
 This is an approximate rendering of my comments as part of the closing panel of “The End of Scientific Journal? Transformations in Publishing” held at the Royal Society, London on 27 November 2015. It should be read as a reconstruction of what I might have said rather than an accurate record. The day had focussed on historical accounts of “journals” as mediators of both professional and popular research communications. A note of the meeting will be published. Our panel was set the question of “will the journal still exist in 2035”.
This is an approximate rendering of my comments as part of the closing panel of “The End of Scientific Journal? Transformations in Publishing” held at the Royal Society, London on 27 November 2015. It should be read as a reconstruction of what I might have said rather than an accurate record. The day had focussed on historical accounts of “journals” as mediators of both professional and popular research communications. A note of the meeting will be published. Our panel was set the question of “will the journal still exist in 2035”.
Over the course of 2015 I’ve greatly enjoyed being part of the series of meetings looking at the history of research communications and scientific journals in the past. In many cases we’ve discovered that our modern concerns, today the engagement of the wider public, the challenge of expertise, are not at all new, that many of the same issues were discussed at length in the 17th, 18th and 19th centuries. And then there are moments of whiplash as something incomprehensible streaks past: Pietro Corsi telling us that dictionaries were published as periodicals; Aileen Fyfe explaining that while papers given to at Royal Society meetings were then refereed, the authors could make only make “verbal” not intellectual changes to the text in response; Jon Topham telling us that chemistry and physics were characterised under literature in the journals of the early 19th century.
So if we are to answer the exam question we need to address the charge that Vanessa Heggie gave us in the first panel discussion. What has remained the same? And what has changed? If we are to learn from history then we need to hold ourselves to a high standard in trying to understand what it is (not) telling us. Prediction is always difficult, especially about the future…but it wasn’t Niels Bohr who first said that. A Dane would likely tell us that “det er svært at spÃ¥, især om fremtiden” is a quote from Storm Peterson or perhaps Piet Hein, but it probably has deeper roots. It’s easy to tell ourselves compelling stories, whether they say that “everything has changed” or that “it’s always been that way”, but actually checking and understanding the history matters.
So what has stayed the same? We’ve heard throughout today the importance of groups, communities. Of authors, of those who were (or were trying to be) amongst the small group of paid professors at UK universities. Of the distinctions between communities of amateurs and of professionals. We’ve heard about language communities, of the importance of who you know in being read at the Royal Society and of the development of journals as a means of creating research disciplines. I think this centrality of communities, of groups, of clubs is a strand that links us to the 19th century. And I think that’s true because of the nature of knowledge itself.
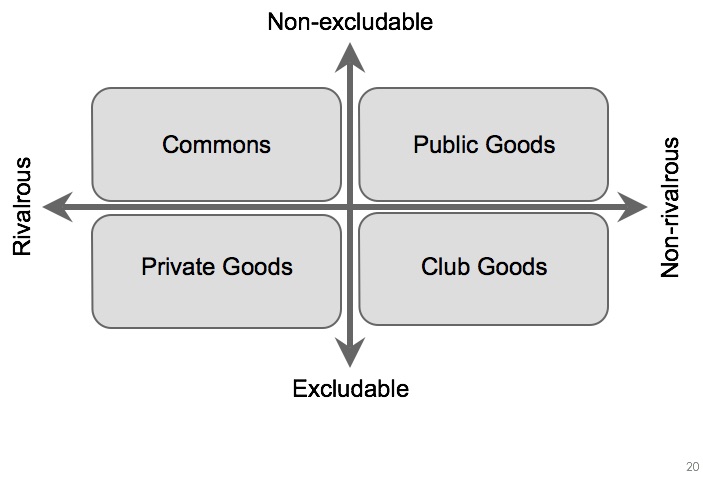
Knowledge is a slippery concept, and I’ve made the argument elsewhere, so for now I’ll just assert that it belongs in the bottom right quadrant of Ostrom‘s categorisation of goods. Knowledge is non-rivalrous – if I give it to you I still have it – but also excludable – I can easily prevent you from having it, by not telling you, or by locking it up behind a paywall, or simply behind impenetrable jargon. This is interesting because Buchannan‘s work on the economics of clubs show us that it is precisely the goods in this quadrant which are used to sustain clubs and make them viable.
The survival of journals, or of scholarly societies, disciplines or communities, therefore depends on how they deploy knowledge as a club good. To achieve this deployment it is necessary to make that knowledge, the club good, less exclusive, and more public. What is nice about this view is that it allows us, to borrow Aileen Fyfe’s language, to talk about “public-making” (Jan Velterop has used the old term “publicate” in a similar way) as an activity which includes public engagement, translation, and – to Rebekah Higgitt‘s point – education as well as scholarly publishing as we traditionally understand it as overlapping subsets of this broader activity.
