
Packaging Data: The core problem in general data sharing?
In this final post about the IDRC data sharing pilot project I want to close the story that started with an epic rant a few months ago. To recap, I had data from the project that I wanted to deposit in Zenodo. Ideally I would have found an example of doing this well, organised my data files in a similar way, zipped up a set of directories with a structured manifest or catalogue in a recognised format and job done. It turned out to not be so easy.
In particular there were two key gaps. The first was my inability to find specific guidance on how to organise the kinds of data that I had. These were, amongst other things, interview recordings and transcripts. You’d think that it would be common enough, but I could not find any guidance on standard metadata schema or the best way to organise the data. That is not the say that it isn’t out there. There is likely some very good guidance, and certainly expertise, but I struggled to find it. It was not very discoverable, and as I said at the time, if I can’t find it then its highly unlikely that the ‘average’ non-computational researcher generating small scale data sets will be able to. In the end the best advice I got on organizing the package was ‘organise it in the way that makes most sense for the kinds of re-use you’d expect’, so I did.
The second problem was how to create a manifest or catalogue of the data in a recognised format. First there was still the question of format, but more importantly there is a real lack of tools to generate well formed and validated metadata. You’d think there would be a web-based system to help you generate some basic dublin core or other standard metadata but the only things I could find were windows only and/or commercial. Both of which are currently non-starters for me. This really illustrates a big gap in RDM thinking. Big projects manage data which gets indexed, collected, and catalogued into specialist systems. Single data objects get reasonable support with generic data repositories with a form based system that lets you fill in key metadata. But for any real project, you’re going to end up with a package of data with complex internal relationships. You need a packager.
At this point, after I’d posted my rant, Petie Sefton from the University of Technology Sydney got in touch. Petie has worked for many years on practical systems that help the average scholar manage their stuff. His work mixes the best of pragmatic approaches and high standards of consistency. And he’d been working on a tool that did exactly what I needed. Called Calcyte, it is an approach to data packaging that is designed to work for the average researcher and produce an output that meets high standards. Petie has also written about how we used the tool and presented this at eResearch Australasia.
What does Calcyte do?
Calcyte is ‘is experimental early- stage open source software’ that generates ‘static-repository[s] for human-scale data collections’. We worked with Petie running the software and me filling in the info, although I could potentially have run it myself. What this looked like from a user perspective was very simple. First Petie and I shared a folder (we used Google Drive, sue me) where we could work together. After the first run of the tool each of the subdirectories in my folder had a CATALOG file, which was an Excel file (yeah, sue us again…).
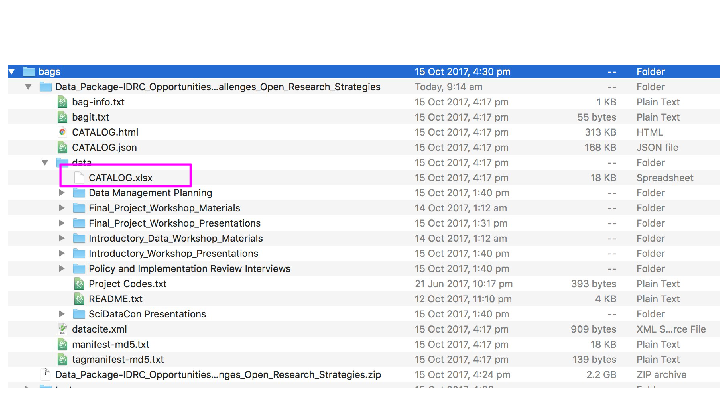
Opening up the Excel file showed a partially filled in spreadsheet with information about the files in that directory. Which I then filled out.

Running the tool again generated a top level CATALOG.html file, which is a human-readable guide to all the files in the package. The information and relationships is all hoovered up from the entries in the various spreadsheets.

