I spent today at an interesting meeting at Talis headquarters where there was a wide range of talks. Most of the talks were liveblogged by Andy Powell and also by Owen Stephens (who has written a much more comprehensive summary of Andy’s talk) and there will no doubt be some slides and video available on the web in future. The programme is also available. Here I want to focus on Andy Powell’s talk (slides), partly because he obviously didn’t liveblog it but primarily because it crystallised for me many aspects of the way we think about Institutional Repositories. For those not in the know, these are warehouses that are becoming steadily more popular, run generally by unversities to house their research outputs, in most cases peer reviewed papers. Self archiving of some version of published papers is the so called ‘Green Route’ to open access.
I spent today at an interesting meeting at Talis headquarters where there was a wide range of talks. Most of the talks were liveblogged by Andy Powell and also by Owen Stephens (who has written a much more comprehensive summary of Andy’s talk) and there will no doubt be some slides and video available on the web in future. The programme is also available. Here I want to focus on Andy Powell’s talk (slides), partly because he obviously didn’t liveblog it but primarily because it crystallised for me many aspects of the way we think about Institutional Repositories. For those not in the know, these are warehouses that are becoming steadily more popular, run generally by unversities to house their research outputs, in most cases peer reviewed papers. Self archiving of some version of published papers is the so called ‘Green Route’ to open access.
The problem with institutional repositories in their current form is that academics don’t use them. Even when they are being compelled there is massive resistance from academics. There are a variety of reasons for this: academics don’t like being told how to do things; they particularly don’t like being told what to do by their institution; the user interfaces are usually painful to navigate. Nonetheless they are a valuable part of the route towards making more research results available. I use plenty of things with ropey interfaces because I see future potential in them. Yet I don’t use either of the repositories in the places where I work – in fact they make my blood boil when I am forced to. Why?
So Andy was talking about the way repositories work and the reasons why people don’t use them. He had already talked about the language problem. We always talk about ‘putting things in the repository’ rather than ‘making them available on the web’. He had mentioned already that the institutional nature of repositories does not map well onto the social networks of the academic users which probably bear little relationship with institutions and are much more closely aligned to discipline and possibly geographic boundaries (although they can easily be global).
But for me the key moment was when Andy asked ‘How many of you have used SlideShare’. Half the people in the room put their hands up. Most of the speakers during the day pointed to copies of their slides on SlideShare. My response was to mutter under my breath ‘And how many of them have put presentations in the institutional repository?’ The answer to this; probably none. SlideShare is a much better ‘repository’ for slide presentations than IRs. There are more there, people may find mine, it is (probably) Google indexed. But more importantly I can put slides up with one click, it already knows who I am, I don’t need to put in reams of metadata, just a few tags. And on top of this it provides added functionality including embedding in other web documents as well as all the social functions that are a natural part of a ‘Web2.0’ site.
