
Two things last week gave me more cause to think a bit harder about the RSS feeds from our LaBLog and how we can use them. First, when I gave my talk at UKOLN I made a throwaway comment about search and aggregation. I was arguing that the real benefits of open practice would come when we can use other people’s filters and aggregation tools to easily access the science that we ought to be seeing. Google searching for a specific thing isn’t enough. We need to have an aggregated feed of the science we want or need to see delivered automatically. i.e. we need systems to know what to look for even before the humans know it exists. I suggested the following as an initial target;
‘If I can automatically identify all the compounds recently made in Jean-Claude’s group and then see if anyone has used those compounds [or similar compounds] in inhibitor screens for drug targets then we will be on our way towards managing the information’
The idea here would be to take a ‘Molecules’ feed (such as the molecules Blog at UsefulChem or molecules at Chemical Blogspace) extract the chemical identifiers (InChi, Smiles, CML or whatever) and then use these to search feeds from those people exposing experimental results from drug screening. You might think some sort of combination of Yahoo! Pipes and Google Search ought to do it.
So I thought I’d give this a go. And I fell at the first hurdle. I could grab the feed from the UsefulChem molecules Blog but what I actually did was set up a test post in the Chemtools Sandpit Blog. Here I put the InChi of one of the compounds from UsefulChem that was recently tested as a falcipain 2 inhibitor. The InChi went in as both clear text and as the microformat approach suggested by Egon Willighagen. Pipes was perfectly capable of pulling the feed down, and reducing it to only the posts that contained InChi’s but I couldn’t for the life of me figure out how to extract the InChi itself. Pipes doesn’t seem to see microformats. Another problem is that there is no obvious way of converting a Google Search (or Google Custom Search) to an RSS feed.
Now there may well be ways to do this, or perhaps other tools to do it better but they aren’t immediately obvious to me. Would the availability of such tools help us to take the Open Research agenda forwards? Yes, definitely. I am not sure exactly how much or how fast but without easy to use tools, that are well presented, and easily available, the case for making the information available is harder to make. What’s the point of having it on the cloud if you can’t customise your aggregation of it? To me this is the killer app; being able to identify, triage, and collate data as it happens with easily useable and automated tools. I want to see the stuff I need to see in feed reader before I know it exists. Its not that far away but we ain’t there yet.
The other thing this brought home to me was the importance of feeds and in particular of rich feeds. One of the problems with Wikis is that they don’t in general provide an aggregated or user configurable feed of the site in general or a name space such as a single lab book. They also don’t readily provide a means of tagging or adding metadata. Neither Wikis nor Blogs provide immediately accessible tools that provide the ability to configure multiple RSS feeds, at least not in the world of freely hosted systems. The Chemtools blogs each put out an RSS feed but it doesn’t currently include all the metadata. The more I think about this the more crucial I think it is.
To see why I will use another example. One of the features that people liked about our Blog based framework at the workshop last week was the idea that they got a catalogue of various different items (chemicals, oligonucleotides, compound types) for free once the information was in the system and properly tagged. Now this is true but you don’t get the full benefits of a database for searching, organisation, presentation etc. We have been using DabbleDB to handle a database of lab materials and one of our future goals has been to automatically update the database. What I hadn’t realised before last week was the potential to use user configured RSS feeds to set up multiple databases within DabbleDB to provide more sophisticated laboratory stocks database.
DabbleDB can be set up to read RSS or other XML or JSON feeds to update as was pointed out to me by Lucy Powers at the workshop. To update a database all we need is a properly configured RSS feed. As long as our templates are stable the rest of the process is reasonably straightforward and we can generate databases of materials of all sorts along with expiry dates, lot numbers, ID numbers, safety data etc etc. The key to this is rich feeds that carry as much information as possible, and in particular as much of the information we have chosen to structure as possible. We don’t even need the feeds to be user configurable within the system itself as we can use Pipes to easily configure custom feeds.
