see immediate benefits. The opportunity if it can be got right is immense. While I’m often sceptical of the big infrastructure systems in this space that are being proposed and built, they do serve specific communities well. The bit that is lacking is often the interface onto the day to day workings of an experimental laboratory. Something like this system could be the glue-ware that brings those much more powerful systems into play for the average researcher.
Some notes on provenance
These are not particularly new ideas, just an attempt to rewrite something that’s been a recurring itch for me for many years. Little of this is original and builds on thoughts and work of a very large range of people including the Frey group current and past, members of the National Crystallography Service, Dan Hagon, Jennifer Lin, Jonathan Dugan, Jeff Hammerbacher, Ian Foster (and others at Chicago and the Argonne Computation Institute), Julia Lane, Greg Wilson, Neil Jacobs, Geoff Bilder, Kaitlin Thaney, John Wilbanks, Ross Mounce, Peter Murray-Rust, Simon Hodson, Rachel Bruce, Anita de Waard, Phil Bourne, Maryann Martone, Tim Clark, Titus Brown, Fernando Perez, Frank Gibson, Michael Nielsen and many others I have probably forgotten. If you want to dig into previous versions of this that I (was involved with) writing then there are pieces in Nature (paywalled unfortunately), Automated Experimentation, the PLOS ONE paper mentioned above as well as some previous blog posts.Â
The how to copy the data around problem is indeed hard, but solved:
https://git-annex.branchable.com/
Manu sites (us for example) are making a big push to get the data out of the lab and onto central systems, but that doesn’t negate the basic idea you have here about convention over configuation
I’m not sure if you’d see this as part of the solution, or part of the problem. I’m working on (yet another?) RDM “system” – https://github.com/gklyne/annalist, http://annalist.net/ – but I am trying to address some of the issues you mention:
Backup – underlying data is inherently git- friendly, so easily versioned (as a developer, github is my main backup ;) )
Access to data from different locations – built around web technologies, with mobile-device-friendly “responsive” pages.
Metadata – I’m not sure there’s a universally clear data/metadata distinction, but one of the goals is to be able to annotate (say) images or other data with relevant contextual or observational information
Provenance – plans to capture provenance info alongside data
Findable – google-friendly textual data exposed through http, but with labelled fields to allow more semantic search.
Instrument data – simple web APIs allow data to be added by external processes
Cataloging – doesn’t depend on predefined schema, do cataloging fields can be added as needs are recognised
Making “pieces work well together” – web technology provides a pretty good base layer, though there’s plenty to add. Underlying data is not “locked away” by the application, but presented through the web in a readily used format.
A key notion I’m trying to develop us to allow “just enough structure” at any time, which I think could go some way to addressing some of the concerns you describe. I think this is close to your idea of “The lack of structure, while preserving enough contextual information to be locally useful, can be seen as a strength – any data type can be collected and stored without it needing to be available in some sort of schema.”
It’s early days yet, and several of the pieces I describe have yet to be realized. I’m hoping to reach a “minimum viable product” stage in a couple of months from now.
Does anything here resonate?
Hi Cameron,
This provides another benefit. If you add another ethernet card to the box, it can act as a hardware firewall between the lab and the institution. There are many many lab instruments that are driven by downlevel versions of Windows, and which therefore cannot be connected to institutional networks. This seemingly trivial problem has significant consequences for data management.
regards,
Chris