SlideShare is a very good model of what a Repository can be. It has issues. It is a third party product, it may not have long term stability, it may not be as secure as some people would like. But it provides much more of the functionality that I want from a service for making my presentations available on the web. It does not serve the purpose of an archive – and maybe an institutional repository is better in that role. But for the author, the reason for making things available is so that people use them. If I make a video that relates to my research it will go on YouTube, Bioscreencast, or JoVE, not in the institutional repository, I put research related photos on Flickr, not in the institutional repository, and critically, I leave my research papers on the websites of the journal that published them, and cannot be bothered with the work required to put them in the institutional repository.
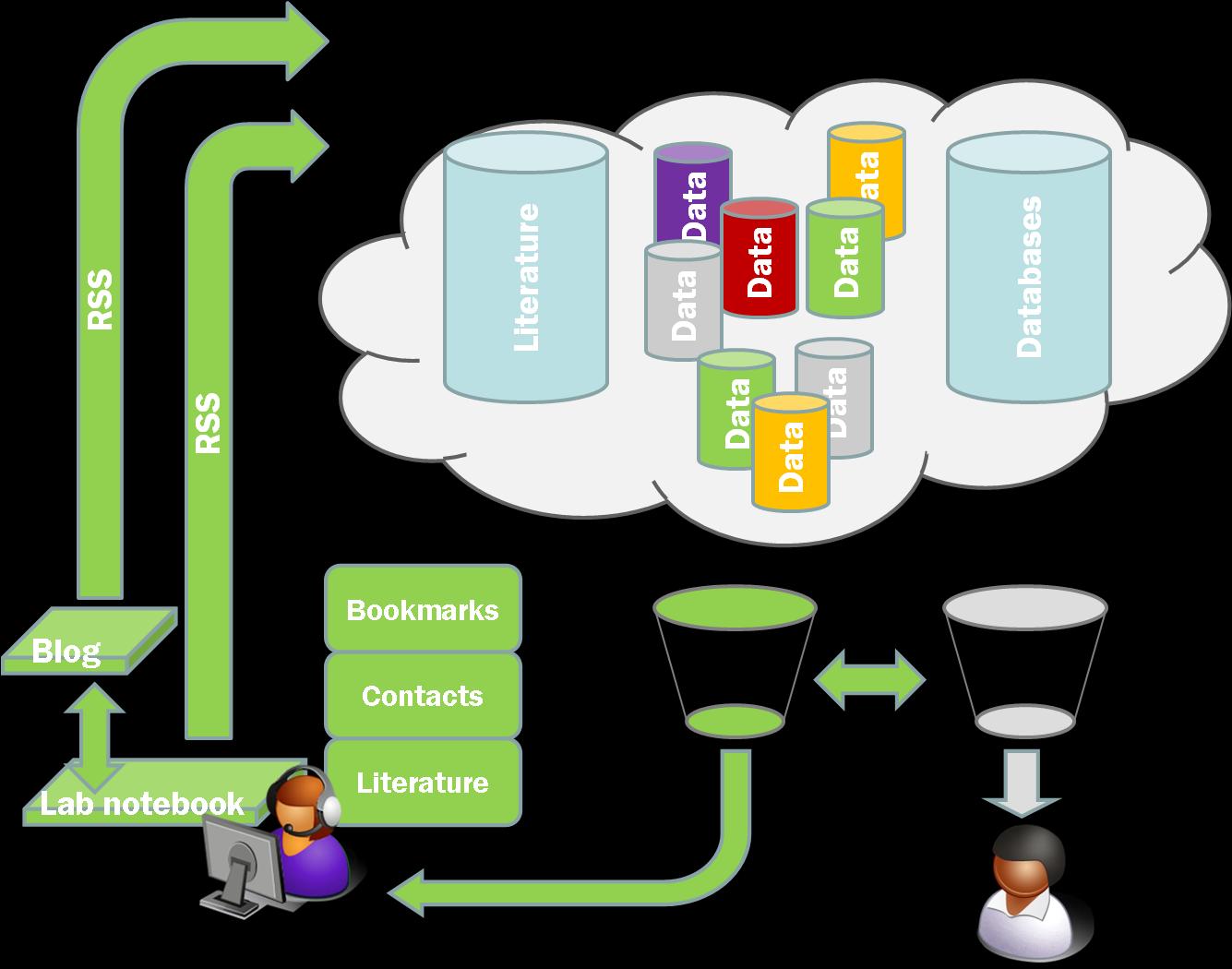
Andy was arguing for global discipline specific repositories. I would suggest that the lesson of the Web2.0 sites is that we should have data type specific repositories. FlickR is for pictures, SlideShare for presentations. In each case the specialisation enables a sort of implicit metadata and for the site to concentrate on providing functionality that adds value to that particular data type. Science repositories could win by doing the same. PDB, GenBank, SwissProt deal with specific types of data. Some might argue that GenBank is breaking under the strain of the different types and quantities of data generated by the new high throughput sequencing tools. Perhaps a new repository is required that is specially designed for this data.
So what is the role for the institutional repository? The preservation of data is one aspect. Pulling down copies of everything to provide an extra backup and retain an institutional record. If not copying then indexing and aggregating so as to provide a clear guide to the institutions outputs. This needn’t be handled in house of course and can be outsourced. As Paul Miller suggested over lunch, the role of the institution need not be to keep a record of everything, but to make sure that such a record is kept. Curation may be another, although that may be too big a job to be tackled at institutional level. When is a decision made that something isn’t worth keeping anymore? What level of metadata or detail is worth preserving?
But the key thing is that all of this should be done automatically and must not require intervention by the author. Nothing drives me up the wall more than having to put the same set of data into two subtly different systems more than once. And as far as I can see there is no need to do so. Aggregate my content automatically, wrap it up and put it in the repository, but I don’t want to have to deal with it. Even in the case of peer reviewed papers it ought to be feasible to pull down the vast majority of the metadata required. Indeed, even for toll access publishers, everything except the appropriate version of the paper. Send me a polite automated email and ask me to attach that and reply. Job done.
For this to really work we need to take an extra step in the tools available. We need to move beyond files that are simply ‘born digital’ because these files are in many ways still born. This current blog post, written in Word on the train is a good example. The laptop doesn’t really know who I am, it probably doesn’t know where I am, and it has not context for the particular word document I’m working on. When I plug this into the WordPress interface at OpenWetWare all of this changes. The system knows who I am (and could do that through OpenID). It knows what I am doing (writing a Blog post) and the Zemanta Firefox plug in does much better than that, suggesting tags, links, pictures and keywords.
Plugins and online authoring tools really have the potential to automatically generate those last pieces of metadata that aren’t already there. When the semantics comes baked in then the semantic web will fly and the metadata that everyone knows they want, but can’t be bothered putting in, will be available and re-useable, along with the content. When documents are not only born digital but born on and for the web then the repositories will have probably still need to trawl and aggregate. But they won’t have to worry me about it. And then I will be a happy depositor.