We, or rather a noob like me, can do an awful lot with some of the tools already available and a bit of judicious pointing and clicking. When these systems are just a little bit better at extracting information (and when we get just a little bit better at putting information in, by making it part of the process) we are going to be doing lots of very exciting things. I am trying to keep my diary clear for the next couple of months…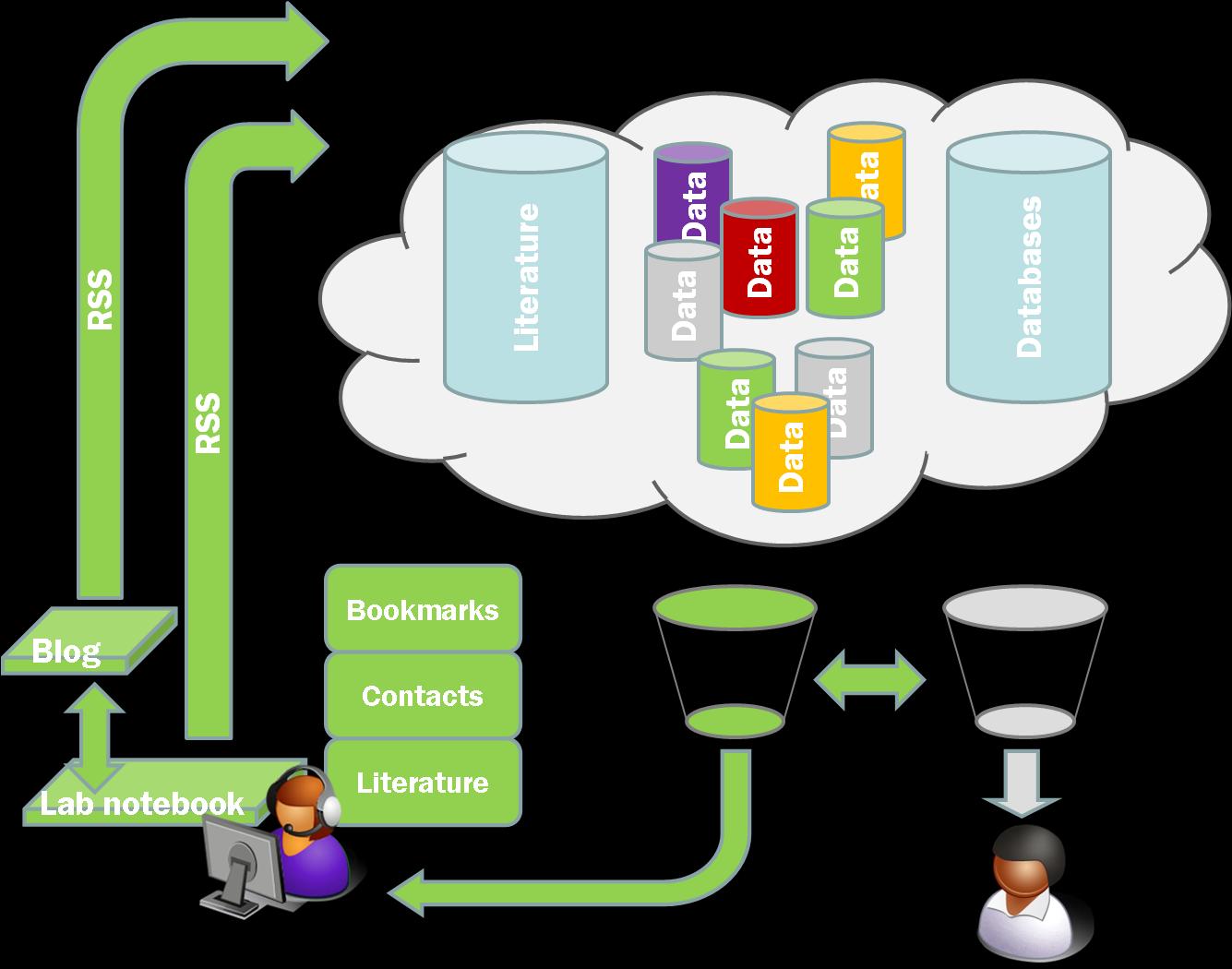
Using RSS feeds to track molecule citations is something that I was hopeful about at the start of the project but it turned out not to be as useful as I had hoped:
http://drexel-coas-elearning.blogspot.com/2005/12/rss-aware-chemical-research.html
http://usefulchem.blogspot.com/2005/12/querychem.html
I used CAS numbers and MSN (because it had RSS feeds and Google didn’t, although Google Blog Search does). It does work but it doesn’t help that much to know that someone used very common molecules like benzaldehyde and the ones never made before are very unlikely to show up anywhere else anytime soon.
We also played with CMLRSS but that has not made it part of our workflow yet:
http://usefulchem.blogspot.com/2006/08/cml-rss-reader-in-java.html
At this point in time it seems that exhaustive tracking is not necessary for humans to find other humans working on relevant projects. It just takes one data intersection to get a hit (Deepak made this point at the Science Blogging conf) and Sitemeter is pretty efficient for that function for our group. That doesn’t mean that down the road that will still be true, especially when there is more automation, but for now this is not the bottleneck.
But if we are to rely on a tagging system, I am leaning towards the InChIKey, simply because long InChIs are not handled well by Google. But we’re tagging experiments with both InChI and InChIKey and we’ll see. At least that is a good way to retrieve our own experiments through Google.
In terms of using powerful search algorithms on open chemical data, like substructure searching, I’m putting my bets on ChemSpider – that’s why we’re moving from the usefulchem-molecules blog to CS for the management and storage of structures and spectra.
I definitely appreciate that you are experimenting with this – it is hard to predict exactly what combination of tools will work in a given environment.
Using RSS feeds to track molecule citations is something that I was hopeful about at the start of the project but it turned out not to be as useful as I had hoped:
http://drexel-coas-elearning.blogspot.com/2005/12/rss-aware-chemical-research.html
http://usefulchem.blogspot.com/2005/12/querychem.html
I used CAS numbers and MSN (because it had RSS feeds and Google didn’t, although Google Blog Search does). It does work but it doesn’t help that much to know that someone used very common molecules like benzaldehyde and the ones never made before are very unlikely to show up anywhere else anytime soon.