…but more than that. The human-readable file has relationships both about the files, like for instance copyright assignments, people and external identifiers where available. Here for instance, we’ve done something which is generally close to impossible, noting that I’m the creator of a file, with links to my ORCID, but also that the Copyright belongs to someone else (in this case the IDRC) while also providing file-level licensing information.
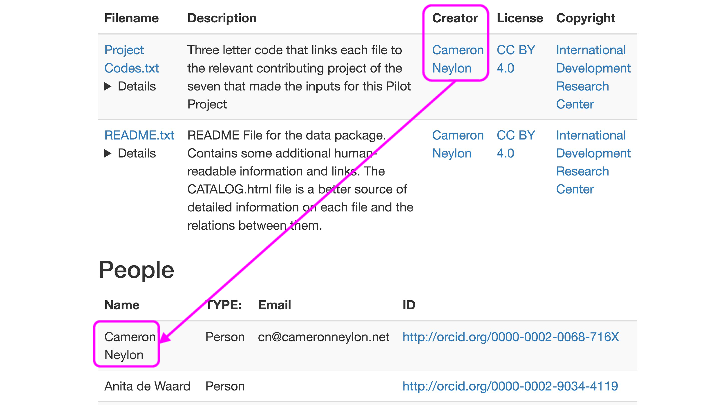
But it’s not just information about the files but also between files, like for instance that one is a translation of another…
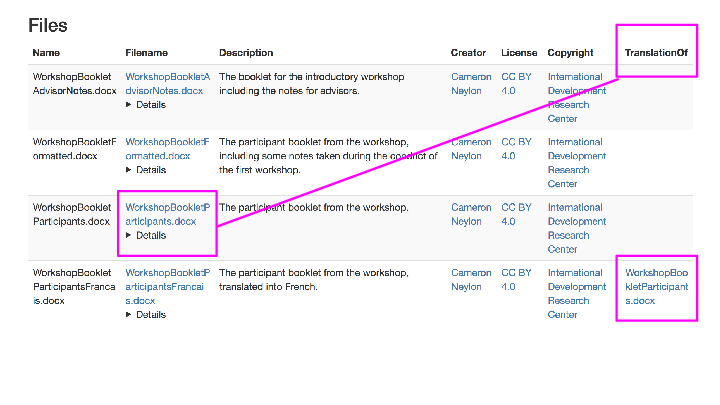
All of this is also provided in machine-readable form as JSON-LD and it is all basically schema.org metadata. We rinsed and repeated several times to refine what we were doing, how to represent things, until we were happy. Things that were not obvious included what the canonical ID for the project was (we settled on the DOI for the formally published grant proposal), how to represent the role of interviewee as opposed to interviewer, and a whole series of other niggly things, that mostly related to questions of granularity, or particular choices of how to represent relationships (versions of objects that were not updates or mere format shifts).
Finally all of this was packaged up and sent of to Zenodo. It is a shame that Zenodo can’t (at the moment) surface the CATALOG.html in the root directly as a preview. If it did and this ‘DataCrate’ approach caught on then it is easy to imagine the generation of a set of tools that could help. I can imagine (in fact I’ve already started doing this) writing out simple CSV files in computational projects that record provenance that could then be processed to support the production of the CATALOG files. Working in a shared folder with Excel files actually worked extremely well, the only real issue being Excel isn’t great for text data entry, and its habit of screwing up character encodings. It is easy to imagine an alternative web-based or browser-based approach to that walks you through a cycle of data entry until you’re happy. Adding on a little conventional configuration to guide a user towards standard ways of organising file sets could also be helpful. And actually doing this as you went with a project could help not just to organise your data for sharing, but also provide much better metadata records as you were going.
The happy medium
When I was getting fed up, my complaint was really that online support seemed to be either highly technical (and often inconsistent) advice on specific schema or so general as to be useless. What was missing was what PT calls ‘human-scale’ systems for when you’ve got too many objects to be uploading them all one by one, but you have too few, or your objects are too specialist for there to be systems to support you to do that. For all that we talk about building systems and requiring data sharing, this remains a gap which is very poorly supported, and as a result we are getting less data sharing than would be ideal, and what data sharing there is is less useful than it could be. The challenge of the long tail of research data production remains a big one.
In the report we note how crucial it is that there be support where researchers need it, if the goal of changing culture is to be achieved. Researchers struggle both with good data management within projects and with packaging data up in a sensible fashion when subject to data sharing mandates at formal publication. Because we struggle, the data that is shared is not so useful, so the benefits to the researcher are less likely. Add this to a certain level of antagonism caused by the requirement for DMP provision at grant submission, and a virtually complete lack of follow-up on the part of funders, and the end result is not ideal. Of course, doing the practical work of filling these gaps with good (enough) tools is neither sexy nor easily fundable. Implementation is boring, as is maintenance, but its what’s required if we want to move towards a culture of data sharing and re-use. The kind of work that Petie and his group do needs more support.
Images in this post are (c) Peter (Petie) Sefton, taken from http://ptsefton.com/2017/10/19/datacrate.htm










 Flickr
Flickr Slideshare
Slideshare