But what has changed? I would argue that the largest change in the 20th century was one of scale. The massive increase in the scale and globalisation of the research enterprise, as well as the rise of literacy meant that traditional modes of coordination, within scholarly societies and communities, and beyond to interested publics were breaking down. To address this coordination problem we took knowledge as a club good and privatised it, introducing copyright and intellectual property as a means of engaging corporate interests to manage the coordination problem for us. It is not an accident that the scale up, the introduction of copyright and IP to scholarly publishing, and scholarly publishing becoming (for the first time) profitable all co-incide. The irony of this, is that by creating larger, and clearly defined markets, we solved the problem of market scale that troubled early journals that needed to find both popular and expert audiences, by locking wider publics out.
The internet and the web also changed everything, but its not the cost of reproduction that most matters. The critical change for our purpose here is the change in the economics of discovery. As part of our privatisation of knowledge we parcelled it up into journals, an industrial broadcast mechanism in which one person aims with as much precision as possible to reach the right, expert, audience. The web shifts the economics of discovering expertise in a way that makes it viable to discover, not the expert who knows everything about a subject, but the person who just happens to have the right piece of knowledge to solve a specific problem.
These two trends are pulling us in opposite directions. The industrial model means creating specialisation and labelling. The creation of communities and niches that are, for publishers, markets that can be addressed individually. These communities are defined by credentialling and validation of deep expertise in a given subject. The ideas of micro-expertise, of a person with no credentials having the key information or insight radically undermines the traditional dynamics of scholarly group formation. I don’t think it is an accident that those scholarly communities that Michèle Lamont identifies as having the most stable self conception have a tendency to being the most traditional in terms of their communication and public engagement. Lamont identifies history (but not as Berris Charnley reminded me the radicals from the history of science here today!) and (North American analytical) philosophy in this group. I might add synthetic chemistry from my own experience as examples.
It is perhaps indicative of the degree of siloing that I’m a trained biochemist at a history conference, telling you about economics – two things I can’t claim any deep expertise in – and last week I gave a talk from a cultural theory perspective. I am merrily skipping across the surface of these disciplines, dipping in a little to pull out interesting connections and no-one has called me on it*. You are being forced, both by the format of this panel, and the information environment we inhabit, to assess my claims not based on my PhD thesis topic or my status or position, but on how productively my claims and ideas are clashing with yours. We discover each other, not through the silos of our disciplinary clubs and journals, but through the networked affordances that connect me to you, that in this case we could trace explicitly via Berris Charnley and Sally Shuttleworth. That sounds to me rather more like the 19th century world we’ve been hearing about today than the 20th century one that our present disciplinary cultures evolved in.
This restructuring of the economics of discovery has profound implications for our understanding of expertise. And it is our cultures of expertise that form the boundaries of our groups – our knowledge clubs – whether they be research groups, disciplines, journals, discussion meetings or scholarly societies. The web shifts our understanding of public-making. It shifts from the need to define and target the expert audience through broadcast – a one-to-audience interaction – to a many-to-many environent in which we aim to connect with the right person to discover the right contribution. The importance of the groups remains. The means by which they can, and should want to communicate has changed radically.
The challenge lies, not in giving up on our ideas of expertise, but in identifying how we can create groups that both develop shared understanding that enables effective and efficient communication internally but are also open to external contributions. It is not that defining group boundaries doesn’t matter, it is crucial, but that the shape and porosity of those boundaries needs to change. Journals have played a role throughout their history in creating groups, defining boundaries, and validating membership. That role remains important, it is just that the groups, and their cultures, will need to change to compete and survive.
We started 2015 with the idea that the journal was invented in 1665. This morning we heard from Jon Topham that the name was first used in the early 19th century, but for something that doesn’t look much like what we would call a journal today. I believe in 20 years we will still have things called journals, and they will be the means of mediating communications between groups, including professional scholars and interested publics. They’ll look very different from what we have today but their central function, of mediating and expressing identity for groups will remain.
* This is not quite true. Martin Eve has called me on skipping too lightly across the language of a set of theoretical frameworks from the humanities without doing sufficient work to completely understand them. I don’t think it is co-incidental that Martin is a cultural and literary scholar who also happens to be a technologist, computer programmer and deeply interested in policy design and implementation, as well as the intersection of symbolic and financial economies.







")