We also played with CMLRSS but that has not made it part of our workflow yet:
http://usefulchem.blogspot.com/2006/08/cml-rss-reader-in-java.html
At this point in time it seems that exhaustive tracking is not necessary for humans to find other humans working on relevant projects. It just takes one data intersection to get a hit (Deepak made this point at the Science Blogging conf) and Sitemeter is pretty efficient for that function for our group. That doesn’t mean that down the road that will still be true, especially when there is more automation, but for now this is not the bottleneck.
But if we are to rely on a tagging system, I am leaning towards the InChIKey, simply because long InChIs are not handled well by Google. But we’re tagging experiments with both InChI and InChIKey and we’ll see. At least that is a good way to retrieve our own experiments through Google.
In terms of using powerful search algorithms on open chemical data, like substructure searching, I’m putting my bets on ChemSpider – that’s why we’re moving from the usefulchem-molecules blog to CS for the management and storage of structures and spectra.
I definitely appreciate that you are experimenting with this – it is hard to predict exactly what combination of tools will work in a given environment.
I suspect you are on to something significant here. Having spent the last couple of years immersed in RSS feeds I have learnt one major lesson – collections of RSS feeds behave a lot more like social (maybe even neural) networks than databases. People are the best filters and RSS tools that help you find people will help you rule the world.
(that’s how I found you and your excellent blog!)
Ive been doing this in the world of education from an technology background and plan to move in to the world of open science. I’m a noob in this field and planning to clear my diary over the next few months. Hopefully we can hook up and trade ideas.
Fang – Mike Seyfang
I suspect you are on to something significant here. Having spent the last couple of years immersed in RSS feeds I have learnt one major lesson – collections of RSS feeds behave a lot more like social (maybe even neural) networks than databases. People are the best filters and RSS tools that help you find people will help you rule the world.
(that’s how I found you and your excellent blog!)
Ive been doing this in the world of education from an technology background and plan to move in to the world of open science. I’m a noob in this field and planning to clear my diary over the next few months. Hopefully we can hook up and trade ideas.
Fang – Mike Seyfang
@Jean-Claude. I think you’ve hit the nail on the head actually. YOu certainly don’t want to see every molecule coming through on the feed. I would probably want to see the new molecules you’ve made, but perhaps someone else is interested in the molecules you are getting in. This is why the rich feed is so necessary. I agree at the moment that a google seach is perfectly capable of serving the person to person needs. Where I am thinking is the machine to machine or person through machine to other machines communication that you have often talked about. Using that little green double headed arrow in my picture above to make those aggregating filters work really effectively.
@Fang, Hi! I’d not really thought about it from a social network perspective but I agree that the most effective filters of complex information are people. I’m hoping to get machines to do the simple stuff more effectively as well. What I’m really dreaming about is an aggregator that notices that I should be reading papers by Professor X because his feed is aggregating data that is one step removed from the data that I am aggregating or searching for.
@Jean-Claude. I think you’ve hit the nail on the head actually. YOu certainly don’t want to see every molecule coming through on the feed. I would probably want to see the new molecules you’ve made, but perhaps someone else is interested in the molecules you are getting in. This is why the rich feed is so necessary. I agree at the moment that a google seach is perfectly capable of serving the person to person needs. Where I am thinking is the machine to machine or person through machine to other machines communication that you have often talked about. Using that little green double headed arrow in my picture above to make those aggregating filters work really effectively.
@Fang, Hi! I’d not really thought about it from a social network perspective but I agree that the most effective filters of complex information are people. I’m hoping to get machines to do the simple stuff more effectively as well. What I’m really dreaming about is an aggregator that notices that I should be reading papers by Professor X because his feed is aggregating data that is one step removed from the data that I am aggregating or searching for.
Very interesting thoughts. If you would like the feed tools, we can provide them to you. Let us know what you are missing.
Very interesting thoughts. If you would like the feed tools, we can provide them to you. Let us know what you are missing.
Ryan, I’m always interested in new feed tools. Obviously things have moved on a lot since this post but combinations of powerful filtering tools and easy plugins to existing sources of research information are what I am interested. The use cases are mostly around taking a very broad set of inputs and attempting to pull the important things out of them based on who they came from, what they are, what they are talking about, and whether any of my trusted friends have also flagged it.
Friendfeed has answered a lot of these questions but I’m interested in new approaches as well. Certainly no existing tool has all the answers.
Ryan, I’m always interested in new feed tools. Obviously things have moved on a lot since this post but combinations of powerful filtering tools and easy plugins to existing sources of research information are what I am interested. The use cases are mostly around taking a very broad set of inputs and attempting to pull the important things out of them based on who they came from, what they are, what they are talking about, and whether any of my trusted friends have also flagged it.
Friendfeed has answered a lot of these questions but I’m interested in new approaches as well. Certainly no existing tool has all the answers.